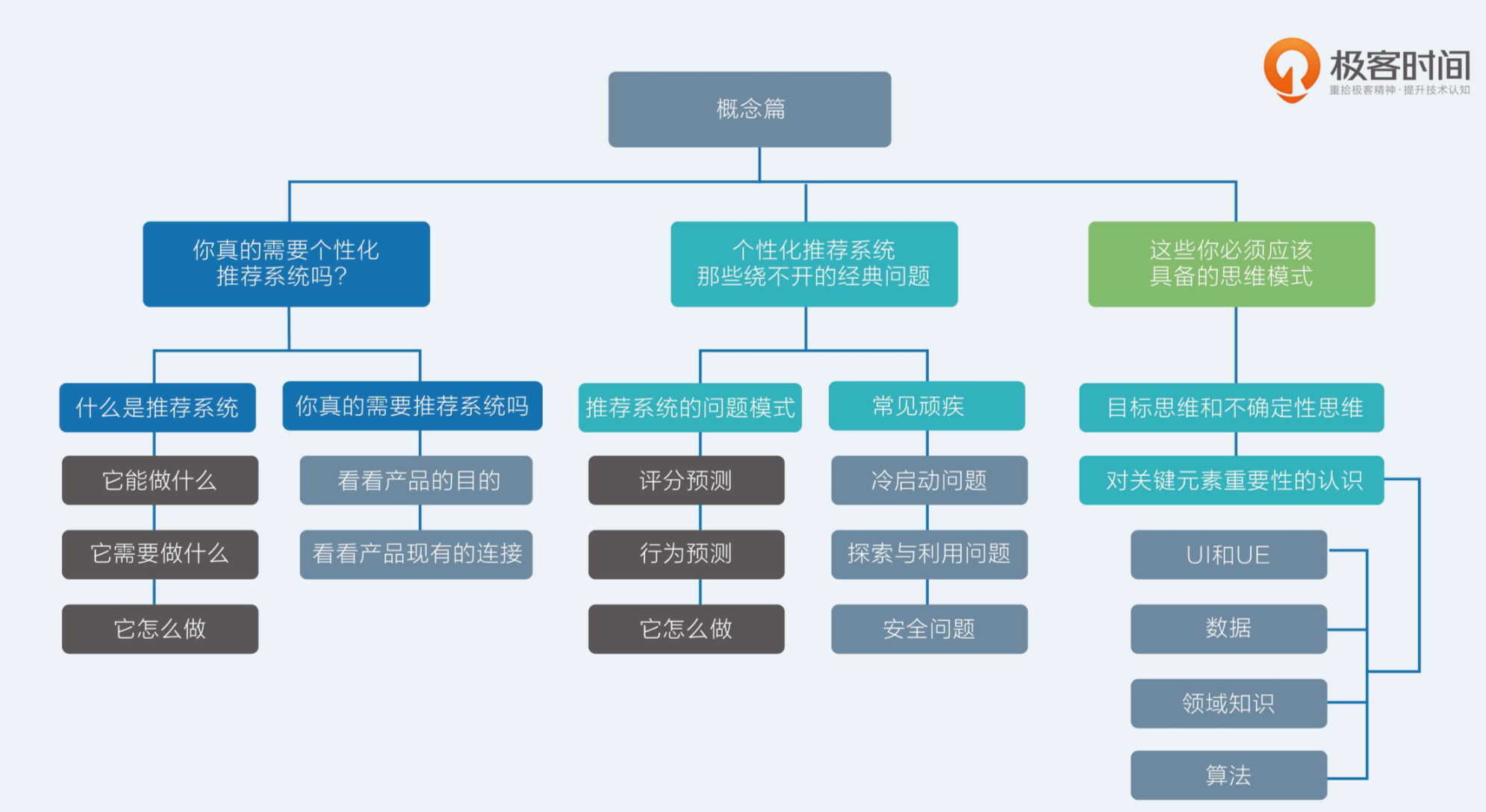
什么是推荐系统?
1. 能做什么?
找出 user 和 item 之间的联系、预测未来 user 和 item 可能出现的连接(产生了某种关系:比如用户点击、购买、评论了物品;或者用户某些属性和物品的属性一致 ...)
2. 需要什么?
需要已经存在的 user 和 item 之间的连接记录
3. 怎么做?
预测用户评分和偏好(机器推荐和人工推荐)
什么时候需要推荐系统?
1. 符合产品的目的。(比如工具类产品就肯定不需要,但社区类产品就需要)
2. 要看产品中 user 和 item 的情况。如果规模少到编辑推荐即可解决,就不需要;或者 user 的留存回访很低,也不需要(要有长尾效应才可能让推荐系统发挥效果)。
比如可以计算 Δconnection / (Δuser * Δitem),如果值较小,说明增加的连接数主要靠增加的活跃用户数和物品数贡献,不适合加入推荐;反之说明连接数已经有自发增长的趋势了,适合用推荐系统来加速。
推荐系统的问题模式
两大类:评分预测、行为预测。(因为评分和行为是用户对推荐结果的反馈)
所以不同推荐系统的任务也不同,有的直接去预测用户如果消费完之后会给多少评分;更多的是会分层,想要预测用户的行为。
评分预测:
提前预测一个用户对每个物品会打多少分,比如1~5分,然后找出那些他可能打高分但是还没消费的物品,推过去就好了
但怎么衡量预测分数和实际分数之间的误差呢?(机器学习模型的优化多是误差驱动)—— 其实就是个回归问题,用均方误差
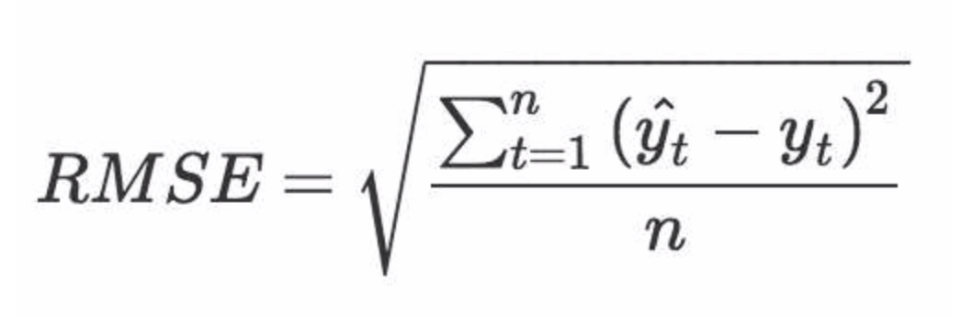
评分预测常见问题:
1. 数据不易收集,用户给出对一个物品给出评分,意味着他已经完成前面整个消费行为了
2. 数据质量难以保证,伪造评分数据容易、门槛低,但是获得真实评分数据又不易、门槛高
3. 评分分布不稳定,不同时期整体评分差别大,个人评分在不同时期也会变化,不同人之间评分标准差别也很大
所以评分这种数据,就是用户提供的显式反馈。但其实还存在隐式反馈,通常是各类用户行为,这就引出了下面一类问题
行为预测:
从用户登陆刷新,到购买收藏,这类自觉自愿产生的行为,一是数据量很大、二是相对真实。在整个消费流程中,用户行为(比如购买、建立社交关系、完整消费长内容)常呈漏斗关系,从登陆刷新开始,逐层经历流失。推荐系统就是要让完整的用户行为越多越好。
预测方式有两种:直接预测行为本身发生的概率(CTR 预估);预测物品的相对排序
隐式反馈相比显式反馈的优势:
1. 数据更加稠密(评分数据总体上很稀疏)
2. 更能代表用户的真实想法
3. 和模型的目标函数关联更密切,更容易在 AB 测试中和测试指标挂钩
行为预测常见问题:
1. 冷启动。新用户或者不活跃用户、新物品或展示次数较少的物品,相关数据较少、比较难做到有效推荐。要想办法从已有数据中主动学习
2. 探索与利用(EE 问题)。假设已经知道用户的喜好,比较科学的方式是大部分推荐他感兴趣的,小部分尝试去探索新的兴趣。如何平衡这两者就是要处理好的问题。
3. 安全问题。推荐系统被攻击的影响大致有:给出不靠谱的推荐结果;收集了脏数据,且一直持续留存影响;损失了商品的商业利益。所以针对推荐系统的攻防,也是需要讨论的问题。
推荐系统构成元素的相对重要性、思维模式
四个关键元素:1. UI 和 UE;2. 数据;3. 领域知识;4. 算法。重要性递减(算法其实反而不怎么重要?)
最先优化的一定是人机交互设计和用户体验设计,颜值即正义,交互逻辑要简洁明了;其次就是数据,没有历史数据积累,别的都是白扯;再来就是所处领域的常识和通识,比如电商产品普通用户更在意价格、新闻类产品必须更新很快、没必要给一个歌手的骨灰粉再推荐该歌手的歌...等等。最后才是算法的作用,各种算法原理也是一定要掌握的,算法的左右没那么大,但也不可或缺。
目标思维和不确定性思维
推荐系统是一个信息过滤系统,要解决的问题是如何让信息流通更有效率,追求指标的增长,背后思想强调是目标和不确定性:并不能很确定每个人将会看到什么,也不一定能复现一些操作。但只要能让目标指标增长即可。
输出值在增长就说明修改有效,继续沿着那个方向做下去,一旦无效或反作用就滚回去。
换句话说,要搞清楚做推荐系统的终极目标是什么。在这个过程中,量化就非常重要,推荐的精准性要量化,优化改进动作也要量化。
不用因果逻辑严丝合缝的推演,而用概率的眼光看待结果。为什么要有这种不确定思维?1. 大多数推荐算法本来就是概率视角;2. 追求的是不择手段增长目标,而不是纠结一两个case;3. 为个别问题修改模型,付出和收益比;4. 本来出现意外的推荐也可能是有益的(EE问题)