提示: 如果本文中add_graph的显示不正确(两个空白的方框),你可能需要参考我的环境配置:
- tensorflow版本:tensorflow-1.10.0-py3.6_cuda92_cudnn7_0; tensorboard版本:1.10.0;
- pytorch版本: pytorch-1.3.1-py3.6_cuda92_cudnn7_0; torchvision-0.4.1;
- tensorboardX: 2.0;(安装前面的两个软件之后,直接在base环境下
pip install tensorboardX即可.
在Anaconda Prompt中, pip list可以查看软件包和版本号;
pip install [软件包名]==[版本号] : 安装指定版本的软件包;
pip uninstall 软件包名 : 卸载某软件包;
原文地址: https://blog.csdn.net/bigbennyguo/article/details/87956434
什么是TensorboardX
Tensorboard 是 TensorFlow 的一个附加工具,可以记录训练过程的数字、图像等内容,以方便研究人员观察神经网络训练过程。可是对于 PyTorch 等其他神经网络训练框架并没有功能像 Tensorboard 一样全面的类似工具,一些已有的工具功能有限或使用起来比较困难 (tensorboard_logger, visdom等) 。TensorboardX 这个工具使得 TensorFlow 外的其他神经网络框架也可以使用到 Tensorboard 的便捷功能。TensorboardX 的 github仓库在这里。
TensorboardX 的文档相对详细,但大部分缺少相应的示例。本文是对TensorboardX 各项功能的完整介绍,每项都包含了示例,给出了可视化效果,希望可以方便大家的使用。笔者水平有限,还请读者们斧正,相关问题可以在留言区提出,我尽量解答。
配置TensorboardX
环境要求
- 操作系统:MacOS / Ubuntu (Windows未测试)
- Python2/3
- PyTorch >= 1.0.0 && torchvision >= 0.2.1 && tensorboard >= 1.12.0 1
以上版本要求你对应TensorboardX@1.6版本。为保证版本时效性,建议大家按照 TensorboardX github仓库中README 的要求进行环境配置。
安装
可以直接使用 pip 进行安装,或者从源码进行安装。
使用 pip 安装
pip install tensorboardX
从源码安装
git clone https://github.com/lanpa/tensorboardX && cd tensorboardX && python setup.py install
使用TensorboardX
首先,需要创建一个 SummaryWriter 的示例:
from tensorboardX import SummaryWriter
# Creates writer1 object.
# The log will be saved in 'runs/exp'
writer1 = SummaryWriter('runs/exp')
# Creates writer2 object with auto generated file name
# The log directory will be something like 'runs/Aug20-17-20-33'
writer2 = SummaryWriter()
# Creates writer3 object with auto generated file name, the comment will be appended to the filename.
# The log directory will be something like 'runs/Aug20-17-20-33-resnet'
writer3 = SummaryWriter(comment='resnet')
以上展示了三种初始化 SummaryWriter 的方法:
- 提供一个路径,将使用该路径来保存日志
- 无参数,默认将使用
runs/日期时间路径来保存日志 - 提供一个 comment 参数,将使用
runs/日期时间-comment路径来保存日志
一般来讲,我们对于每次实验新建一个路径不同的 SummaryWriter,也叫一个 run,如 runs/exp1、runs/exp2。
接下来,我们就可以调用 SummaryWriter 实例的各种 add_something 方法向日志中写入不同类型的数据了。想要在浏览器中查看可视化这些数据,只要在命令行中开启 tensorboard 即可:
tensorboard --logdir=<your_log_dir>
其中的 <your_log_dir> 既可以是单个 run 的路径,如上面 writer1 生成的 runs/exp;也可以是多个 run 的父目录,如 runs/ 下面可能会有很多的子文件夹,每个文件夹都代表了一次实验,我们令 --logdir=runs/ 就可以在 tensorboard 可视化界面中方便地横向比较 runs/ 下不同次实验所得数据的差异。
使用各种 add 方法记录数据
下面详细介绍 SummaryWriter 实例的各种数据记录方法,并提供相应的示例供参考。
数字 (scalar)
使用 add_scalar 方法来记录数字常量。
add_scalar(tag, scalar_value, global_step=None, walltime=None)
参数
- tag (string): 数据名称,不同名称的数据使用不同曲线展示
- scalar_value (float): 数字常量值
- global_step (int, optional): 训练的 step
- walltime (float, optional): 记录发生的时间,默认为
time.time()
需要注意,这里的 scalar_value 一定是 float 类型,如果是 PyTorch scalar tensor,则需要调用 .item() 方法获取其数值。我们一般会使用 add_scalar 方法来记录训练过程的 loss、accuracy、learning rate 等数值的变化,直观地监控训练过程。
Example
from tensorboardX import SummaryWriter
writer = SummaryWriter('runs/scalar_example')
for i in range(10):
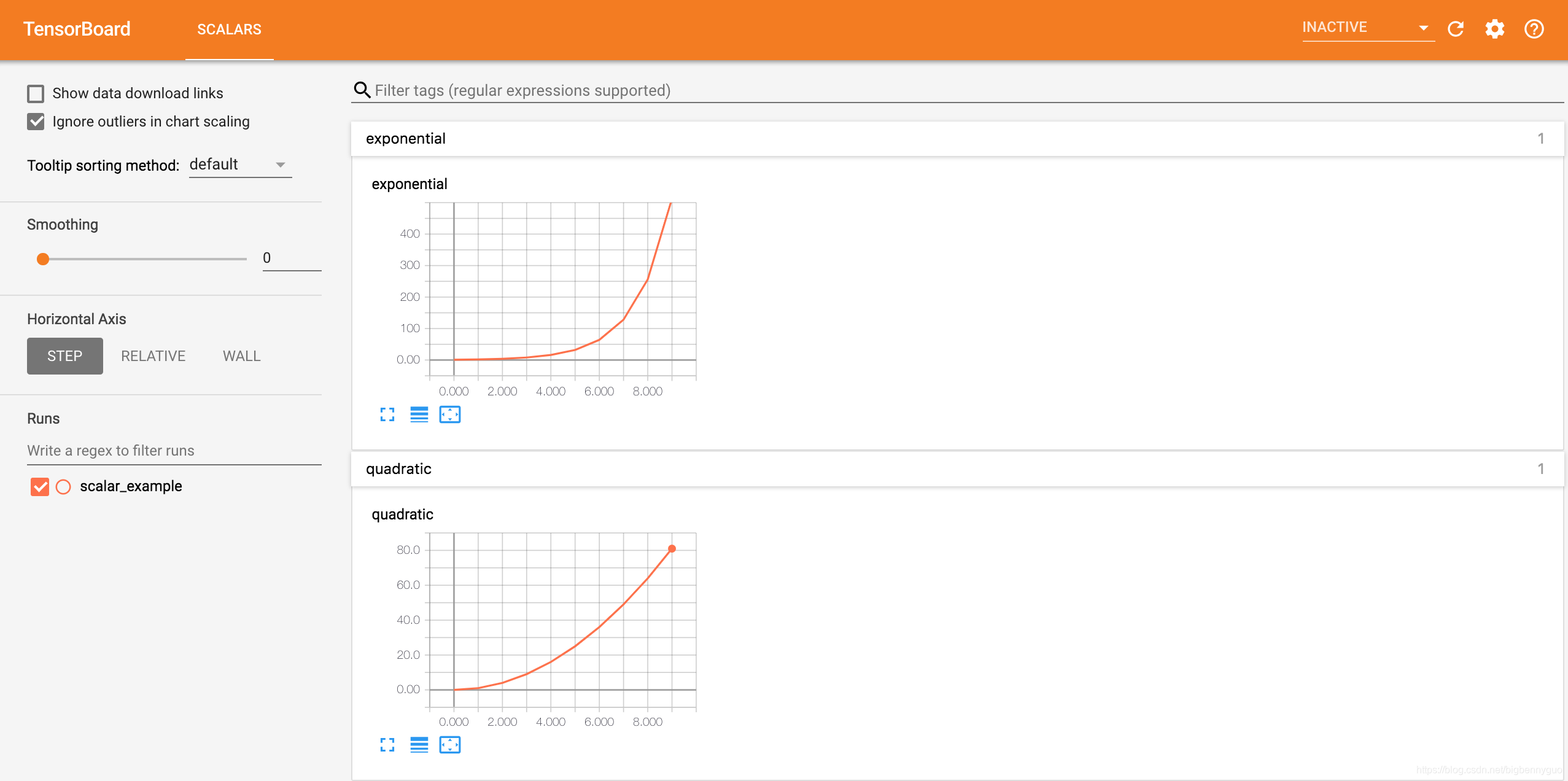
writer.add_scalar('quadratic', i**2, global_step=i)
writer.add_scalar('exponential', 2**i, global_step=i)
这里,我们在一个路径为 runs/scalar_example 的 run 中分别写入了二次函数数据 quadratic 和指数函数数据 exponential,在浏览器可视化界面中效果如下:
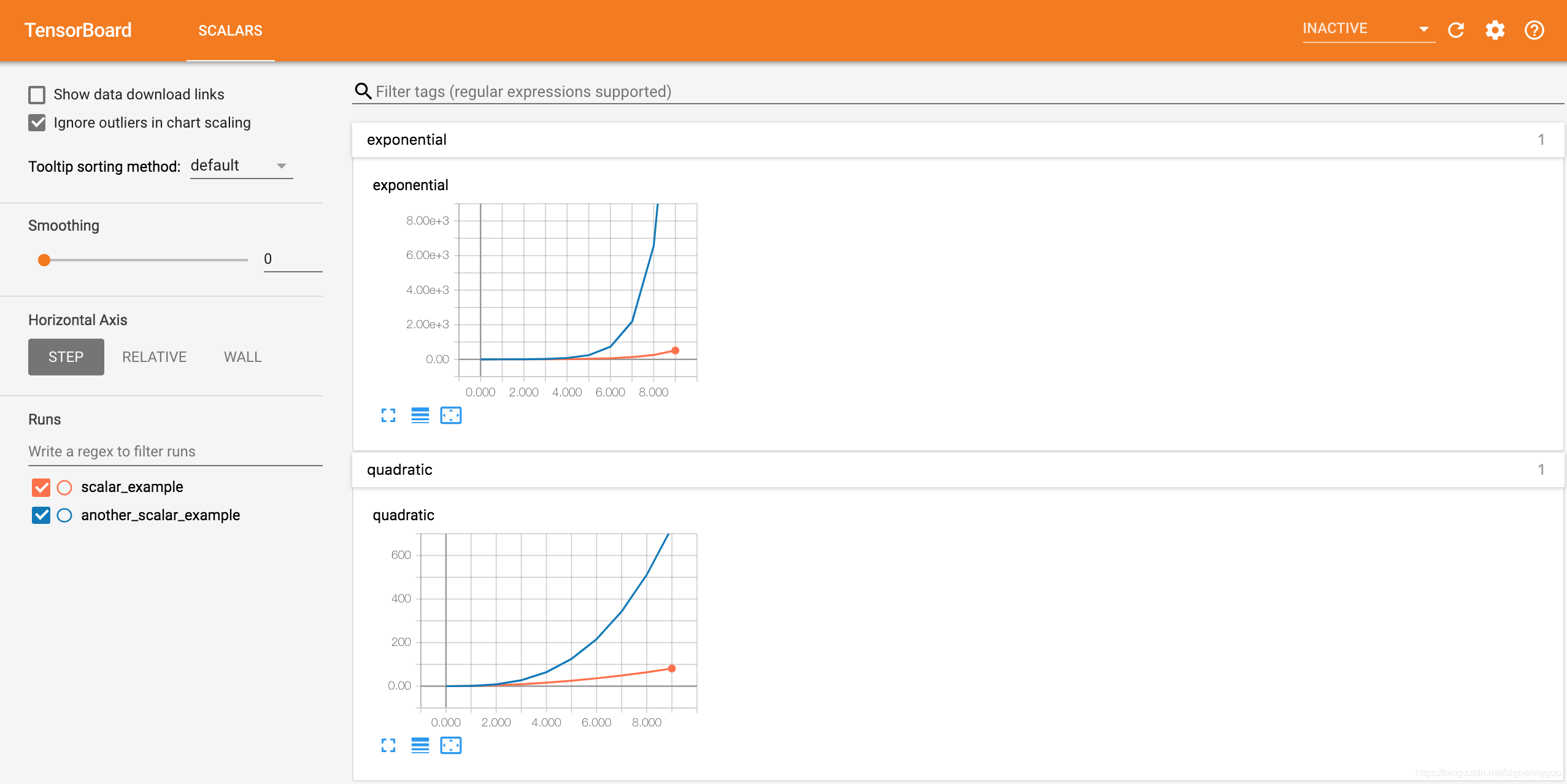
writer = SummaryWriter('runs/another_scalar_example')
for i in range(10):
writer.add_scalar('quadratic', i**3, global_step=i)
writer.add_scalar('exponential', 3**i, global_step=i)
接下来我们在另一个路径为 runs/another_scalar_example 的 run 中写入名称相同但参数不同的二次函数和指数函数数据,可视化效果如下。我们发现相同名称的量值被放在了同一张图表中展示,方便进行对比观察。同时,我们还可以在屏幕左侧的 runs 栏选择要查看哪些 run 的数据。
图片 (image)
使用 add_image 方法来记录单个图像数据。注意,该方法需要 pillow 库的支持。
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
参数
- tag (string): 数据名称
- img_tensor (torch.Tensor / numpy.array): 图像数据
- global_step (int, optional): 训练的 step
- walltime (float, optional): 记录发生的时间,默认为
time.time() - dataformats (string, optional): 图像数据的格式,默认为
'CHW',即Channel x Height x Width,还可以是'CHW'、'HWC'或'HW'等
我们一般会使用 add_image 来实时观察生成式模型的生成效果,或者可视化分割、目标检测的结果,帮助调试模型。
Example
from tensorboardX import SummaryWriter
import cv2 as cv
writer = SummaryWriter('runs/image_example')
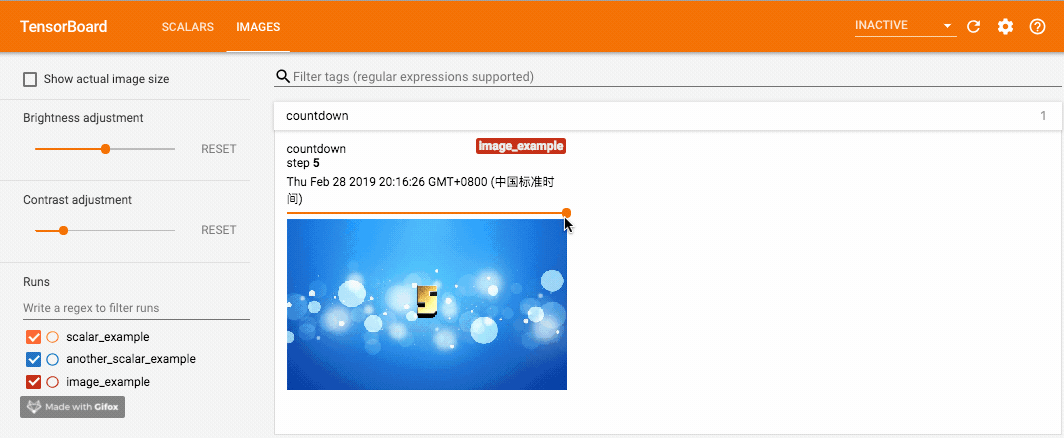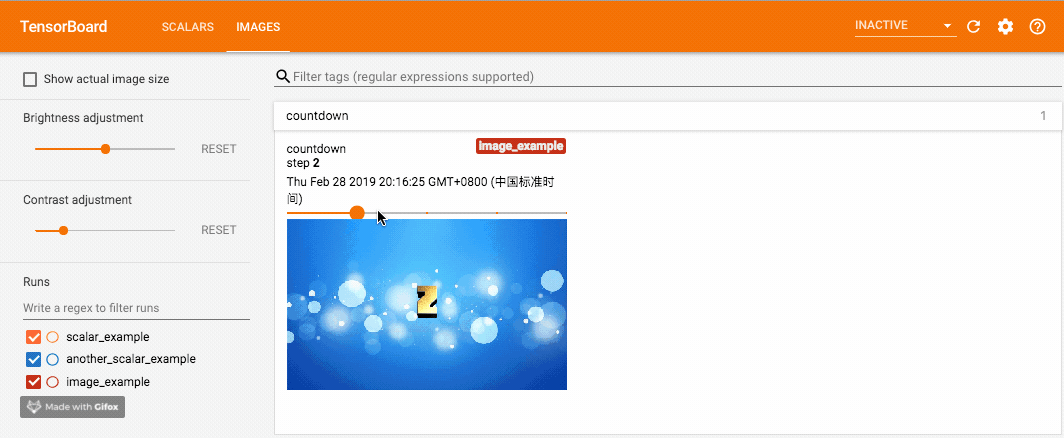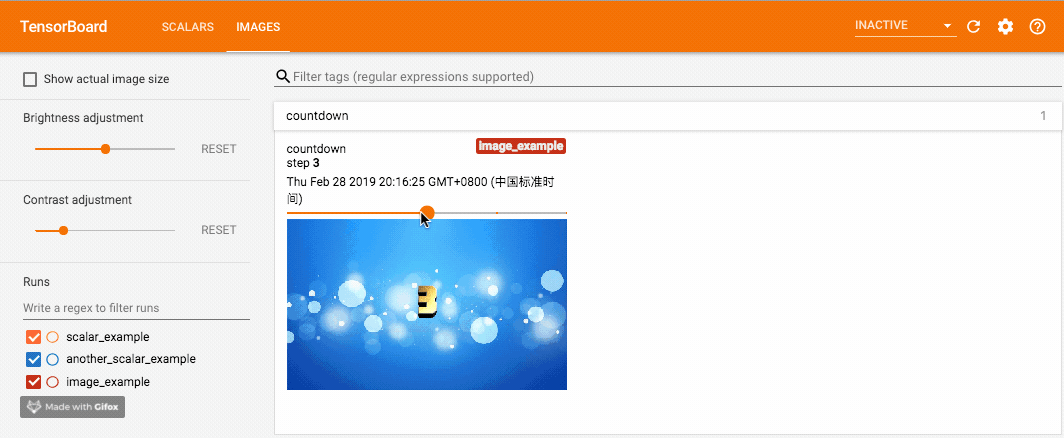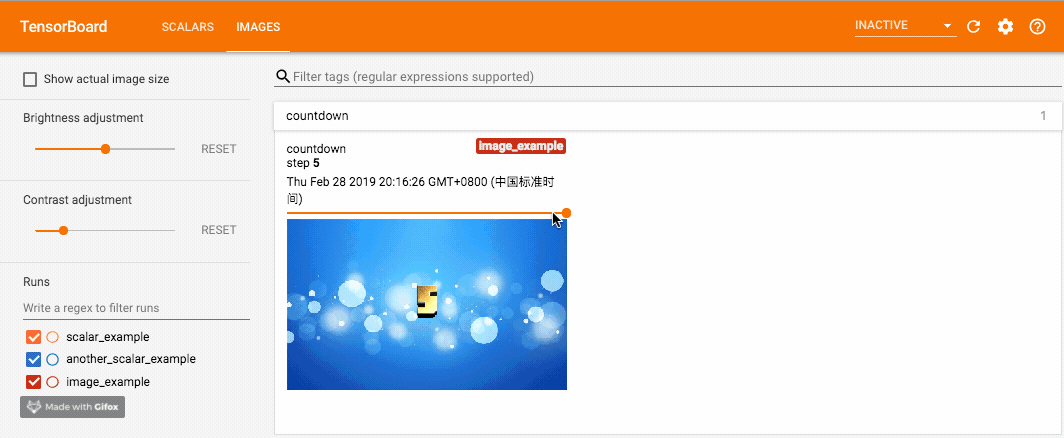
for i in range(1, 6):
writer.add_image('countdown',
cv.cvtColor(cv.imread('{}.jpg'.format(i)), cv.COLOR_BGR2RGB),
global_step=i,
dataformats='HWC')
这里我在 优一酷云字酷(朋友做的小工具,大家如果觉得文章有帮助也可以去多多支持一下)上做了几张带有数字的图片,分别使用 add_image 写入记录。这里我们使用 opencv 读入图片,opencv 读入的图片通道排列是 BGR,因此需要先转成 RGB 以保证颜色正确,并且 dataformats 设为 'HWC',而非默认的 'CHW'。调用这个方法一定要保证数据的格式正确,像 PyTorch Tensor 的格式就是默认的 'CHW'。效果如下,可以拖动滑动条来查看不同 global_step 下的图片:
add_image 方法只能一次插入一张图片。如果要一次性插入多张图片,有两种方法:
- 使用
torchvision中的make_grid方法 [官方文档] 将多张图片拼合成一张图片后,再调用add_image方法。 - 使用
SummaryWriter的add_images方法 [官方文档],参数和add_image类似,在此不再另行介绍。
直方图 (histogram)
使用 add_histogram 方法来记录一组数据的直方图。
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
参数
- tag (string): 数据名称
- values (torch.Tensor, numpy.array, or string/blobname): 用来构建直方图的数据
- global_step (int, optional): 训练的 step
- bins (string, optional): 取值有 ‘tensorflow’、‘auto’、‘fd’ 等, 该参数决定了分桶的方式,详见这里。
- walltime (float, optional): 记录发生的时间,默认为
time.time() - max_bins (int, optional): 最大分桶数
我们可以通过观察数据、训练参数、特征的直方图,了解到它们大致的分布情况,辅助神经网络的训练过程。
Example
from tensorboardX import SummaryWriter
import numpy as np
writer = SummaryWriter('runs/embedding_example')
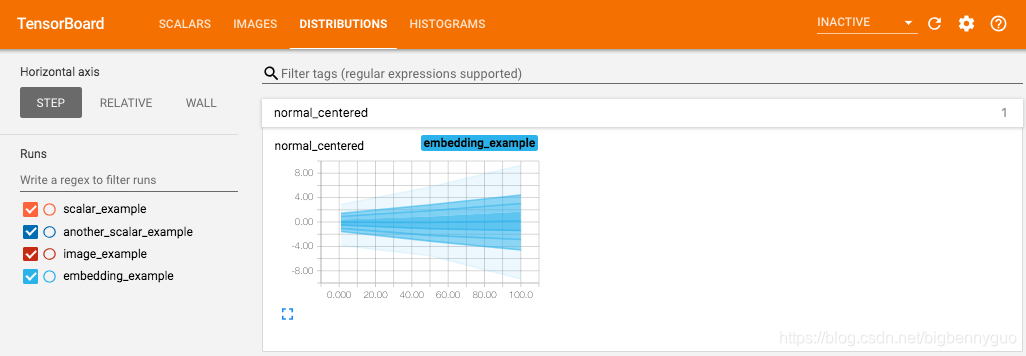
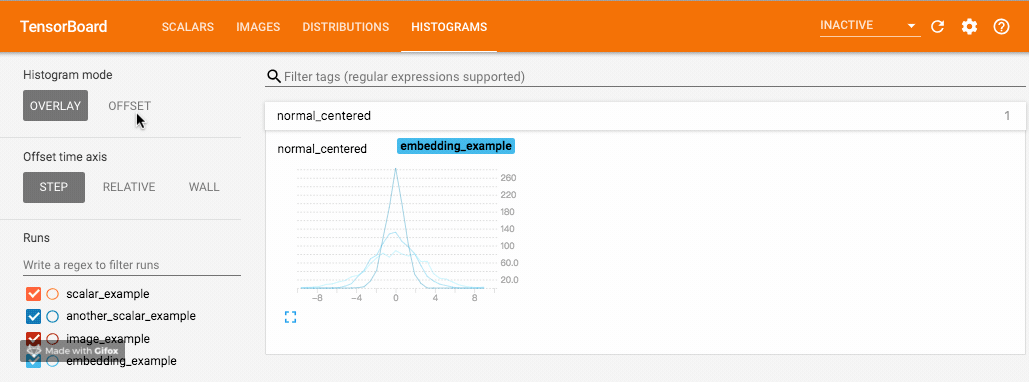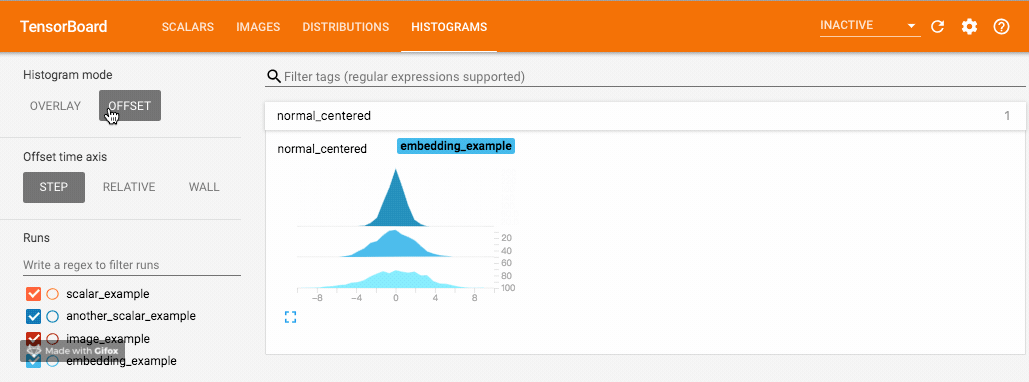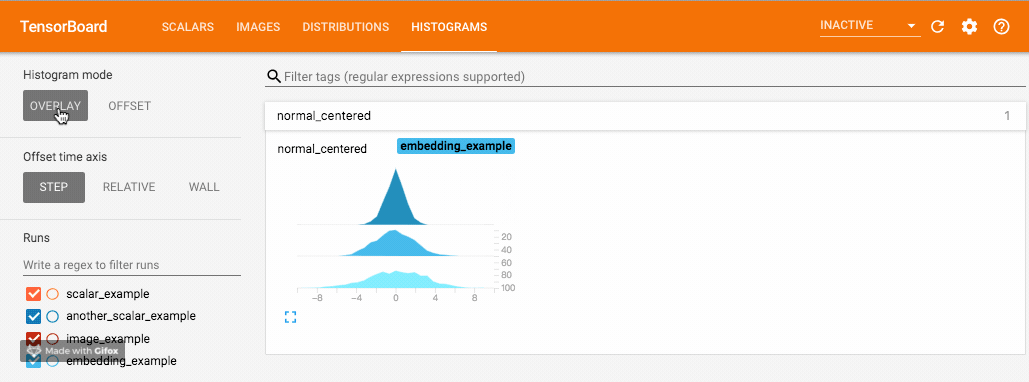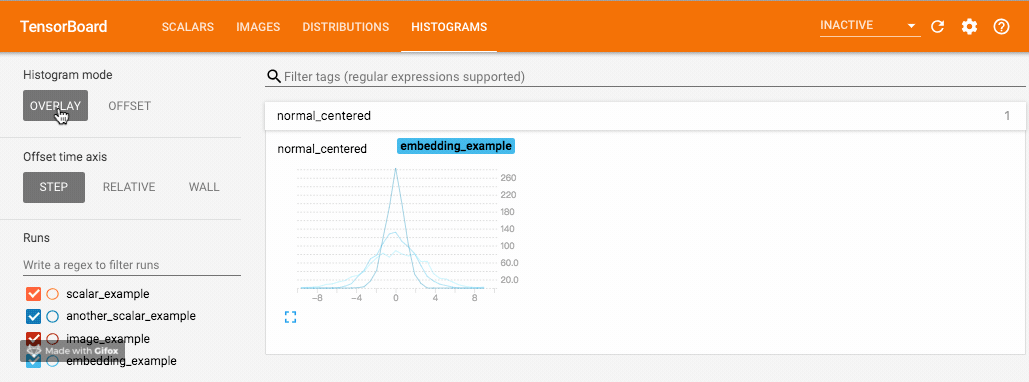
writer.add_histogram('normal_centered', np.random.normal(0, 1, 1000), global_step=1)
writer.add_histogram('normal_centered', np.random.normal(0, 2, 1000), global_step=50)
writer.add_histogram('normal_centered', np.random.normal(0, 3, 1000), global_step=100)
我们使用 numpy 从不同方差的正态分布中进行采样。打开浏览器可视化界面后,我们会发现多出了"DISTRIBUTIONS"和"HISTOGRAMS"两栏,它们都是用来观察数据分布的。其中在"HISTOGRAMS"中,同一数据不同 step 时候的直方图可以上下错位排布 (OFFSET) 也可重叠排布 (OVERLAY)。上下两图分别为"DISTRIBUTIONS"界面和"HISTOGRAMS"界面。
运行图 (graph)
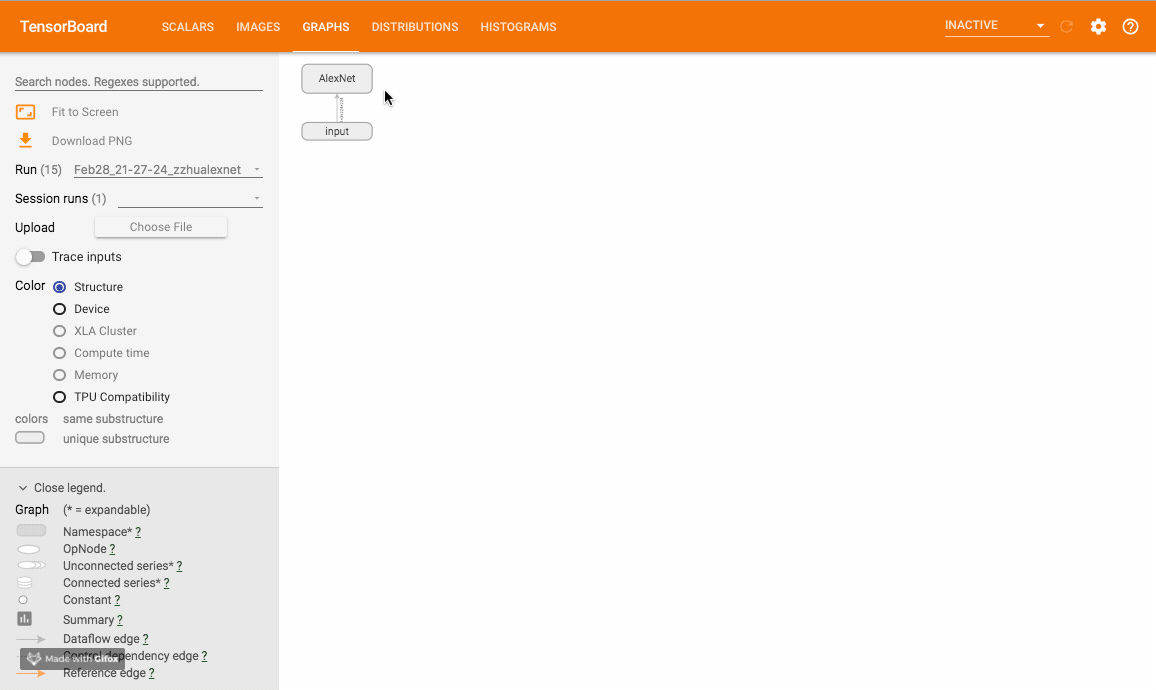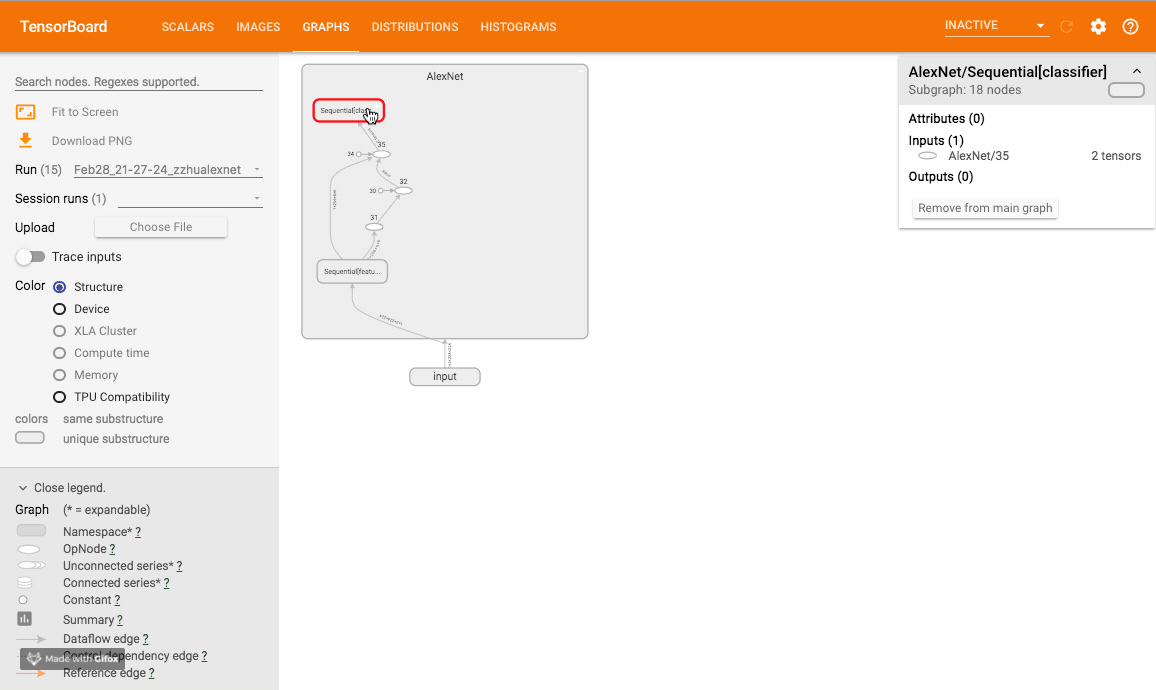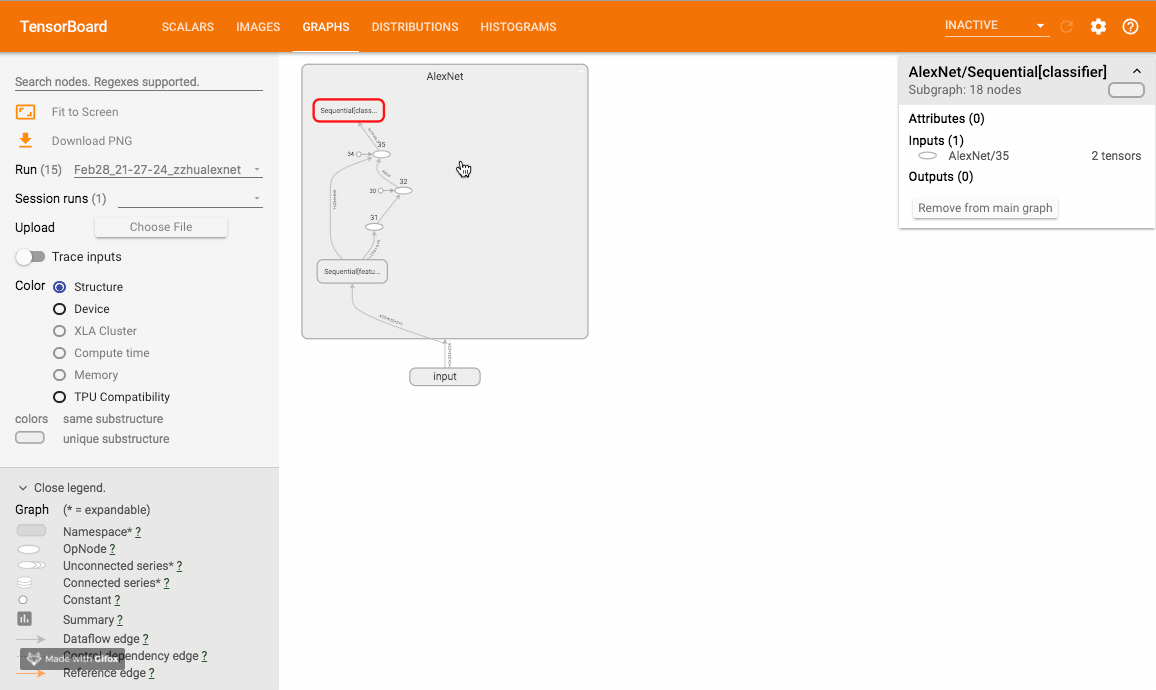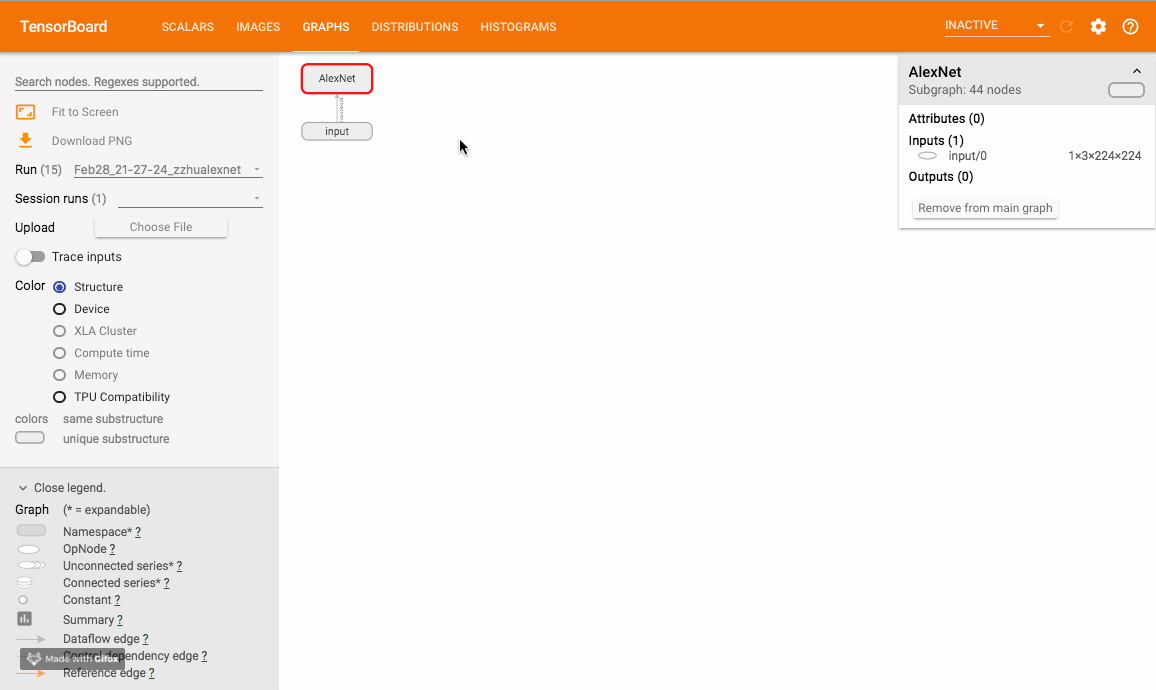
使用 add_graph 方法来可视化一个神经网络。
add_graph(model, input_to_model=None, verbose=False, **kwargs)
参数
- model (torch.nn.Module): 待可视化的网络模型
- input_to_model (torch.Tensor or list of torch.Tensor, optional): 待输入神经网络的变量或一组变量
该方法可以可视化神经网络模型,TensorboardX 给出了一个官方样例大家可以尝试。样例运行效果如下:
嵌入向量 (embedding)
使用 add_embedding 方法可以在二维或三维空间可视化 embedding 向量。
add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)
参数
- mat (torch.Tensor or numpy.array): 一个矩阵,每行代表特征空间的一个数据点
- metadata (list or torch.Tensor or numpy.array, optional): 一个一维列表,mat 中每行数据的 label,大小应和 mat 行数相同
- label_img (torch.Tensor, optional): 一个形如 NxCxHxW 的张量,对应 mat 每一行数据显示出的图像,N 应和 mat 行数相同
- global_step (int, optional): 训练的 step
- tag (string, optional): 数据名称,不同名称的数据将分别展示
add_embedding 是一个很实用的方法,不仅可以将高维特征使用PCA、t-SNE等方法降维至二维平面或三维空间显示,还可观察每一个数据点在降维前的特征空间的K近邻情况。下面例子中我们取 MNIST 训练集中的 100 个数据,将图像展成一维向量直接作为 embedding,使用 TensorboardX 可视化出来。
from tensorboardX import SummaryWriter
import torchvision
writer = SummaryWriter('runs/embedding_example')
mnist = torchvision.datasets.MNIST('mnist', download=True)
writer.add_embedding(
mnist.train_data.reshape((-1, 28 * 28))[:100,:],
metadata=mnist.train_labels[:100],
label_img = mnist.train_data[:100,:,:].reshape((-1, 1, 28, 28)).float() / 255,
global_step=0
)
采用 PCA 降维后在三维空间可视化效果如下:
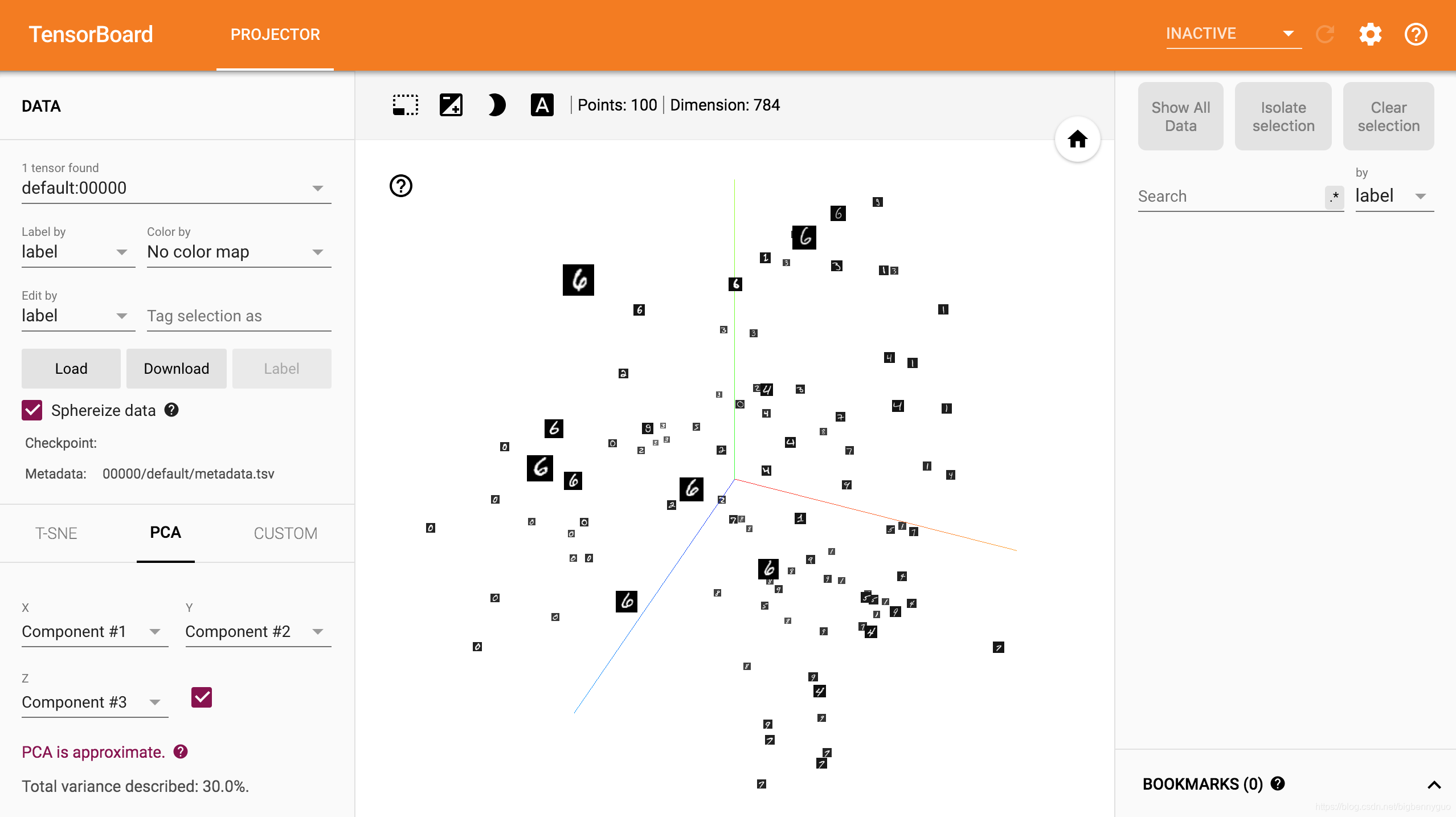
可以发现,虽然还没有做任何特征提取的工作,但 MNIST 的数据已经呈现出聚类的效果,相同数字之间距离更近一些(有没有想到 KNN 分类器)。我们还可以点击左下方的 T-SNE,用 t-SNE 的方法进行可视化。add_embedding 方法需要注意的几点:
mat是二维 MxN,metadata是一维 N,label_img是四维 NxCxHxW!label_img记得归一化为 0-1 之间的 float 值
其他
TensorboardX 除了上述的常用方法之外,还有许多其他方法如 add_audio、add_figure 等,感兴趣的朋友可以参考[官方文档]。相信读了这篇文章过后,你已经能够类比熟练调用其他的方法了。
一些tips
- 如果在进入 embedding 可视化界面时卡住,请更新 tensorboard 至最新版本 (>=1.12.0)。
- tensorboard 有缓存,如果进行了一些 run 文件夹的删除操作,最好重启 tensorboard,以避免无效数据干扰展示效果。
- 如果执行
add操作后没有实时在网页可视化界面看到效果,试试重启 tensorboard。
截至文章发稿时,对应TensorboardX@1.6版本。经笔者测试,若PyTorch版本<1.0.0或tensorboard版本<1.12.0,TensorboardX有部分功能无法正常使用,建议大家按照环境要求进行环境的配置或升级。 ↩︎