eventloop的基本概念可以参考:http://www.ruanyifeng.com/blog/2013/10/event_loop.html
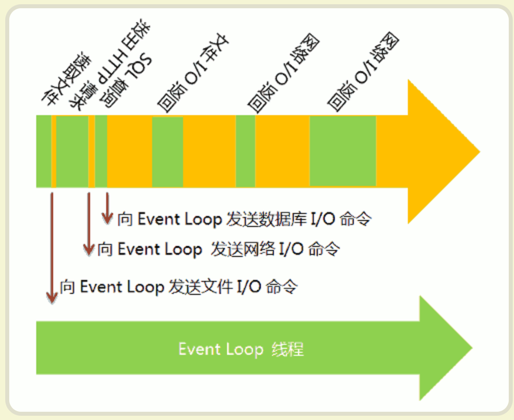
Eventloop指的是独立于主线程的一条线程,专门用来处理IO事件,而如果Eventloop一个不够用,可以开多个。 Eventloop底层也要基于异步的网络调用、文件调用才能发挥最大的作用。
可以看到,由于多出了橙色的空闲时间,所以主线程得以运行更多的任务,这就提高了效率。这种运行方式称为"异步模式"(asynchronous I/O)或"非堵塞模式"(non-blocking mode)。
Scala里面的Akka模式
http://blog.csdn.net/jmppok/article/details/17264495
里面用到了Future,
如果不使用Future:
def result = worker.sendRequestReply(o) //将消息发给worker actor
println "Worker Return----" + result
getContext().replyUnsafe(result) // 将worker返回的消息回复给客户端
这就成了同步处理(第一个消息处理完后才接收并处理第二个消息)。
如果在Future后调用了f1.await()或f1.get(),也成同步的了,因为await将等待worker返回后再继续往下执行。
http://www.ibm.com/developerworks/cn/java/j-jvmc5/
《JVM 并发性: 使用 Akka 执行异步操作》
主要解决了同步的问题
Actor 在执行上是单线程的(不超过 1 个线程执行一个特定的 actor 实例),所以邮箱充当着一个缓冲器,在处理消息前会一直保存这些消息。消息的不可变性(由于 JVM 的限制,目前未由 Akka 强制执行,但这是一项既定的要求)意味着根本无需担心可能影响 actor 之间各种共享的数据的同步问题;如果只有共享的数据是不可变的,那么根本不需要同步。
注意区分 actor模型和ACE reactor(反应堆)有什么异同?
参考这篇文章:http://spartan1.iteye.com/blog/1633430
actor模型参考维基百科定义(http://en.wikipedia.org/wiki/Actor_model):
actor是一个计算实体,当其收到消息时,可以并发执行如下操作:
1. 发送有限数量的消息给其他actor
2. 创建有限数量的新actor
3. 指定收到下一消息时的行为
ACE reactor是通过注册/回调方式进行驱动的程序开发模式,先注册自己关注什么事件,然后反应堆就会在该事件发生时回调你。这实际上与actor 模型有些类似。reactor在维基百科定义如下(http://en.wikipedia.org/wiki/Reactor_pattern):
reactor是一种设计模式,用于一到多个输入并发向一个服务处理器发送请求时进行事件处理。服务处理器将收到的请求同步分发到相应的请求处理器上。
按照定义,所有reactor系统都是单线程的,但可以应用到多线程环境中。reactor模型的特点是控制流反转(inversed flow of control)
proactor模型可以认为是reactor模型的一种异步实现,reactor要求收到请求后同步分发的请求处理器上,而proactor允许异步处理,定义(http://en.wikipedia.org/wiki/Proactor_pattern):
proactor也是事件处理的设计模式,在这种模式中,长时间运行的活动在单独的异步过程中处理,异步处理过程技术后,一个completion handler被调用。这个有些类似akka actor模型中,future对象的onComplete、onSuccess、onFailed方法。
proactor的ace实现(http://www.cs.wustl.edu/~schmidt/PDF/proactor.pdf)
reactor和proactor有什么异同:
我的这篇文章其实讲得很详细:http://www.cnblogs.com/charlesblc/p/6072827.html
里面提到的 http://www.artima.com/articles/io_design_patterns2.html 有如下描述:
Standard/classic Reactor:
- Step 1) wait for event (Reactor job)
- Step 2) dispatch "Ready-to-Read" event to user handler ( Reactor job)
- Step 3) read data (user handler job)
- Step 4) process data ( user handler job)
Proposed emulated Proactor:
- Step 1) wait for event (Proactor job)
- Step 2) read data (now Proactor job)
- Step 3) dispatch "Read-Completed" event to user handler (Proactor job)
- Step 4) process data (user handler job)
Netty 与 eventloop
https://my.oschina.net/andylucc/blog/618179
单线程Reactor模式
Netty线程模型总体上可以说是Reactor模式的一种变种
优缺点
Reactor模式使得应用代码和Reactor实现相分离,这使得用户可以将应用代码设计成最大程度可复用的模块,由于对于请求处理器的调用的是同步的,用户不需要去考虑并发问题,同时也减少了多线程对系统资源的消耗。
另一方面,相比于过程化模式的程序,Reactor模式下的程序相对比较难于Debug,同时单线程的设计在多核时代不能够充分利用多核处理器资源,影响了系统的扩展性。
EventLoopGroup提供next接口,可以总一组EventLoop里面按照一定规则获取其中一个EventLoop来处理任务。
在Netty的EventLoop线程中,这个线程主要需要处理IO事件和其他两种任务,分别为定时任务和一般任务。
Netty提供可一个参数ioRatio用于用户调整单线程对于IO处理时间和任务处理时间的分配的比率。这样根据实际应用场景用户可以对这个值进行调整,默认值是50,也就是这个线程会将处理IO的时间和处理任务的时间控制为1:1。
final long ioStartTime = System.nanoTime(); processSelectedKeys();//处理IO事件 final long ioTime = System.nanoTime() - ioStartTime;//处理IO事件的时间 runAllTasks(ioTime * (100 - ioRatio) / ioRatio);//计算用于处理任务的时间
要记住,回调是不会自动插入执行的。是需要“轮询”或者“提取”执行的。
关于IO密集型和CPU密集型的思考
Netty基于单线程设计的EventLoop能够同时处理成千上万的客户端连接的IO事件,缺点是单线程不能够处理时间过长的任务,这样会阻塞使得IO事件的处理被阻塞,严重的时候回造成IO事件堆积,服务不能够高效响应客户端请求。所谓时间过长的任务通常是占用CPU资源比较长的任务,也即CPU密集型,对于业务应用也可能是业务代码的耗时。这点和Node是极其相似的,我可以认为这是基于单线程的EventLoop模型的通病,我们不能够将过长的任务交给这个单线程来处理,也就是不适合CPU密集型应用。
那么问题怎么解决呢,参照Node的解决方案,当我们遇到需要处理时间很长的任务的时候,我们可以将它交给子线程来处理,主线程继续去EventLoop,当子线程计算完毕再讲结果交给主线程。这也是通常基于Netty的应用的解决方案,通常业务代码执行时间比较长,我们不能够把业务逻辑交给这个单线程来处理,因此我们需要额外的线程池来分配线程资源来专门处理耗时较长的业务逻辑,这是比较通用的设计方案。
换句话说,利用有限的线程,来充分利用多核的优势。
Java线程模型的演进 & Netty线程模型
单线程
多线程:由于JDK1.4并没有提供类似线程池这样的线程管理容器,多线程之间的同步、协作、创建和销毁等工作都需要用户自己实现。由于创建和销毁线程是个相对比较重量级的操作,因此,这种原始的多线程编程效率和性能都不高。
1.1.3. 线程池
JDK1.5推出了java.util.concurrent并发编程包。在并发编程类库中,提供了线程池、线程安全容器、原子类等新的类库,极大的提升了Java多线程编程的效率,降低了开发难度。
从JDK1.5开始,基于线程池的并发编程已经成为Java多核编程的主流。
1.2. Reactor模型
无论是C++还是Java编写的网络框架,大多数都是基于Reactor模式进行设计和开发,Reactor模式基于事件驱动,特别适合处理海量的I/O事件。
千万注意了,上面提到了特别适合IO事件。
1.2.1. 单线程模型
Reactor单线程模型,指的是所有的IO操作都在同一个NIO线程上面完成
由于Reactor模式使用的是异步非阻塞IO,所有的IO操作都不会导致阻塞,理论上一个线程可以独立处理所有IO相关的操作。
但是对于高负载、大并发的应用场景却不合适,主要原因如下:
1)可靠性问题:一旦NIO线程意外跑飞,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障。
2)主线程负担过重。收包、解码、编码、发包也要占用CPU。
1.2.2. 多线程模型
Rector多线程模型与单线程模型最大的区别就是有一组NIO线程处理IO操作,它的原理图如下:
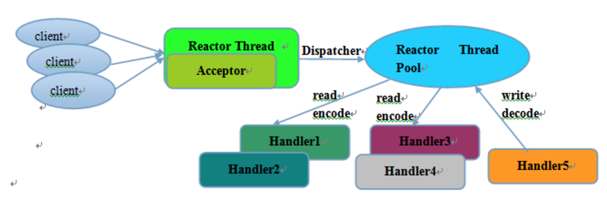
1)有专门一个NIO线程-Acceptor线程用于监听服务端,接收客户端的TCP连接请求;
2)网络IO操作-读、写等由一个NIO线程池负责,线程池可以采用标准的JDK线程池实现,它包含一个任务队列和N个可用的线程,由这些NIO线程负责消息的读取、解码、编码和发送;
3)1个NIO线程可以同时处理N条链路,但是1个链路只对应1个NIO线程,防止发生并发操作问题。
1.2.3. 主从多线程模型
并发百万客户端连接,或者服务端需要对客户端握手进行安全认证,但是认证本身非常损耗性能。在这类场景下,单独一个Acceptor线程可能会存在性能不足问题,为了解决性能问题,产生了第三种Reactor线程模型-主从Reactor多线程模型。
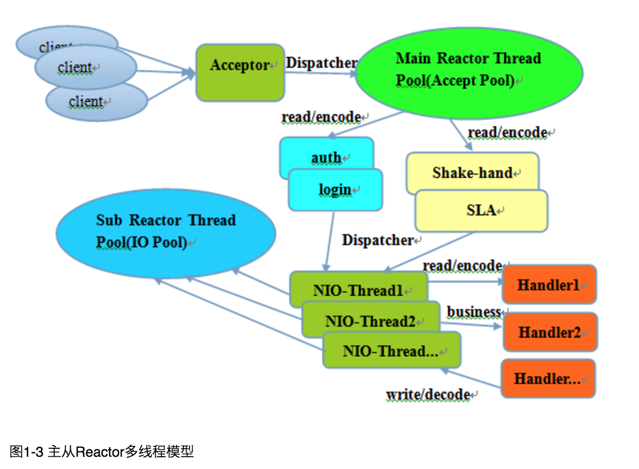
它的工作流程总结如下:
- 从主线程池中随机选择一个Reactor线程作为Acceptor线程,用于绑定监听端口,接收客户端连接;
- Acceptor线程接收客户端连接请求之后创建新的SocketChannel,将其注册到主线程池的其它Reactor线程上,由其负责接入认证、IP黑白名单过滤、握手等操作;
- 步骤2完成之后,业务层的链路正式建立,将SocketChannel从主线程池的Reactor线程的多路复用器上摘除,重新注册到Sub线程池的线程上,用于处理I/O的读写操作。
上面这个流程,看起来,跟Netty 的 BossEventLoopPool 和 SubEventLoopPool就很像了。
后面还有一些Netty实现的细节。
比如NioEventloop就是Netty里面代替线程的东东,它里面执行handler都是串行的。
再比如实现Timer所用的时间轮:
可以看出定时轮由个3个重要的属性参数:ticksPerWheel(一轮的tick数),tickDuration(一个tick的持续时间)以及 timeUnit(时间单位),例如当ticksPerWheel=60,tickDuration=1,timeUnit=秒,这就和时钟的秒针走动完全类似了。
从定时任务Task队列中弹出delay最小的Task,计算超时时间。
定时任务的执行:经过周期tick之后,扫描定时任务列表,将超时的定时任务移除到普通任务队列中,等待执行
为了保证定时任务的执行不会因为过度挤占IO事件的处理,Netty提供了IO执行比例供用户设置,用户可以设置分配给IO的执行比例,防止因为海量定时任务的执行导致IO处理超时或者积压。
2.3.3. 聚焦而不是膨胀
合理的设计模式是Netty只负责提供和管理NIO线程,其它的业务层线程模型由用户自己集成,Netty不应该提供此类功能,只要将分层划分清楚,就会更有利于用户集成和扩展。