HBase 为用户提供了一个非常方便的使用方式, 我们称之为“HBase Shell”。
HBase Shell 提供了大多数的 HBase 命令, 通过 HBase Shell 用户可以方便地创建、删除及修改表, 还可以向表中添加数据、列出表中的相关信息等。
备注:写错 HBase Shell 命令时用键盘上的“Delete”进行删除,“Backspace”不起作用。
在启动 HBase 之后,用户可以通过下面的命令进入 HBase Shell 之中,命令如下所示:
hadoop@ubuntu:~$ hbase shell HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0.94.3, r1408904, Wed Nov 14 19:55:11 UTC 2012 hbase(main):001:0>
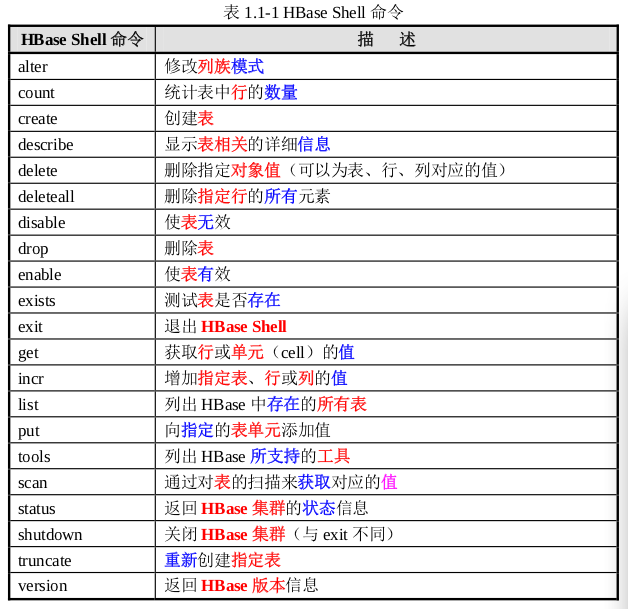
具体的 HBase Shell 命令如下表 1.1-1 所示:
下面我们将以“一个学生成绩表”的例子来详细介绍常用的 HBase 命令及其使用方法。

这里 grad 对于表来说是一个列,course 对于表来说是一个列族,这个列族由三个列组成 china、math 和 english,当然我们可以根据我们的需要在 course 中建立更多的列族,如computer,physics 等相应的列添加入 course 列族。(备注:列族下面的列也是可以没有名字的。)
1). create 命令
创建一个具有两个列族“grad”和“course”的表“scores”。其中表名、行和列都要用单引号括起来,并以逗号隔开。
hbase(main):012:0> create 'scores', 'name', 'grad', 'course'
2). list 命令
查看当前 HBase 中具有哪些表。
hbase(main):012:0> list
3). describe 命令
查看表“scores”的构造。
hbase(main):012:0> describe 'scores'
4). put 命令
使用 put 命令向表中插入数据,参数分别为表名、行名、列名和值,其中列名前需要列族最为前缀,时间戳由系统自动生成。
格式: put 表名,行名,列名([列族:列名]),值
例子:
a. 加入一行数据,行名称为“xiapi”,列族“grad”的列名为”(空字符串)”,值位 1。
hbase(main):012:0> put 'scores', 'xiapi', 'grad:', '1'
hbase(main):012:0> put 'scores', 'xiapi', 'grad:', '2' --修改操作(update)
b. 给“xiapi”这一行的数据的列族“course”添加一列“<china,97>”。
hbase(main):012:0> put 'scores', 'xiapi', 'course:china', '97'
hbase(main):012:0> put 'scores', 'xiapi', 'course:math', '128'
hbase(main):012:0> put 'scores', 'xiapi', 'course:english', '85'
5). get 命令
a.查看表“scores”中的行“xiapi”的相关数据。
hbase(main):012:0> get 'scores', 'xiapi'
b.查看表“scores”中行“xiapi”列“course :math”的值。
hbase(main):012:0> get 'scores', 'xiapi', 'course :math'
或者
hbase(main):012:0> get 'scores', 'xiapi', {COLUMN=>'course:math'}
hbase(main):012:0> get 'scores', 'xiapi', {COLUMNS=>'course:math'}
备注:COLUMN 和 COLUMNS 是不同的,scan 操作中的 COLUMNS 指定的是表的列族, get操作中的 COLUMN 指定的是特定的列,COLUMNS 的值实质上为“列族:列修饰符”。COLUMN 和 COLUMNS 必须为大写。
6). scan 命令
a. 查看表“scores”中的所有数据。
hbase(main):012:0> scan 'scores'
注意:
scan 命令可以指定 startrow,stoprow 来 scan 多个 row。
例如:
scan 'user_test',{COLUMNS =>'info:username',LIMIT =>10, STARTROW => 'test', STOPROW=>'test2'}
b.查看表“scores”中列族“course”的所有数据。
hbase(main):012:0> scan 'scores', {COLUMN => 'grad'}
hbase(main):012:0> scan 'scores', {COLUMN=>'course:math'}
hbase(main):012:0> scan 'scores', {COLUMNS => 'course'}
hbase(main):012:0> scan 'scores', {COLUMNS => 'course'}
7). count 命令
hbase(main):068:0> count 'scores'
8). exists 命令
hbase(main):071:0> exists 'scores'
9). incr 命令(赋值)
10). delete 命令
删除表“scores”中行为“xiaoxue”, 列族“course”中的“math”。
hbase(main):012:0> delete 'scores', 'xiapi', 'course:math'
11). truncate 命令
hbase(main):012:0> truncate 'scores'
12). disbale、drop 命令
通过“disable”和“drop”命令删除“scores”表。
hbase(main):012:0> disable 'scores' --enable 'scores'
hbase(main):012:0> drop 'scores'
13). status命令
hbase(main):072:0> status
14). version命令
hbase(main):073:0> version
另外,在 shell 中,常量不需要用引号引起来,但二进制的值需要双引号引起来,而其他值则用单引号引起来。HBase Shell 的常量可以通过在 shell 中输入“Object.constants”。
引言
HBase提供了丰富的访问接口。
• HBase Shell
• Java clietn API
• Jython、Groovy DSL、Scala
• REST
• Thrift(Ruby、Python、Perl、C++…)
• MapReduce
• Hive/Pig
其中HBase Shell是常用的便捷方式
首先你需要一个HBase的环境,如果需要自己搭建可以参考http://hbase.apache.org/book/quickstart.html 和http://hbase.apache.org/book/notsoquick.html。
如果你在windows环境下配置cygwin及ssh遇到问题可以参考 http://qa.taobao.com/?p=10633。
进入HBase shell控制台
>bin/hbase shell
输入“help”可以快速扫描下支持那些命令。
创建表
> create 'blog','article','author'
知识点回顾:Column Family是schema的一部分,而Column不是。这里的article和author是Column Family。
查询所有表
>list

增加记录
>put 'blog','1','article:title,' Head First HBase '
>put 'blog','1','article:content','HBase is the Hadoop database. Use it when you need random, realtime read/write access to your Big Data.'
> put 'blog','1','article:tags','Hadoop,HBase,NoSQL'
> put 'blog','1','author:name','hujinjun'
> put 'blog','1','author:nickname',’一叶渡江’
知识点回顾:Column完全动态扩展,每行可以有不同的Columns。
根据RowKey查询
> get 'blog','1'

知识点回顾:HTable按RowKey字典序(1,10,100,11,2)自动排序,每行包含任意数量
的Columns,Columns按ColumnKey(article:content,article:tags,article:title,author:name,author:nickname)自动排序
查询列族
>get 'blog','1','author

查看表内容
>scan 'blog'

更新练习
- 查询下更新前的值:
> get ‘blog’,’1’,’author:nickname’

- 更新nickname为’yedu’:
> put ‘blog’,’1’,’ahthor:nickname’,’yedu’
- 查询更新后的结果:
> get ‘blog’,’1’,’author:nickname’

知识点回顾:查询默认返回最近的值。
- 查询nickname的多个(本示例为2个)版本值
> get 'blog','1',{COLUMN => 'author:nickname',VERSIONS => 2}

知识点回顾:每个Column可以有任意数量的Values,按Timestamp倒序自动排序。
当修改多次(大于3次,修改2次时也就有3个VERSIONS)时:VERSIONS默认最高为3
> get 'blog','1',{COLUMN => 'author:nickname',VERSIONS => 4}

- 如何只查询到以前的旧版本呢,需要借助Timestamp
>get 'blog','1',{COLUMN => 'author:nickname', TIMESTAMP => 1333690828877}
知识点回顾:TabelName+RowKey+Column+Timestamp=>Value
删除记录
- delete只能删除一个column
>delete 'blog','1','author:nickname'
- 删除RowKey的所有column用deleteall
>deleteall ‘blog’,’1’
删除表
练习完毕,把练习表删了吧,删除之前需要先disable
>disable ‘blog’
>drop ‘blog’
小结
本文演示了通过HBase shell创建、删除表及对记录的增删改查,可以参照操作结果对回顾的知识点进一步理解掌握,在本系列下一篇文章中讲演示如何通过Java api来与HBase交互。