以前的只是简单了解过,爬虫一直对移动端做得少,今天在一前辈任务下用到了,不得不说不得不爱。
熟话说:好记性不如烂笔头,这里做一下浅薄的笔记。
摘要: mitmproxy是一个支持HTTP和HTTPS的抓包程序,有类似Fiddler、Charles的功能,只不过它是一个控制台的形式操作。 mitmproxy还有两个关联组件。一个是mitmdump,它是mitmproxy的命令行接口,利用它我们可以对接Python脚本,用Python实现监听后的处理。
mitmproxy是一个支持HTTP和HTTPS的抓包程序,有类似Fiddler、Charles的功能,只不过它是一个控制台的形式操作。
mitmproxy还有两个关联组件。一个是mitmdump,它是mitmproxy的命令行接口,利用它我们可以对接Python脚本,用Python实现监听后的处理。另一个是mitmweb,它是一个Web程序,通过它我们可以清楚观察mitmproxy捕获的请求。
一。下载
1.1环境
python3、mitmproxy、appium、adb、iphone一台
1.2
安装方法很多这里只做简单介绍,出问题可以自行google。
pip install mitmproxy#安装很简单,个人喜欢放在虚拟环境里
这时候你要在移动端下载安装好CA证书(ios最好用自带浏览器),并且mac要和手机处于同一个局域网and端口下,这样手机的包才会被mac抓到。
注意:你还可能出现ios浏览器可以联网,而app失败的情况,你需要去setting > general trust 证书。
二。抓包原理
mitmproxy运行在PC上,mitmproxy会在PC的8080端口运行,开启一个代理服务,这个服务实际上是HTTP/HTTPS的代理。手机和PC在同一局域网内,设置代理为mitmproxy的代理地址,手机访问互联网会经过mitmproxy。mitmproxy起到了中间人的作用,抓取所有的Request和Reponse。
这个过程可以对接mitmdump,抓取到的Request和Response的内容直接用Python处理。
三。简单使用
1.1设置代理
启动mitmproxy
在terminal里输入命令:mitmproxy,会在8080(右下角监听端口)端口运行一个代理服务。

启动mitmdump,它也会监听8080端口,命令如下所示:
mitmdump
这时候你只需要在手机上任意打开app或浏览器,terminal页面便会呈现所有请求:
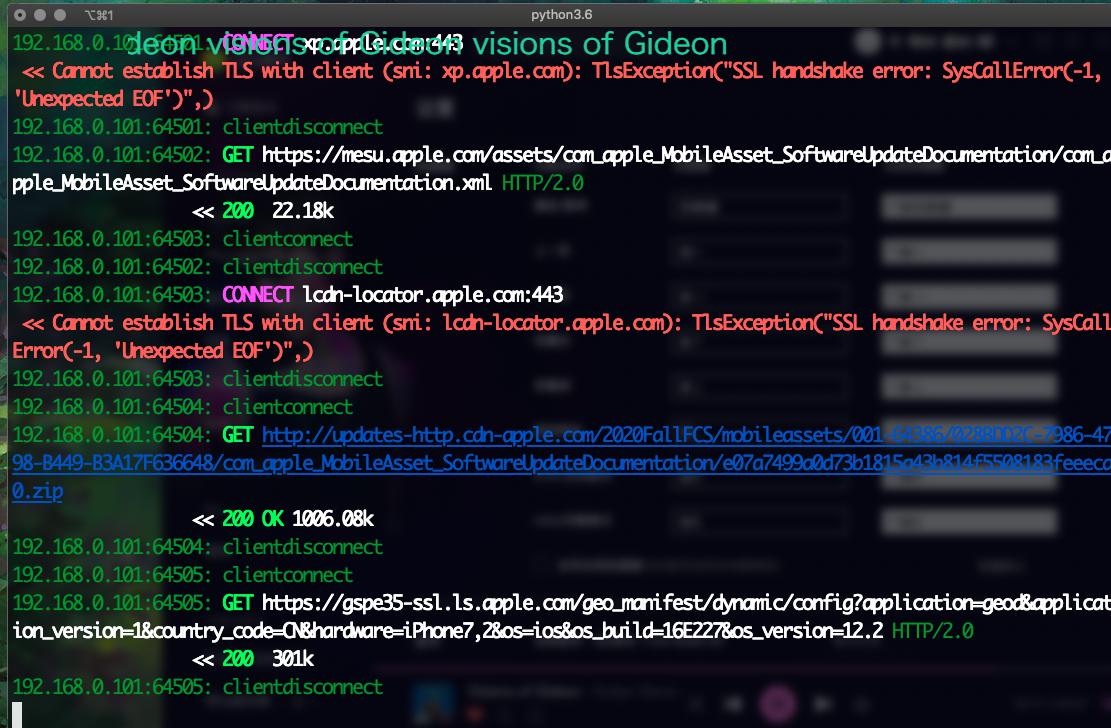
在mitmproxy命令下,会呈现三个分类 : Request Response Detail
可自行查看内容
当然如果你觉得终端看起来太费劲,你也可以在浏览器里查看 ,命令如下:
mitmweb

这就相当于之前我们在浏览器开发者工具监听到的浏览器请求,在这里我们借助于mitmproxy完成。Charles完全也可以做到。
这里是刚才手机打开页面时的所有请求列表,左下角显示的x/xx代表一共发生了xx个请求,当前箭头所指的是第x个请求。
他的优越性之一在于还可以结合python,我们只要写好请求和处理逻辑如:数据的解析,过滤,存储,就摆脱手动截取和分析响应了,方便了一步。
它的常用命令如下:
mitmdump -w example.csv #example.csv 自定义
指定python文件处理请求和响应:
mitmdump -s doing.py #要指定文件绝对路径,建议到当前文件夹执行
1.2例子
1。
#这里必须写flow,规定格式
def request(flow): flow.request.headers['User-Agent'] ='MitmProxy' print(flow.request.headers)
2.
def paser(flow): ditail_url='XXXXXXX' if flow.request.url.startswich(detail_url): res = flow.response.text data = json.loads(res) analsys(data) def analsys(data): pass
每个请求和响应都会进过该.py,就可以对你需要的url做一个简单过滤判断,对数据进一步操作(有点像中间件的作用)。
3.
from mitmproxy import ctx def request(flow): flow.request.headers['User-Agent'] ='MitmProxy' ctx.log.info(str(flow.request.headers)) ctx.log.warn(str(flow.request.headers)) ctx.log.error(str(flow.request.headers))
四。appium环境
前面对后续的请求和响应做了简单处理,但是总归人为对真机操作,量一大就会不方便了,而下面的appium就这时候加入进来了
appium的安装就偷个懒。。嘿嘿
安卓:https://blog.csdn.net/weixin_43095131/article/details/106555615
tools/android update sdk --no-ui #sdk 安装命令
ios:https://www.cnblogs.com/May-study/p/10900188.html
https://www.cnblogs.com/dreamhighqiu/p/10989962.html(推荐)
综合:https://cuiqingcai.com/5407.html