一、PSP表格
(1.1)在开始实现程序之前,在附录提供PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。
(1.2)在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块的开发上实际花费的时间。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 1320 | 1540 |
| · Analysis | · 需求分析 (包括学习新技术) | 500 | 540 |
| · Design Spec | · 生成设计文档 | 60 | 40 |
| · Design Review | · 设计复审 | 60 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 80 | 180 |
| · Coding | · 具体编码 | 300 | 360 |
| · Code Review | · 代码复审 | 60 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 240 | 300 |
| Reporting | 报告 | 110 | 105 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1440 | 1655 |
二、计算模块接口
(2.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
- 类的设计
这次作业的代码共设计了两个类,中文敏感词类和英文敏感词类。- 中文敏感词类 chinese
属性:敏感词本身word、敏感词长度length、拼音列表pinyin、拼音长度列表pinyinLen、按结构拆分后的汉字列表seperation
函数:检测函数testing
testing函数的参数为一段待检测的字符串;功能为对该字符串中是否含有此中文敏感词及其变形进行检测,若全字符串不包含敏感词,返回空字符串,包含则返回检测到匹配的文本text及其长度textLen。 - 英文敏感词类 english
属性:敏感词本身word、敏感词长度length
函数:检测函数testing
testing函数的参数为一段待检测的字符串;功能为对该字符串是否含有此英文敏感词及其变形进行检测,并返回检测到匹配的文本text及其长度textLen,若不匹配则返回空字符串。
- 中文敏感词类 chinese
两个类有部分内容相似,但中文敏感词类需要更多的属性,例如拼音、同音字及拆字,检测所用的函数也更复杂一些;而英文敏感词的属性就少,且判断所插入特殊字符也少。
-
函数设计
- 获取敏感词列表函数 getWords
参数:敏感词文件地址
功能:对文件中的中文和英文敏感词分别建立敏感词类的实例的列表 - 搜索并保存敏感文本函数 search
参数:待检测文本lines,中文英文敏感词列表chiWords、engWords
功能:通过调用敏感词实例的testing函数,对传入的一段的字符串文本进行检测,最终返回每个检测到词语列表result及检测到的总数totalCount。
- 获取敏感词列表函数 getWords
-
算法
对循环中每一行的字符串分别用每个敏感词的testing函数进行逐个判断,遇到不匹配的情况返回字符串的起始点,匹配时则继续往下检测,因此可能会有重复判断的内容,所以当匹配到后,由于不存在敏感词嵌套的情况,函数返回检测文本的长度textLen,然后跳过这一段不再检测剩余其他敏感词,避免重复检测。
过程大致如下图所示:
例如,若敏感词为“人们”,当所要检测的文本为“人(+m123”时,在进入“人”的分支后,“们”通过转化得到,它的变形为“门”,“亻门”,“m”,“门”,在忽略插入的特殊字符“(+”的同时,按顺序进行判断,直到检测完整,得到“<人们>: 人(+m”。若检测的敏感词为对于如“g”包含在“gong”当中和“工”包含在“工力”当中且同音等的情况,为了避免缺漏,对if条件判断语句的先后顺序进行调整。
(2.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
在改进计算模块性能上大概花了2个小时。最开始对于一整行字符串中的每个字开始都对所有敏感词全部测试一遍,造成了不必要的重复和时间的消耗。
改进的思路是尽量减少重复,对于已经检测到敏感词的字符串文本,通过返回检测到的敏感词变形的长度,跳过已检测的片段,不再对其他敏感词进行多余的检测。同时在检测中文同音词及繁体时,直接用拼音检测,不再额外转化。而对于第三方库的调用应该是无法再减少时间了。

如图所示,占用最多时间的函数为search函数。search函数是对给出的文本地址,逐行读出文本并调用检测函数testing进行检测,得到检测的所有结果及检测出敏感词的总个数。而testing函数在其中占用的时间最多,因为是对敏感词的所有形式进行检测,使用的if条件判断也很多。
代码如下:
def search(lines,chiWords,engWords):
lineCount=0
result=[]
totalCount=0#敏感词个数
textLen=0
for line in lines:#读取每行
lineCount+=1
line=line.strip()
i=0
while(i<len(line)):
for wd in engWords:
text,textLen=wd.testing(line[i:])
if textLen:
totalCount+=1
result.append("Line{}: <{}> {}".format(lineCount,wd.word,text))
i+=textLen-1
break
for wd in chiWords:
text,textLen=wd.testing(line[i:])
if textLen:
totalCount+=1
result.append("Line{}: <{}> {}".format(lineCount,wd.word,text))
i+=textLen-1
break
i+=1
return result,totalCount
def testing(self,wd):
text=""
str="".join(lazy_pinyin(wd[0]))
if str[0] == self.pinyin[0][0] or wd[0].lower()== self.pinyin[0][0] or wd[0]==self.seperation[0][0]:
i=0
j=0
insert=0
while(j<len(wd)):
if i == self.length or insert == 20 :
break
str1 = "".join(lazy_pinyin(wd[j]))
if j+2 <=len(wd) and wd[j:j+2]==self.seperation[i]:#拆字
text+=wd[j:j+2]
j+=1
i+=1
insert=0
elif str1 == self.pinyin[i] :#同音字或原文
text+=wd[j]
i+=1
insert=0
elif j+self.pinyinLen[i]<=len(wd) and (wd[j:j+self.pinyinLen[i]]).lower()==self.pinyin[i]:#全拼音
text+=wd[j:j+self.pinyinLen[i]]
j=j+self.pinyinLen[i]-1
i+=1
insert=0
elif wd[j].lower() ==self.pinyin[i][0]:#拼音首字母
text+=wd[j]
i+=1
insert=0
elif wd[j] in string.digits+string.ascii_letters+"[
`~!@#$%^&*()+-_=|{}':;',\[\].<>/?~!"@#¥%……&*()——+|{}【】‘;:”“’。, 、?]":
text+=wd[j]
insert+=1
else:
break
j+=1
if i!=self.length:
text=""
return text,len(text)
(2.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
对两个类中的testing函数是否能正确检测敏感词及其变形,以及search函数能否正确搜索文本中的每一行进行测试。
- 对于chinese类的testing函数测试了中文词语的左右结构拆分、拼音大小写、拼音首字母、插入字母或特殊字符以及的情况,分别是test_seperate函数,test_pinyin函数,test_insert函数,test_homophones函数。
- 对于english类的testing函数构造了英文单词大小写转换以及插入特殊字符的情况,为test_english函数
- 对于search函数提供一段文本进行单元测试,为test_search。
单元测试的部分代码如下(完整代码已上传仓库):
class functionTest(unittest.TestCase):
def test_seperate(self): #左右结构拆分
word="你好"
org="亻尔女子"
a=chinese(word)
text,textLen=a.testing(org)
self.assertEqual(text,"亻尔女子")
def test_pinyin(self): #拼音大小写、拼音首字母
word="你好"
org="nhAo"
a=chinese(word)
text,textLen=a.testing(org)
self.assertEqual(text,"nhAo")
def test_insert(self): #插入字母或特殊字符
word="你好"
org="你234a!@#$%^&*()_+=-`~好254早上好"
a=chinese(word)
text,textLen=a.testing(org)
self.assertEqual(text,"你234a!@#$%^&*()_+=-`~好")
def test_homophones(self): #插入字母或特殊字符
word="你好"
org="昵郝吃饭"
a=chinese(word)
text,textLen=a.testing(org)
self.assertEqual(text,"昵郝")
def test_english(self): #大小写转换以及插入特殊字符
word="hello"
org="Hel8!lo13"
a=english(word)
text,textLen=a.testing(org)
self.assertEqual(text,"Hel8!lo")
def test_search(self):
org=["93ni^&%hao13H8ellO4郝
"]
word_1="你好"
word_2="hello"
a=[chinese(word_1)]
b=[english(word_2)]
result,count=search(org,a,b)
self.assertEqual(result,['Line1: <你好> ni^&%hao', 'Line1: <hello> H8ellO'])
self.assertEqual(count,2)
单元测试的覆盖率如下:
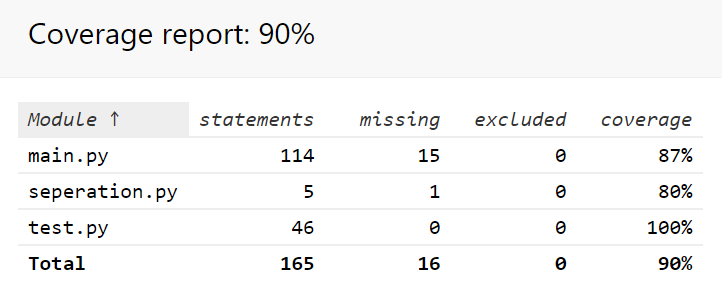
(2.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
对于命令行输入参数的个数错误以及打开文件时文件不存在的所导致异常进行处理。
-
命令行输入参数错误
当输入的命令行的参数个数不正确时,输出“命令行参数错误”,并手动抛出异常。- 代码
def parament():#命令行参数检查 if len(sys.argv) != 4: print("命令行参数错误") raise Exception("命令行参数错误") - 单元测试
def test_parament(self): try : parament() except Exception: self.assertTrue(True) else: self.assertTrue(False)
当输入命令行参数个数错误时,输出

- 代码
-
文件不存在
当根据地址打开文件时,若文件不存在,则手动抛出异常- 代码
def fileOpen(path):#打开文件 try: f=open(path,'r+',encoding='utf-8') except IOError: print("文件不存在") raise IOError("文件不存在") else: return f - 单元测试
def test_fileOpen(self): try : fileOpen("a.txt") except IOError: self.assertTrue(True) else: self.assertTrue(False)
当文件不存在时,输出

- 代码
三、心得
(3.1)在完成本次作业过程的心得体会
在这次个人编程作业布置后就觉得有些困难,于是和同学进行了讨论,也去搜索和学习了一些敏感词过滤的算法。作业中对我而言另一个难点是汉字的拼音转化以及左右结构拆分,花了一些时间在找第三方库和写自己引用的文件。虽然很困难,但也算是完成了大部分功能,最后检测出的结果也比最开始预想的要多。

同时,这是很长时间以来的唯一一次写了这么久的代码,也是第一次使用PSP表格对整个过程进行了梳理,过去往往是很快地想一下就开始写代码了。经过这次作业,学习了许多知识,了解了什么是单元测试,也对于完成一项软件工程的流程也有了更深刻的印象,也意识到了这是一门很难的课程。