一、创建数据库和表
CREATE DATABASE语句用于创建数据库,基本语法如下:
CREATE DATABASE database_name
在本地创建一个名为test的测试数据库:
CREATE TABLE test;
CREATE TABLE语句用于创建表,基本语法如下:
CREATE TABLE table_name( column_name1 type, column_name2 type, column_name3 type, ... )
在test数据库下面创建一张名为orders的表:
USE test; CREATE TABLE orders( id INT PRIMARY KEY AUTO_INCREMENT, order_time TIMESTAMP, cate VARCHAR(255), goods_id int, order_amount int )
二、插入数据
INSERT INTO 语句用于向表格中插入新的行,基本语法如下:
INSERT INTO table_name VALUES (value1, value2,....)
向orders表中插入一些测试数据:
INSERT INTO orders(order_time,cate,goods_id,order_amount) VALUES ('2018-02-28 00:00:01', '水果',223,100), ('2018-02-28 01:01:01', '花茶',444,111), ('2018-02-28 06:06:06', '花茶',444,666), ('2018-03-01 07:01:10', '花茶',5555,170), ('2018-03-01 08:00:00', '花茶',5555,180), ('2018-03-01 00:00:01', '花茶',333,100), ('2018-03-01 00:00:01', '花茶',444,188), ('2018-03-01 00:00:01', '数码',45454,5399)
结果如图所示: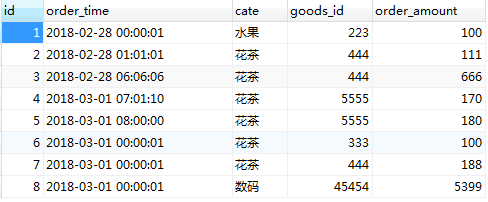
三、题目解析
1.请统计2018年全年每月销售金额,按下表格式返回。
| 日期 | 销售金额 |
|---|---|
| 2018-01 | **** |
| 2018-02 | **** |
| ... | ... |
分析:统计每月的销售金额,需要用到求和函数SUM()。SUM()函数用于返回数值列的总和。基本语法如下:
SELECT SUM(column_name) FROM table_name
求和通常需要用到GROUP BY,GROUP BY可以根据一个或多个列对结果集进行分组,本题也是这个套路,需要根据月份进行分组统计。GROUP BY的基本语法如下:
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name
当然本题还有其他附加要求,按照规定形式返回,需要对日期进行进行格式化处理。DATE_FORMAT() 函数用于以不同的格式显示日期/时间数据,基本语法如下:
DATE_FORMAT(date,format)
date 参数是合法的日期。format 规定日期/时间的输出格式。可以使用的格式有:
| 格式 | 描述 |
|---|---|
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时 (00-23) |
| %h | 小时 (01-12) |
| %I | 小时 (01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天 (001-366) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间, 24-小时 (hh:mm:ss) |
| %U | 周 (00-53) 星期日是一周的第一天 |
| %u | 周 (00-53) 星期一是一周的第一天 |
| %V | 周 (01-53) 星期日是一周的第一天,与 %X 使用 |
| %v | 周 (01-53) 星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w | 周的天 (0=星期日, 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| %Y | 年,4 位 |
| %y | 年,2 位 |
本题中的形式可以用DATE_FORMAT(t.order_time,'%Y-%m')把时间格式化成表格中的形式(年份-月份),然后按照题目要求的别名返回即可。
这题比较简单,分析了这么多,可以直接写SQL语句了:
SELECT DATE_FORMAT(t.order_time,'%Y-%m') AS '日期', SUM(t.order_amount) AS '销售金额' FROM orders t WHERE YEAR(t.order_time) = 2018 GROUP BY MONTH(t.order_time)
select date_format(order_time,'%Y-%m') as 日期,sum(order_amount) as 销售金额 from orders group by date_format(order_time,'%Y-%m');
日期用substring(t.order_time,1,7)也可以
执行结果正确,如图:

2..请统计2018年每月销售金额,以及金额排名。
| 日期 | 销售金额 | 金额排名 |
|---|---|---|
| 2018-01 | **** | 2 |
| 2018-02 | **** | 3 |
| ... | ... | ... |
| 2018-12 | **** | 9 |
这个题是要求销售金额的排名情况,求这个月的销售额在这一年的12月中排第几,需要得到具体排第几名。比如说2018年1月的销售金额在12个月中排第2名。不是用ORDER BY粗暴的进行排序完事!不是用ORDER BY粗暴的进行排序完事!不是用ORDER BY粗暴的进行排序完事!这个是我理解的题意。
使用的是MySQL数据库(MySQL数据库不能使用rank()函数)。这个问题可以分三个步骤解决:
1.在第(1)问的基础上按照销售金额进行排序;要求排名,当然先要按销售金额排序。
ORDER BY 用于对结果集按照一个列或者多个列进行排序。基本语法如下:
SELECT column_name,column_name FROM table_name ORDER BY column_name,column_name ASC|DESC;
对金额进行排序(降序需要加上DESC关键字):
SELECT DATE_FORMAT(t.order_time,'%Y-%m') AS mon, SUM(t.order_amount) AS sum FROM orders t WHERE YEAR(t.order_time) = 2018 GROUP BY MONTH(t.order_time) ORDER BY SUM(t.order_amount) DESC
为了排序和之后的效果显示,我又在表格中插入了2018年4月的记录。排序之后的结果如图所示:
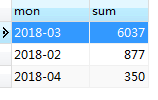
2.对排序的结果添加一个排名列;其实就是在上图结果后面添加一个排名字段。这里自定义一个排名变量rank,初始化为0,由于数据已经是排好序的,所以每次加1就是排名,从而实现一个取得排序后名次的效果。
在MySQL中声明一个变量,需要在变量名之前使用@符号。FROM子句中的(@rank:= 0)部分可以进行变量初始化,而不需要单独的SET命令。更多关于MySQL自定义变量可以参考Mysql自定义变量的使用和MySQL官网文档用户自定义变量。
例子:
SELECT (@rank := @rank+1) AS rank FROM ( SELECT * FROM table_name ) a,(SELECT @rank :=0) b
对本题中的销售金额进行排序后添加排名列的SQL语句:
SELECT a.mon AS r,a.sum AS x,@rank :=@rank + 1 AS j FROM (SELECT DATE_FORMAT(t.order_time,'%Y-%m') AS mon, SUM(t.order_amount) AS sum FROM orders t WHERE YEAR(t.order_time) = 2018 GROUP BY MONTH(t.order_time) ORDER BY SUM(t.order_amount) DESC) a,(SELECT @rank := 0) b
执行结果如图:
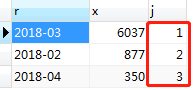
这样就实现了简单的rank排名函数,也基本满足了题意。但是这样写还有一个问题需要注意,遇到销售金额相等的情况,名次也会加1。如果向表中再插入一条记录2018年5月的记录,使得5月份的销售金额和2月份相等:
INSERT INTO orders(order_time,cate,goods_id,order_amount) VALUES ('2018-05-22 13:23:39', '果粒橙',111,877)
再去执行刚才的查询操作,结果如图:
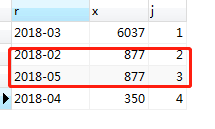
可以看见图中2018年2月和2018年5月的销售额都是877,2月排第2,5月排第3。这样排名貌似不合理吧?
还有更神奇的呢!再次执行相同的操作,结果却不相同。what?这次5月排第2,2月排第3了?什么情况?关于ORDER BY排序以后顺序为什么随机,我需要再好好研究一下MySQL底层原理。所以这个问题先留着。
如果是面试的话,在上面排名情况这个细节问题上就需要和面试官进行交流了,销售金额会不会有相等的情况?如果有相等的情况,遇到名次并列情况怎么办?如果说第1名有1个,第2名有两个并列,那么接下来的排名是第3名还是第4名呢?
接下来实现并列排名。如果题目要求相同数据并列排名,求排名的时候,需要拿前一个排名的数据来对比从而判断排名是否进行加1操作。SQL层面则需要自定义两个变量,一个记录之前排名的数据,一个记录现在的排名。如果之前排名的数据等于需要排名的数据,那么就是并列,排名不变。如果不相等,排名加1。也许我描述的不够清楚,看看SQL语句估计就明白了:
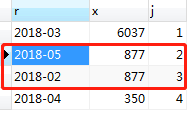
SELECT a.mon AS r,a.sum AS x, CASE WHEN @prevRank = a.sum THEN @curRank WHEN @prevRank := a.sum THEN @curRank := @curRank + 1 END AS j FROM (SELECT DATE_FORMAT(t.order_time,'%Y-%m') AS mon, SUM(t.order_amount) AS sum FROM orders t WHERE YEAR(t.order_time) = 2018 GROUP BY MONTH(t.order_time) ORDER BY SUM(t.order_amount) DESC) a,(SELECT @curRank :=0, @prevRank := NULL) b
执行上述语句,2月和5月排名实现了并列,如图:
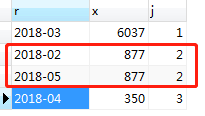
上面实现了普通并列排名,如果想实现高级并列排名(使上图中2018年4月数据排第4),需要定义3个变量,写起来有点复杂,这里先不写了。关于高级并列排名可以参考:在MySQL中实现Rank高级排名函数。
3.在第二步的基础上按照月份排序,完成。
经过了上面的步骤,离目标仅有一步之遥:按月份排序,还有替换别名。第二步的结果当成一张表,新建一个查询,对其进行月份排列,并把列名替换成为最终题目需要的列名即可。
SELECT tt.r AS '日期',tt.x AS '销售金额',tt.j AS '金额排名' FROM (SELECT a.mon AS r,a.sum AS x, CASE WHEN @prevRank = a.sum THEN @curRank WHEN @prevRank := a.sum THEN @curRank := @curRank + 1 END AS j FROM (SELECT DATE_FORMAT(t.order_time,'%Y-%m') AS mon, SUM(t.order_amount) AS sum FROM orders t WHERE YEAR(t.order_time) = 2018 GROUP BY MONTH(t.order_time) ORDER BY SUM(t.order_amount) DESC) a,(SELECT @curRank :=0, @prevRank := NULL) b) tt ORDER BY tt.r
结果如我所愿:

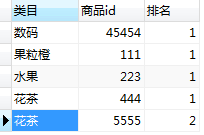
3.请用SQL选出2018年2月每个类目销量最高的2个爆款商品以及排名先后。
| 类目 | 商品id | 排名 |
|---|---|---|
| 水果 | 223 | 1 |
| 花茶 | 444 | 1 |
| 花茶 | 5555 | 2 |
| 数码 | 45454 | 1 |
这个问题是考察分组排名的问题:按照商品类目进行分组,按goods_id统计行数作为销量,找出每个商品种类销量前2名的goods_id,并给出排名。如果已经完全理解了第2问的使用自定义变量来实现添加排名操作,这一问做起来会轻松许多。
销量怎么计算?题目中没有明确说明,我理解的销量应该是表中的记录行数。统计记录行数需要使用COUNT()函数,基本语法如下:
SELECT COUNT(column_name) FROM table_name这个问题也可以分三个步骤解决:
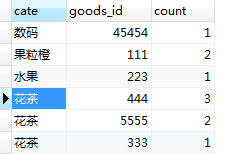
1.统计出来每种商品的销量,并按照类目、销量进行排序;这里由于表中的数据库记录较少,所以我直接统计的是2018年全年的数据,其实道理是一样的。SQL语句如下:
SELECT a.cate,a.goods_id,a.count FROM ( SELECT t.cate,t.goods_id,count(goods_id) AS count FROM orders t WHERE date_format(t.order_time, '%Y%m%d%H%i%s')LIKE "2018%" GROUP BY t.goods_id ORDER BY t.cate,count(t.goods_id) DESC ) AS a
执行结果如图:
2.使用自定义变量为排序结果添加排名。原理和用法与上一个问题是一样的,这里不赘述了。SQL语句如下:
SELECT a.cate,a.goods_id,a.count, @rank:= CASE WHEN @prevCate=a.cate THEN @rank+1 ELSE 1 END AS rankNO, @prevCate:=a.cate AS type FROM ( SELECT t.cate,t.goods_id,count(goods_id) AS count FROM orders t WHERE date_format(t.order_time, '%Y%m%d%H%i%s')LIKE "2018%" GROUP BY t.goods_id ORDER BY t.cate,count(t.goods_id) DESC ) AS a,(SELECT @rank:=0 ,@prevCate:='') b
执行结果如图:
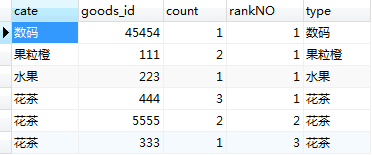
3.根据rankNO筛选前2名并按照题目要求格式返回;由于前面的铺垫,只需要用WHERE对rankNO进行筛选。SQL语句如下:
SELECT t.cate AS '类目',t.goods_id AS '商品id',t.rankNO AS '排名' FROM (SELECT a.cate,a.goods_id,a.count, @rank:= CASE WHEN @prevCate=a.cate THEN @rank+1 ELSE 1 END AS rankNO, @prevCate:=a.cate AS type FROM ( SELECT t.cate,t.goods_id,count(goods_id) AS count FROM orders t WHERE date_format(t.order_time, '%Y%m%d%H%i%s')LIKE "2018%" GROUP BY t.goods_id ORDER BY t.cate,count(t.goods_id) DESC ) AS a,(SELECT @rank:=0 ,@prevCate:='') b) t WHERE t.rankNO <= 2
执行结果和要求一模一样: