一、阅读笔记
软件需求的过程改进纪要使用更多对具体情况有效的方法,又要避免过去曾经带来麻烦的方法。然而,在绩效改进的道路上困难重重,包括岂不是无、来自受影响人群的阻力以及时间不足以进行当前任务之外改进工作所带来的挑战。
过程改进的最终目标是降低软件常见和维护的成本,并由此提高项目交付的价值。要做到这点,可以采用以下方式:
1.纠正在以往项目中过程缺陷所导致的问题
2.预见和预防未来项目中可能遇到的问题
3.使用比当前所用时间更有效、更有成果的实践
在每个正常进行的软件项目中,需求位于核心位置,是其他技术和管理工作得以支持和运作。需求开发和管理方法的变革将影响到这些过程,反之亦然。
二、mapreduce数据清洗
先说说自己是个大傻逼手贱添加了一个不该添加的依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.8.5</version>
</dependency>
然后
System.exit(job.waitForCompletion(true) ? 0 : 1)
这段代码一直报错java.lang.ClassNotFoundException: org.apache.hadoop.metrics.Updater
我查了没找到原因搞了我两小时
然后删了他就OK了,淦!
配置文件代码
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.chenqi.hadoop</groupId> <artifactId>hdfs</artifactId> <version>1.0-SNAPSHOT</version> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>7</source> <target>7</target> </configuration> </plugin> </plugins> </build> <!-- https://mvnrepository.com/artifact/junit/junit --> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.2.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>3.2.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>3.2.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.2.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-yarn-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-client</artifactId> <version>3.2.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-auth --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-auth</artifactId> <version>3.2.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client --> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>2.2.5</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-server --> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>2.2.5</version> </dependency> <dependency> <groupId>org.mongodb</groupId> <artifactId>mongo-java-driver</artifactId> <version>3.0.4</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.44</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-mapreduce</artifactId> <version>2.2.5</version> </dependency> </dependencies>
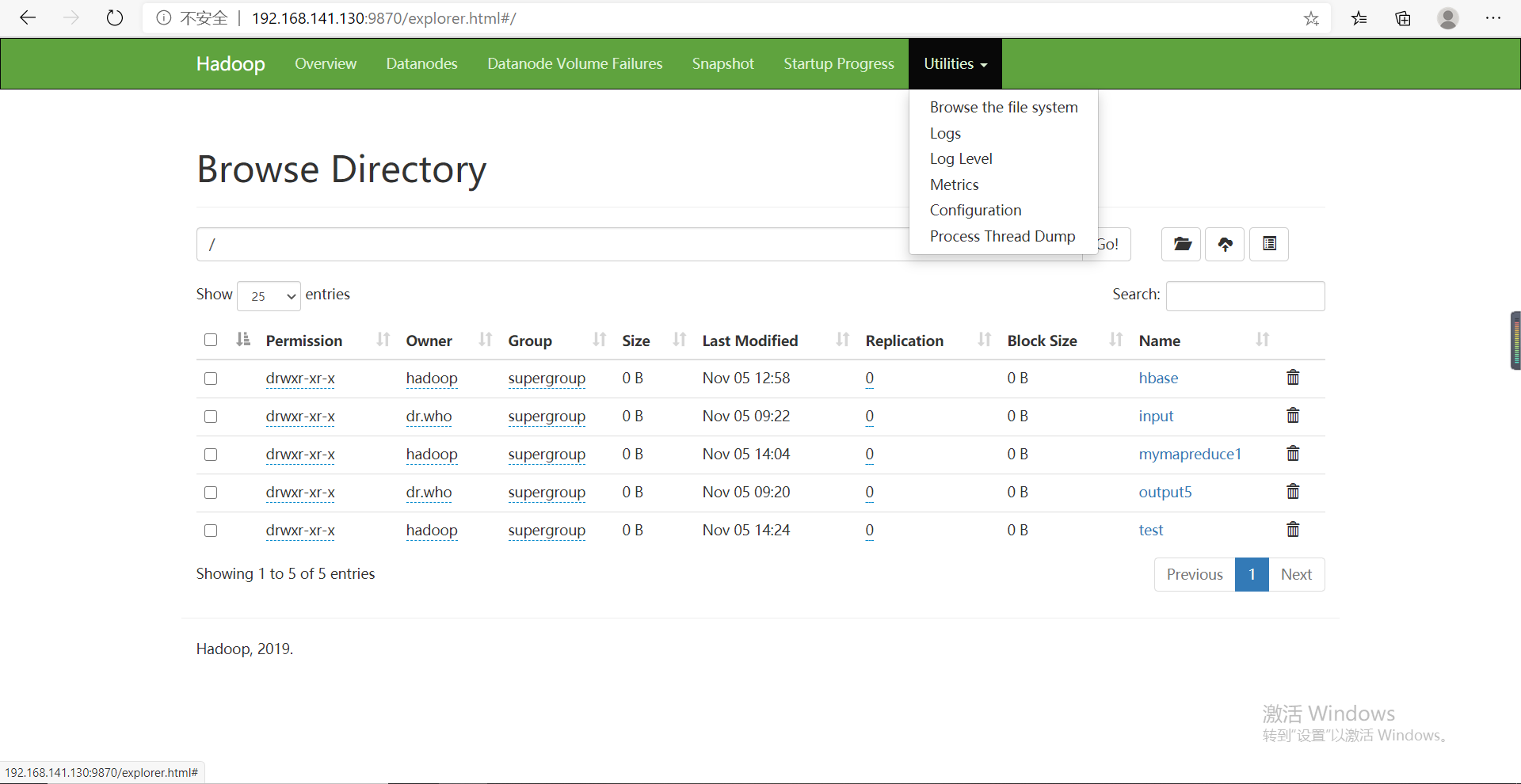
然后在启动hadoop集群后建立两个目录
hadoop fs -mkdir -p /test/in
hadoop fs -mkdir -p /test/stage3
然后在本地浏览器打开hadoop管理界面
找到我们刚才建立/test/in目录下
然后导入本地的result.txt文件
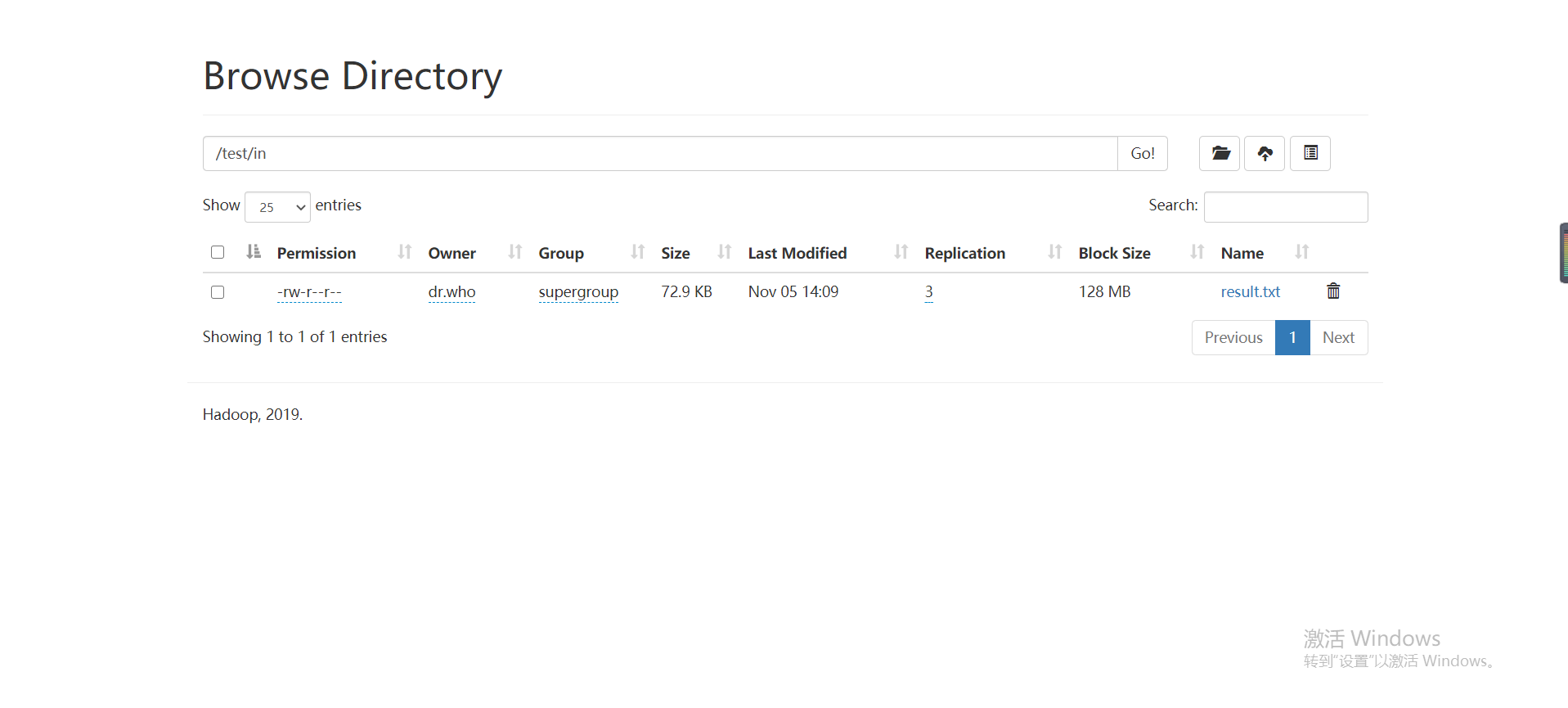
然后idea中代码为()
package homework; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Reducer.Context; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class quchong { public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException { Job job = Job.getInstance(); job.setJobName("paixu"); job.setJarByClass(quchong.class); job.setMapperClass(doMapper.class); job.setReducerClass(doReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); Path in = new Path("hdfs://192.168.141.130:9000/test/in/result.txt"); Path out = new Path("hdfs://192.168.141.130:9000/test/stage3/out1"); FileInputFormat.addInputPath(job,in); FileOutputFormat.setOutputPath(job,out); //// if(job.waitForCompletion(true)){ Job job2 = Job.getInstance(); job2.setJobName("paixu"); job2.setJarByClass(quchong.class); job2.setMapperClass(doMapper2.class); job2.setReducerClass(doReduce2.class); job2.setOutputKeyClass(IntWritable.class); job2.setOutputValueClass(Text.class); job2.setSortComparatorClass(IntWritableDecreasingComparator.class); job2.setInputFormatClass(TextInputFormat.class); job2.setOutputFormatClass(TextOutputFormat.class); Path in2=new Path("hdfs://192.168.141.130:9000/test/stage3/out1/part-r-00000"); Path out2=new Path("hdfs://192.168.141.130:9000/test/stage3/out2"); FileInputFormat.addInputPath(job2,in2); FileOutputFormat.setOutputPath(job2,out2); System.exit(job2.waitForCompletion(true) ? 0 : 1); } } public static class doMapper extends Mapper<Object,Text,Text,IntWritable>{ public static final IntWritable one = new IntWritable(1); public static Text word = new Text(); @Override protected void map(Object key, Text value, Context context) throws IOException,InterruptedException { //StringTokenizer tokenizer = new StringTokenizer(value.toString()," "); String[] strNlist = value.toString().split(","); // String str=strNlist[3].trim(); String str2=strNlist[4]+strNlist[5]; // Integer temp= Integer.valueOf(str); word.set(str2); //IntWritable abc = new IntWritable(temp); context.write(word,one); } } public static class doReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ private IntWritable result = new IntWritable(); @Override protected void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{ int sum = 0; for (IntWritable value : values){ sum += value.get(); } result.set(sum); context.write(key,result); } } ///////////////// public static class doMapper2 extends Mapper<Object , Text , IntWritable,Text>{ private static Text goods=new Text(); private static IntWritable num=new IntWritable(); @Override protected void map(Object key, Text value, Context context) throws IOException,InterruptedException { String line=value.toString(); String arr[]=line.split(" "); num.set(Integer.parseInt(arr[1])); goods.set(arr[0]); context.write(num,goods); } } public static class doReduce2 extends Reducer< IntWritable, Text, IntWritable, Text>{ private static IntWritable result= new IntWritable(); int i=0; public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{ for(Text val:values){ if(i<10) { context.write(key,val); i++; } } } } private static class IntWritableDecreasingComparator extends IntWritable.Comparator { public int compare(WritableComparable a, WritableComparable b) { return -super.compare(a, b); } public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { return -super.compare(b1, s1, l1, b2, s2, l2); } } }
这里注意把
Path in = new Path("hdfs://192.168.141.130:9000/test/in/result.txt"); Path out = new Path("hdfs://192.168.141.130:9000/test/stage3/out1");
中的地址改为自己master的地址就好了
in是我们导入的数据
out是输出的
然后去/test/stage3/out1目录下
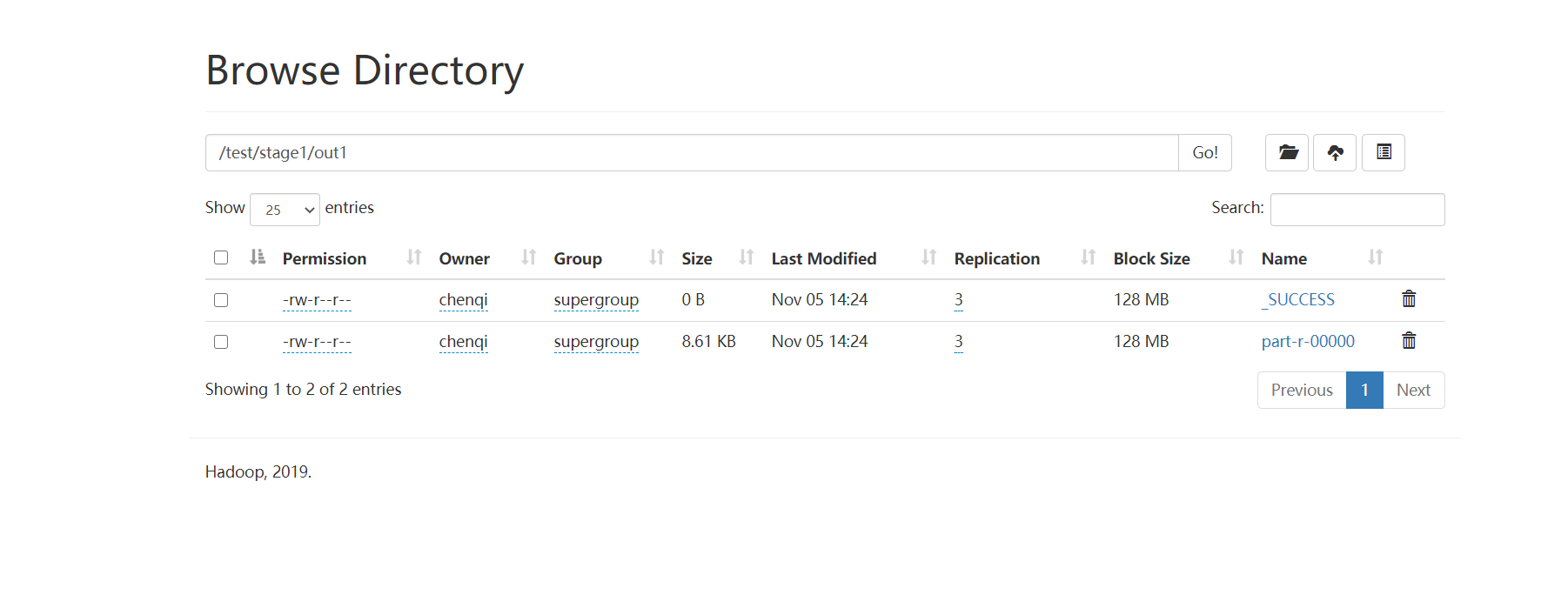
part-r-00000文件下载下来重命名为ip.txt
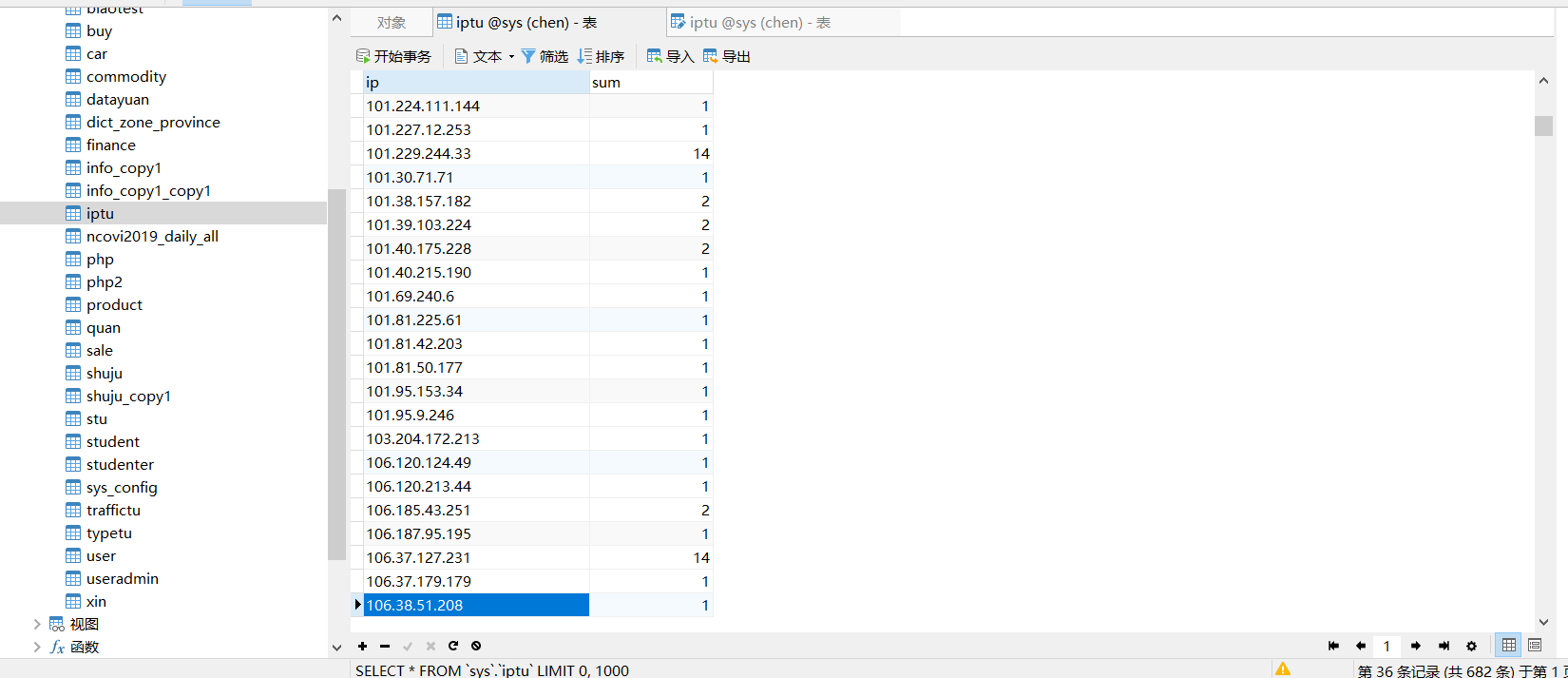
然后在Navicat 里新建一个表iptu

然后导入ip.txt作为数据
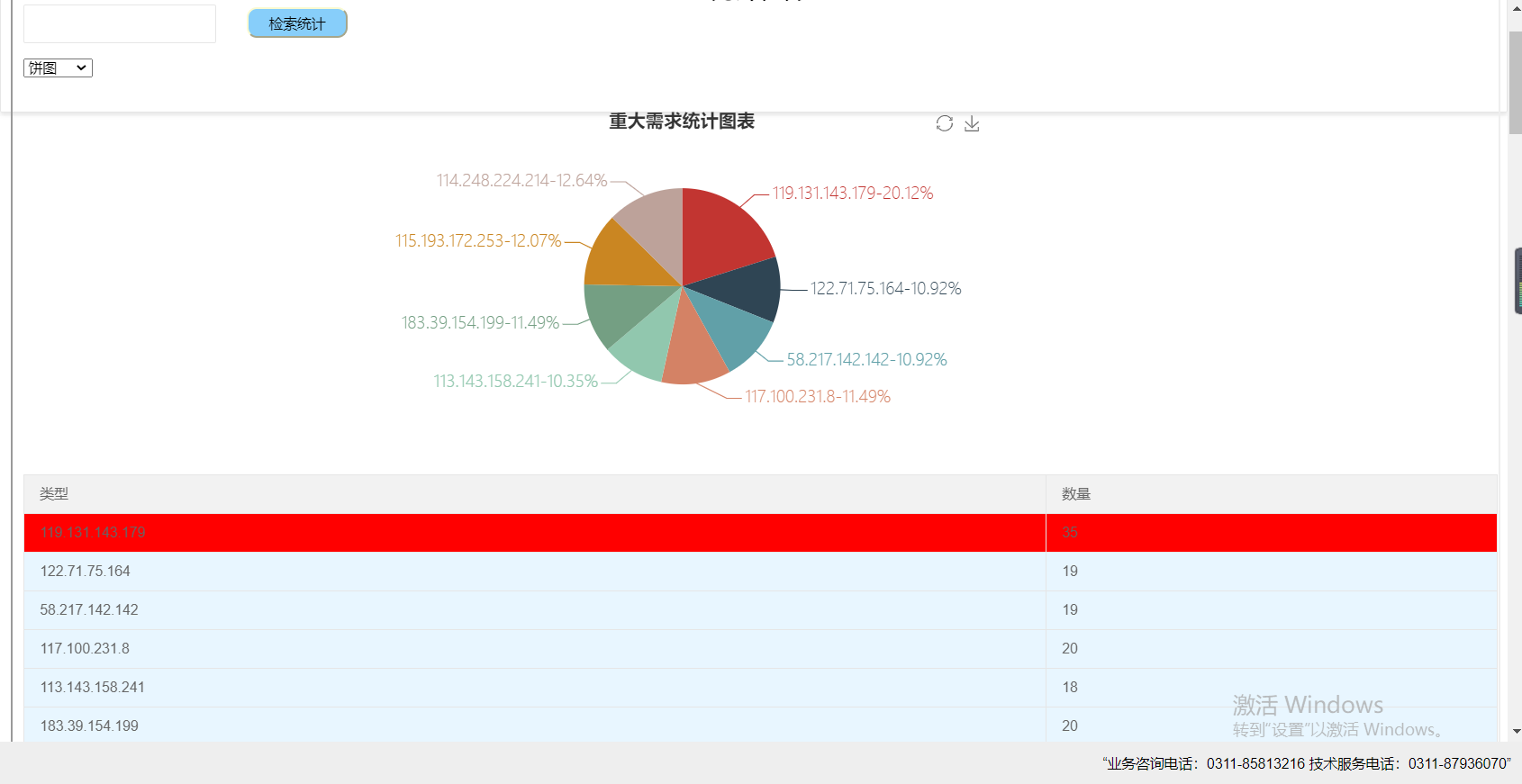
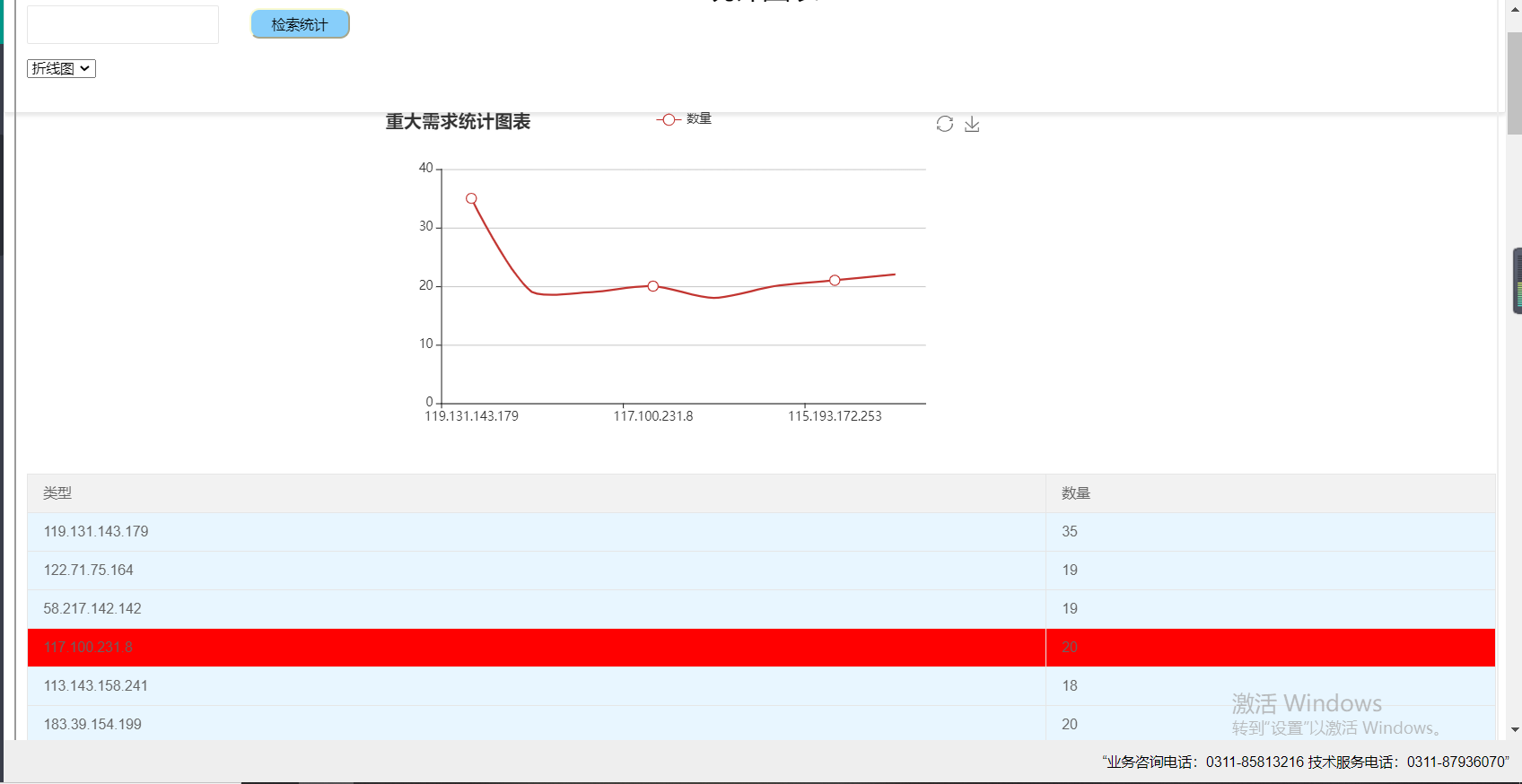
然后就是图表联动
jsp
<%@taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %> <%@ page contentType="text/html;charset=UTF-8" language="java" %> <%@page import="java.sql.*" %> <%--导入java.sql包--%> <% String path = request.getContextPath(); String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/"; %> <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>需求浏览</title> <script type="text/javascript" src="layui/layui.js"></script> <link rel="stylesheet" href="layui/css/layui.css"> <script type="text/javascript" src="${pageContext.request.contextPath}/js/jquery-1.11.1.js"></script> <script src="${pageContext.request.contextPath}/js/jquery-1.9.1.min.js"></script> <script src="${pageContext.request.contextPath }/js/bootstrap.min.js"></script> <script src="${pageContext.request.contextPath }/js/echarts.min.js"></script> <script src="${pageContext.request.contextPath }/js/echarts.js"></script> <script> layui.use('form', function(){ var form = layui.form; //各种基于事件的操作,下面会有进一步介绍 form.render(); }); </script> </head> <body style="margin-top:15px;margin-left: 10px;"> <div style="text-align: center;"> <h1>统计图表</h1> </div> <form class="layui-form" action="${pageContext.request.contextPath}/GuanServlet?method=searchke" method="post" > <div class="layui-form-item" > <div class="layui-input-inline" > </div> <div class="layui-input-inline" > <input type="text" name="leixing" placeholder="" autocomplete="off" class="layui-input zhi" > </div> <input type="submit" value="检索统计" align="center" style=" height: 30px; 100px;border-color: #FAFAD2;border-radius:10px ;background: #87CEFA;margin-top: 3px;margin-left: 20px;"> </div> </form> <select name="chose" id="chose" > <option value="bar">圆柱图</option> <option value="line">折线图</option> <option value="pie">饼图</option> </select> <div id="main" style=" 600px;height:352px;margin-top: 30px;margin-left: 350px"></div> <div id="main2" style=" 600px;height:352px;margin-top: 30px;margin-left: 350px"></div> <div id="main3" style=" 600px;height:352px;margin-top: 30px;margin-left: 350px"></div> <table class="layui-table" > <thead> <tr> <th >类型</th> <th >数量</th> </tr> </thead> <tbody id="body"> <c:if test="${empty lists}"> <tr> <td colspan="5">数据库中暂无公文</td> </tr> </c:if> <c:if test="${not empty lists}"> <c:forEach items="${lists}" var="list"> <tr> <td>${list.name}</td> <td>${list.value}</td> </tr> </c:forEach> </c:if> </tbody> </table> </body> <script type="text/javascript"> //综合查询框 $("#main").hide(); $("#main2").hide(); $("#main3").hide(); var tu='${tuway}'; if(tu=="show") { $("#main").show(); } var mydataX = new Array(0); var mydataY = new Array(0); var mydataP = new Array(0); var data = '${json}'; var json = eval('(' + data + ')'); //alert(data); for(var i=0;i<json.length;i++){ //alert(json[i].name+json[i].value); mydataX.push(json[i].name); mydataY.push(json[i].value); var t = {'name':json[i].name,'value':json[i].value} mydataP.push(t); } var myChart=echarts.init(document.getElementById("main")); var myChart2=echarts.init(document.getElementById("main2")); var myChart3=echarts.init(document.getElementById("main3")); //指定图表的配置项和数据 var option={ //标题 title:{ text:'重大需求统计图表' }, //工具箱 //保存图片 tooltip:{show:true}, yAxis:{type:'value'}, toolbox: { show : true, feature : { mark : {show: true}, restore : {show: true}, saveAsImage : { show: true, pixelRatio: 1, title : '保存为图片', type : 'png', lang : ['点击保存'] } } }, //图例-每一条数据的名字叫销量 legend:{ data:['数量'] }, //x轴 xAxis:{ data:mydataX, type: 'category' }, //y轴没有显式设置,根据值自动生成y轴 yAxis:{}, //数据-data是最终要显示的数据 series:[{ name:'数量', //type:'line', smooth: true, seriesLayoutBy: 'row', symbolSize: 10, type:'bar', data:mydataY }] }; var option2={ //标题 title:{ text:'重大需求统计图表' }, //工具箱 //保存图片 tooltip:{show:true}, yAxis:{type:'value'}, toolbox: { show : true, feature : { mark : {show: true}, restore : {show: true}, saveAsImage : { show: true, pixelRatio: 1, title : '保存为图片', type : 'png', lang : ['点击保存'] } } }, //图例-每一条数据的名字叫销量 legend:{ data:['数量'] }, //x轴 xAxis:{ data:mydataX, type: 'category' }, //y轴没有显式设置,根据值自动生成y轴 yAxis:{}, //数据-data是最终要显示的数据 series:[{ name:'数量', type:'line', smooth: true, seriesLayoutBy: 'row', symbolSize: 10, data:mydataY }] }; var option3= { title : { text : '重大需求统计图表', subtext : '', x : 'center' }, tooltip : { trigger : 'item', formatter : "{a} <br/>{b} : {c} ({d}%)" }, toolbox: { show : true, feature : { mark : {show: true}, restore : {show: true}, saveAsImage : { show: true, pixelRatio: 1, title : '保存为图片', type : 'png', lang : ['点击保存'] } } }, legend : { orient : 'vertical', left : 'left', data : mydataX.baseDataCategory }, series : [ { name : '值域占比', type : 'pie', radius : '55%', center : [ '50%', '50%' ], data : mydataP, itemStyle : { emphasis : { shadowBlur : 10, shadowOffsetX : 0, shadowColor : 'rgba(0, 0, 0, 0.5)' }, normal : { label : { show : true, formatter : '{b}-{d}%', textStyle : { fontWeight : 300, fontSize : 16 //文字的字体大小 }, }, lableLine : { show : true } } } } ] }; myChart.setOption(option); myChart2.setOption(option2); myChart3.setOption(option3); //使用刚刚指定的配置项和数据项显示图表 var sel=document.getElementById("chose"); sel.onchange=function(){ if(sel.options[sel.selectedIndex].value=="line"){ $("#main").hide(); $("#main2").show(); $("#main3").hide(); }else if(sel.options[sel.selectedIndex].value=="pie"){ $("#main").hide(); $("#main2").hide(); $("#main3").show(); } else{ $("#main").show(); $("#main2").hide(); $("#main3").hide(); } } myChart3.on('click', function (params) { let trlist = $("#body").children('tr'); var name = params.name; alert("选中"+name+"!查询成功"); for (var i=0;i<trlist.length;i++) { var tdArr = trlist.eq(i).find("td"); var namec = tdArr.eq(0).text();// 备注 if(namec==name){ trlist.eq(i).css("background-color","red"); }else { trlist.eq(i).css("background-color","#E8F6FF"); } } trlist.eq(0).focus(); }); myChart2.on('click', function (params) { let trlist = $("#body").children('tr'); var name = params.name; alert("选中"+name+"!查询成功"); for (var i=0;i<trlist.length;i++) { var tdArr = trlist.eq(i).find("td"); var namec = tdArr.eq(0).text();// 备注 if(namec==name){ trlist.eq(i).css("background-color","red"); }else { trlist.eq(i).css("background-color","#E8F6FF"); } } trlist.eq(0).focus(); }); myChart.on('click', function (params) { let trlist = $("#body").children('tr'); var name = params.name; alert("选中"+name+"!查询成功"); for (var i=0;i<trlist.length;i++) { var tdArr = trlist.eq(i).find("td"); var namec = tdArr.eq(0).text();// 备注 if(namec==name){ trlist.eq(i).css("background-color","red"); }else { trlist.eq(i).css("background-color","#E8F6FF"); } } trlist.eq(0).focus(); }); </script> </html>
servlet
protected void searchke(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException, SQLException { //用于参数的中转(由管理员浏览所有角色界面传来)传递想要查询的条件 req.setCharacterEncoding("utf-8"); String geshu=req.getParameter("leixing"); System.out.println(geshu); Hashtable<String,Integer> biao=new Hashtable<String,Integer>(); BiaoDao biaodao=new BiaoDao(); biao=biaodao.tuke(geshu); List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(biao.entrySet());//创建集合list,并规范集合为哈希表类型,并用labelsMap.entrySet()初始化 List<Mydata> mydata = new ArrayList<Mydata>(); for (Map.Entry<String, Integer> mapping :list) //遍历集合 { Mydata info = new Mydata(); info.setName(mapping.getKey()); info.setValue(String.valueOf(mapping.getValue())); mydata.add(info); System.out.println(mapping.getKey() + ":" + mapping.getValue()); } Gson gson = new Gson(); String json = gson.toJson(mydata); req.setAttribute("lists",mydata); req.setAttribute("json",json); req.setAttribute("tuway","show"); req.getRequestDispatcher("/keshihua.jsp").forward(req,resp); }
dao层
public Hashtable<String,Integer> tuke(String geshu)throws IOException, SQLException{ String sql = "select * from Iptu"; int sum=Integer.parseInt(geshu); List<ipBean> off=new ArrayList<ipBean>(); Butil db=new Butil(); ipBean biao =new ipBean(); Connection conn=(Connection) db.getConn(); PreparedStatement ptmt=(PreparedStatement) conn.prepareStatement(sql); ResultSet rs=ptmt.executeQuery(); while(rs.next()){ ipBean result=new ipBean(); result.setIp(rs.getString("ip")); result.setSum(rs.getInt("sum")); off.add(result); } Hashtable<String,Integer> hash = new Hashtable<String,Integer>(); Hashtable<String,Integer> hash2 = new Hashtable<String,Integer>(); for (ipBean b :off) //遍历查询后的集合 { hash.put(b.getIp(),b.getSum()); //如果不存在,则把该字符串当作关键词存到哈希表中,并把把该对象value设为1 } List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(hash.entrySet());//创建集合list,并规范集合为哈希表类型,并用labelsMap.entrySet()初始化 list.sort(new Comparator<Map.Entry<String, Integer>>() //定义list排序函数 { public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { int a=o1.getKey().compareTo(o2.getKey()); //比较两者之间字典序大小并其布尔值赋给变量a if(o1.getValue() < o2.getValue()) //比较两者之间次数的大小 { return 1; //若后者大返回1,比较器会将两者调换次序,此为降序 } else if((o1.getValue() == o2.getValue())||((o1.getValue()==1)&&(o2.getValue()==1))) //若次数相同比较字典序 { if(a!=0&&a>0) //字典序在前的在前面 { return 1; } } return -1; } }); int m=0; for (Map.Entry<String, Integer> mapping :list) //遍历排序后的集合 { hash2.put(mapping.getKey(),mapping.getValue()); System.out.println(mapping.getKey() + ":" + mapping.getValue()); if(m>=sum) { break; //输入6个后结束 } m++; } return hash2; }