之前学习了CNN的相关知识,提到Yoon Kim(2014)的论文,利用CNN进行文本分类,虽然该CNN网络结构简单效果可观,但论文没有给出具体训练时间,这便值得进一步探讨。
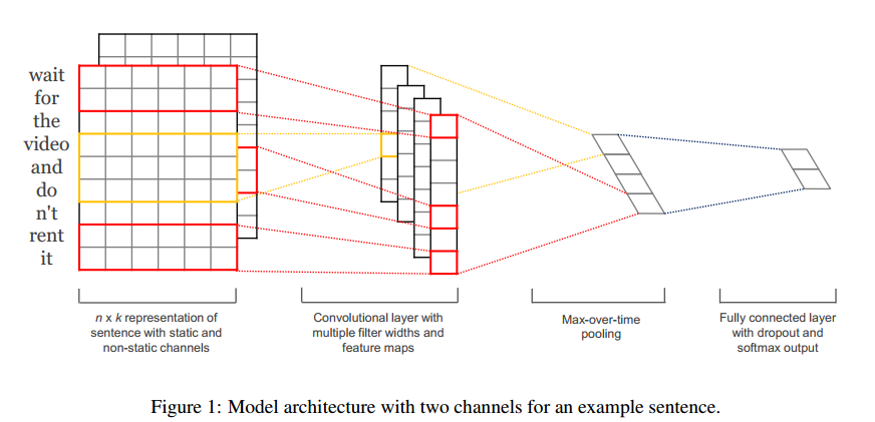
Yoon Kim代码:https://github.com/yoonkim/CNN_sentence
利用作者提供的源码进行学习,在本人机子上训练时,做一次CV的平均训练时间如下,纵坐标为min/CV(供参考):
机子配置:Intel(R) Core(TM) i3-4150 CPU @ 3.50GHz, 32G,x64

显然,训练非常慢慢慢!!!在CPU上训练,做10次CV,得10多个小时啊,朋友发邮件和Yoon Kim求证过,他说确实很慢慢慢,难怪论文中没有出现训练时间数据~.~
考虑改进的话,要么就是多线程作并行,卷积层可做并行,但代码不容易写啊:(,所以我考虑GPU加速。
流程:1、安装NVIDIA驱动;2、安装配置CUDA;3、修改程序用GPU跑;
1、安装NVIDA驱动
(0)看看你有没有符合的显卡:lspci | grep -i nvidia,参考教程
(1)下载对应显卡的nVidia驱动:http://www.nvidia.com/Download/index.aspx?lang=en-us
本人机子GPU:GeForce GTX 660 Ti,对应下载的驱动为NVIDIA-Linux-x86_64-352.63.run
(2)添加可执行权限: sudo chmod +x NVIDIA-Linux-x86_64-352.63.run
(3)关闭X-window:sudo service lightdm stop,然后切换到tty1:Ctrl+Alt+F1
(4)安装驱动:sudo ./NVIDIA-Linux-x86_64-352.63.run。按照其中提示进行安装,可能要设置compat32-libdir
(5)重启X-window:sudo service lightdm start.
(6)验证驱动安装是否成功:cat /proc/driver/nvidia/version
2、安装配置CUDA
(1)安装教程:http://docs.nvidia.com/cuda/cuda-getting-started-guide-for-linux/index.html#ubuntu-installation
(2)下载cuda-toolkit:https://developer.nvidia.com/cuda-downloads。选择和你配置符合的cuda下载:cuda-repo-ubuntu1404-7-5-local_7.5-18_amd64.deb
(3)注意不同系统的安装命令不同,下面是ubuntu14.04安装命令。有什么问题看上面的教程可以搞定。
sudo dpkg -i cuda-repo-ubuntu1404-7-5-local_7.5-18_amd64.deb sudo apt-get update sudo apt-get install cuda
(4)验证toolkit是否成功:nvcc -V
(5)配置路径:vim .bashrc
PATH=$PATH:/usr/local/cuda-7.0/bin LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda7.0/lib64 export PATH export LD_LIBRARY_PATH
3、修改程序用GPU跑
根据theano官方文档:http://deeplearning.net/software/theano/tutorial/using_gpu.html
可以先用下列代码测试CUDA配置是否正确,能否正常使用GPU。


from theano import function, config, shared, sandbox import theano.tensor as T import numpy import time vlen = 10 * 30 * 768 # 10 x #cores x # threads per core iters = 1000 rng = numpy.random.RandomState(22) x = shared(numpy.asarray(rng.rand(vlen), config.floatX)) f = function([], T.exp(x)) print(f.maker.fgraph.toposort()) t0 = time.time() for i in xrange(iters): r = f() t1 = time.time() print("Looping %d times took %f seconds" % (iters, t1 - t0)) print("Result is %s" % (r,)) if numpy.any([isinstance(x.op, T.Elemwise) for x in f.maker.fgraph.toposort()]): print('Used the cpu') else: print('Used the gpu')
将上述代码保存为check_GPU.py,使用以下命令进行测试,根据测试结果可知gpu能否正常使用,若出错有可能是上面路径配置问题。
$ THEANO_FLAGS=mode=FAST_RUN,device=cpu,floatX=float32 python check1.py [Elemwise{exp,no_inplace}(<TensorType(float32, vector)>)] Looping 1000 times took 3.06635117531 seconds Result is [ 1.23178029 1.61879337 1.52278066 ..., 2.20771813 2.29967761 1.62323284] Used the cpu $ THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python check1.py Using gpu device 0: GeForce GTX 580 [GpuElemwise{exp,no_inplace}(<CudaNdarrayType(float32, vector)>), HostFromGpu(GpuElemwise{exp,no_inplace}.0)] Looping 1000 times took 0.638810873032 seconds Result is [ 1.23178029 1.61879349 1.52278066 ..., 2.20771813 2.29967761 1.62323296] Used the gpu
由于目前Nvidia GPU主要是针对float32位浮点数计算进行优化加速,所以需要将代码中的数据及变量类型置成float32。
具体对代码做如下更改:
(1)process_data.py
line 55, W = np.zeros(shape=(vocab_size+1, k), dtype='float32') line 56, W[0] = np.zeros(k, dtype='float32')
修改后运行命令,获得每个word对应的词向量(float32)。
python process_data.py GoogleNews-vectors-negative300.bin
(2)conv_net_sentence.py
添加allow_input_downcast=True,程序中间运算过程若产生float64,会cast到float32。
lin 82, set_zero = theano.function([zero_vec_tensor], updates=[(Words, T.set_subtensor(Words[0,:], zero_vec_tensor))], allow_input_downcast=True) lin131, val_model = theano.function([index], classifier.errors(y), givens={ x: val_set_x[index * batch_size: (index + 1) * batch_size], y: val_set_y[index * batch_size: (index + 1) * batch_size]}, allow_input_downcast=True) lin 137, test_model = theano.function([index], classifier.errors(y), givens={ x: train_set_x[index * batch_size: (index + 1) * batch_size], y: train_set_y[index * batch_size: (index + 1) * batch_size]}, allow_input_downcast=True) lin 141, train_model = theano.function([index], cost, updates=grad_updates, givens={ x: train_set_x[indexbatch_size:(index+1)batch_size], y: train_set_y[indexbatch_size:(index+1)batch_size]}, allow_input_downcast=True) lin 155, test_model_all = theano.function([x,y], test_error, allow_input_downcast=True)
(3)运行程序
THEANO_FLAGS=mode=FAST_RUN,device=gpu0,floatX=float32,warn_float64=raise python conv_net_sentence.py -static -word2vec
THEANO_FLAGS=mode=FAST_RUN,device=gpu0,floatX=float32,warn_float64=raise python conv_net_sentence.py -nonstatic -word2vec
THEANO_FLAGS=mode=FAST_RUN,device=gpu0,floatX=float32,warn_float64=raise python conv_net_sentence.py -nonstatic -rand
(4)结果惊人,训练时间提升了20x。
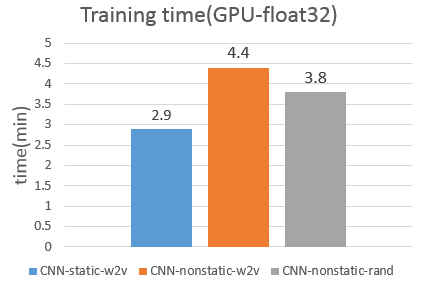
第一次跑gpu,以上过程,若有疏忽,还请多多指导。
Reference:
1、有关theano配置:http://deeplearning.net/software/theano/library/config.html
2、Ubuntu安装Theano+CUDA:http://www.linuxidc.com/Linux/2014-10/107503.htm