Stochastic Downsampling
2018-CVPR-Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks
来源:ChenBong 博客园
- Institute:NTU,Adobe,Alibaba,NVIDIA
- Author:Jason Kuen,Xiangfei Kong,Gang Wang
- GitHub:https://github.com/xternalz/SDPoint 10+
- Citation: 7
Introduction
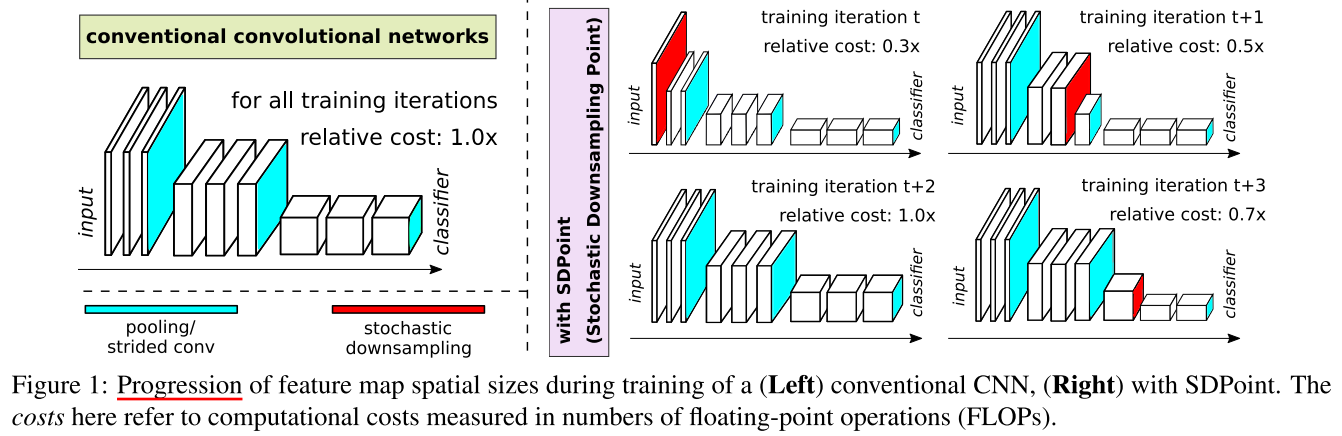
在预先定义的 downsample 结构的基础上,在额外插入一个 downsample,来实现推理时的计算开销自适应;
训练方式:每个batch随机采样额外 downsample 插入的位置 p 和下采样比例 r:
Related Work
Cost-adjustable Inference
计算量自适应:
- “intermediate” classifiers+early exit:通过加入多个中间分类器+提前退出,来实现推理自适应(subnet)
- parallel subnetworks or “paths”:同时训练不同规模的子网(subnet)
- input scale:使用不同的输入分辨率(fullnet)
样本自适应:
- harder vs easier
Motivation
现有的推理自适应的工作大多都是使用全部权重的一部分子集(选择部分层/部分宽度,subnet)来实现推理量的自适应,没有充分利用全部网络参数
现有的经典网络结构中,downsample(pool / strid conv)都是由网络结构本身预先定义好的,如果不限制 downsample 的位置,允许网络在任意位置进行 downsample,可以实现使用同一套网络参数来实现不同的推理开销,且充分利用了全部网络参数
Contribution
Method
在预先定义的 downsample 基础上,在额外插入一个 downsample,插入的位置 (p∈mathbb Z),比例 (r in mathbb R) 在每个batch训练之前随机选择
(P = {0, 1, 2, ...,N-1,N})
(R = {0.5, 0.75})
p 越小(插入位置越靠前),r 越小(下采样比例越高),那么网络的开销就节省的多,反之节省得少;
如果 p=0,可以有2种含义,1. 相当于 input scale;2. 相当于不插入额外的 downsample 相当于cost=1.0;本文用的是第2种(感觉其实用第1种更合理,cost=1.0 只要r=1.0即可)
细节
downsample operation
其中 downsample 的操作记为 D(·),D(·)可以是:pooling(avg/max),stride conv。& stride conv 会引入额外参数和计算量
我们选择 avg pool 而不是 stride conv 和 max pool,因为:
- stride conv 虽然用来downsample的效果较好,但引入了额外的参数和计算量,我们想排除额外的计算开销的影响。
- 且 stride conv 不能使用任意的下采样率 r
- max pool 的非线性更强(更多地保留正值),导致:1. 对 baseline 不公平,2. &&使梯度消失问题更严重
对于非整数的 avg pool,使用一种叫 Spatial Pyramid Pooling 的方法
shortcut
对于有残差连接的网络,插入位置在不同 residual block 之间,且 D(·) 作用在 residual add 之后
(p, r) 随机采样频率
每个batch 随机采样一组(p,r)进行训练
downsample 数量
可以插入多个额外的 downsample,但组合情况过多,因此我们只插入1个额外的downsample
ratio r
- r 是从离散的集合R中均匀采样
- r 不能太小,会影响收敛性
- (|R|) 不能太大,太大会导致组合太多
综上,我们取 (R = {0.5, 0.75})
BN
每组 (p, r) 独立计算BN
Experiments
CIFAR-10/100
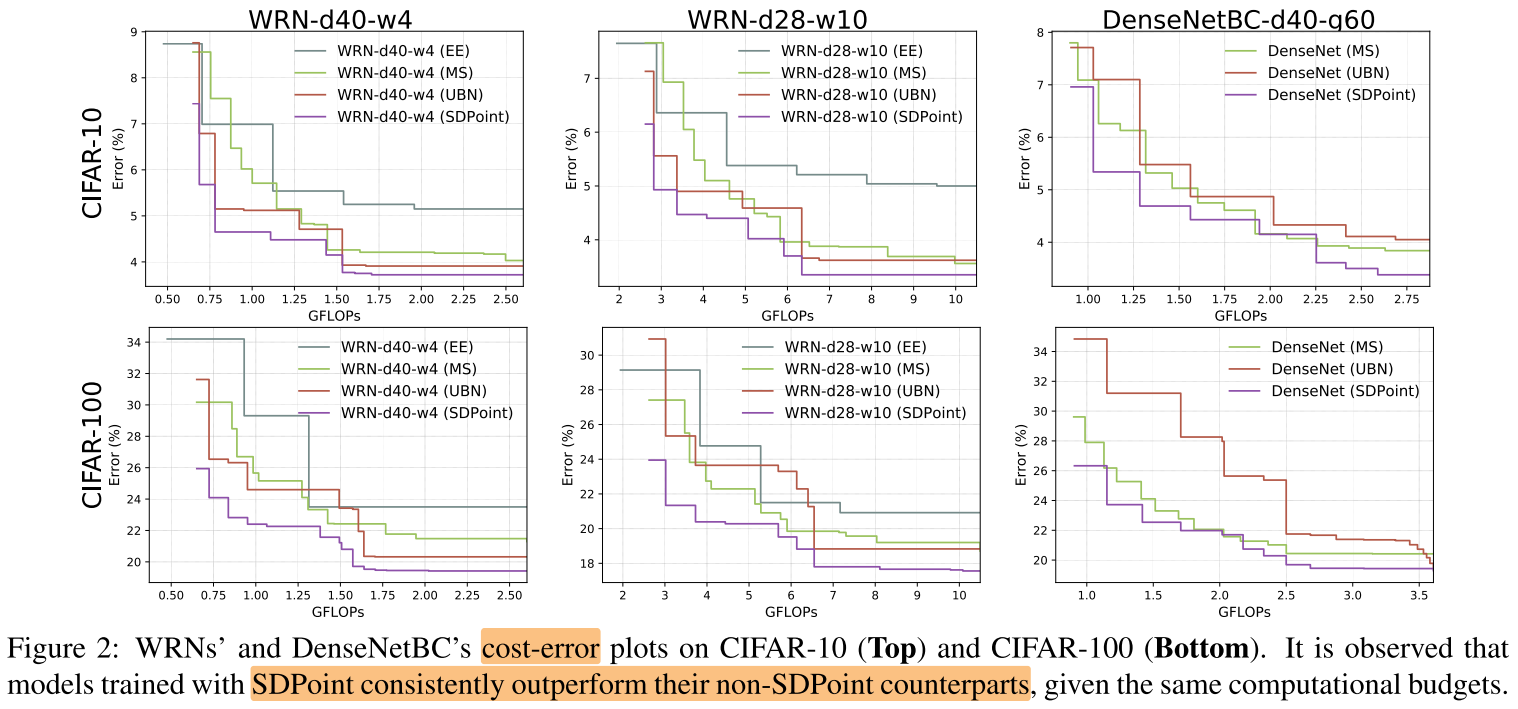
其他cost-adjustable方法,BN
Early-Exits (EE)
按照论文 BranchyNet 的方法设计多个中间分类器,允许提前退出
图2可以看出EE的效果都比较差,原因:
- 没有利用完整的网络参数
- Early-Exit 迫使CNN在浅层就具备分类能力(学习高级特征),导致深层无法有效学习
Multiscale Training (MS)
对 input 做 scale
Uniform Batch Normalization (UBN)
使用统一的BN
CIFAR-10/100 SOTA
SDPoint取的是所有 instance 中最好的一个:
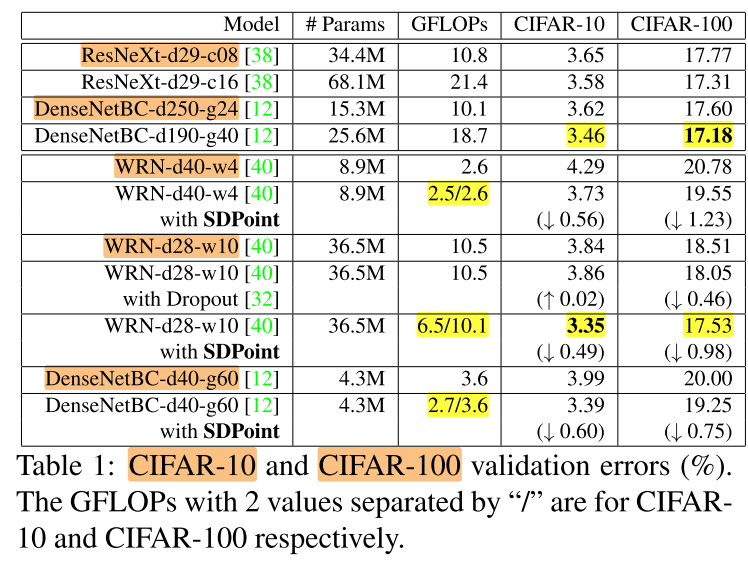
SDPoint在没有引入额外参数/计算开销的情况下,实现了sota,且在cifar10中基本上都节省了计算量,可能是对于cifar10数据集无需长期保持较高的分辨率,可以提前downsample,揭示了CNN 中 “one-size-fits-all” 的缺点
ImageNet
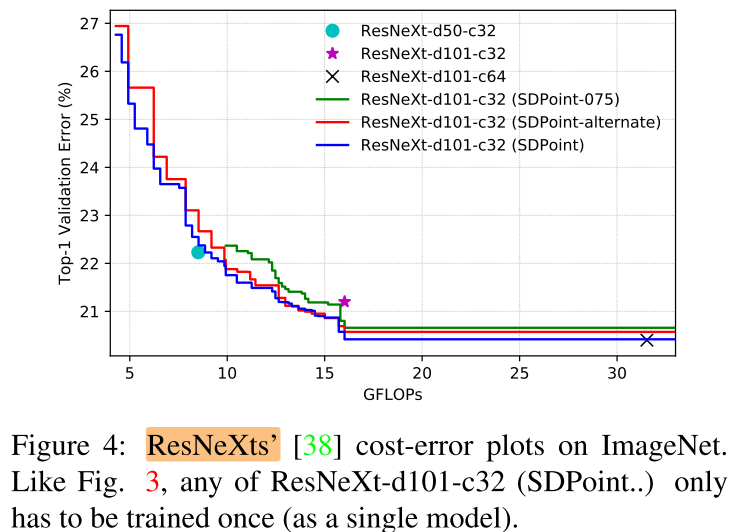
2个baseline:ResNeXt-d101-c32 和 PreResNet-d101:

Ablation Study
- alternate:插入点减半(间隔插入)
- 075: (R = {0.75})
随机性降低,效果变差
ImageNet SOTA
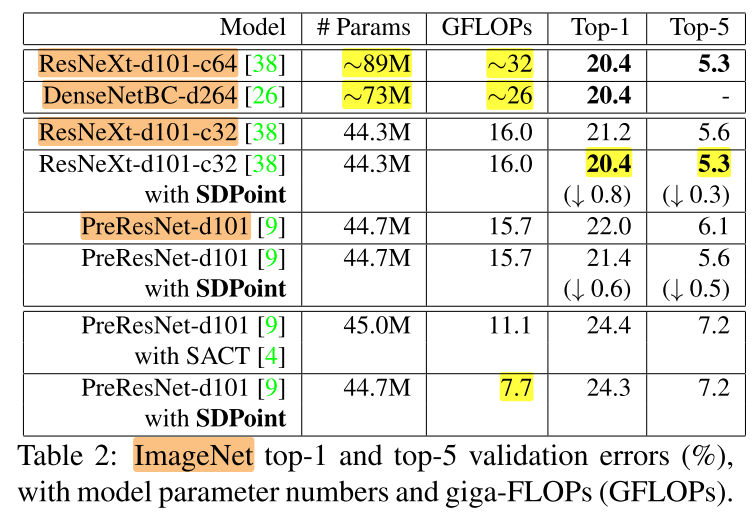
没有引入新的参数/计算量就达到了sota,在之前是需要2倍的计算量才能达到
SACT是跳过部分block,从而节省参数的一种方法
可视化

Conclusion
Summary
- 本文在预先定义的 downsamp 基础上再随机添加1个downsamle,研究的是插入位置,还可以研究固定位置,r可变(有点像 ShapeAdaptor 做的)