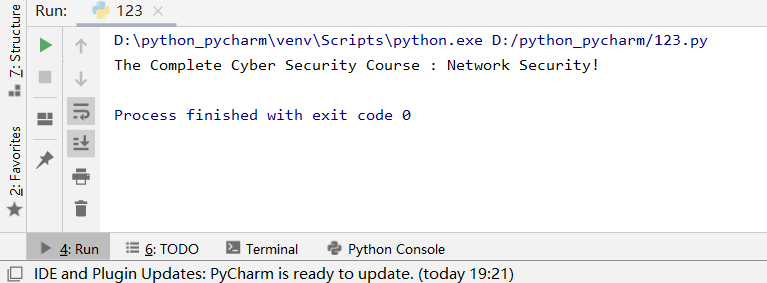
在使用requests请求一个页面上的元素时,有时会出现请求不到结果的情况
审查元素时可以看到的标签,在页面源代码中却看不到
原因是我们想要的元素是经过js事件动态生成的
一般有两种方式可以拿到我们想要的内容
一、使用selenium模拟浏览器
二、分析网页请求
这里介绍第一种方法
首先安装selenium库
命令提示符输入:
pip install selenium
下载,配置webdriver(以chromdriver为例)
1、查看浏览器的版本
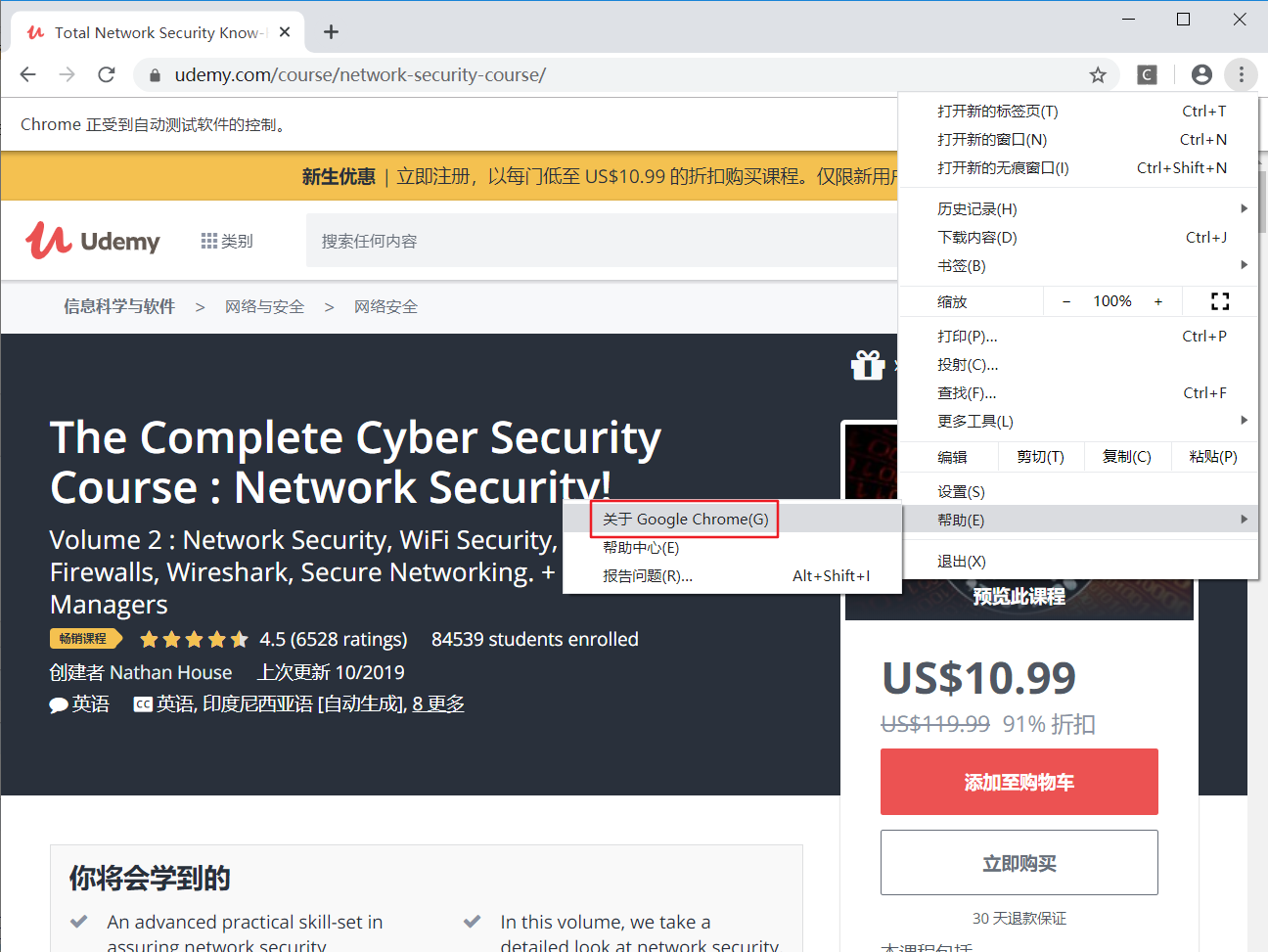
2、下载chromedriver
地址:http://npm.taobao.org/mirrors/chromedriver/
下载浏览器对应版本

下载对应系统对应版本(windows64位下载win32版本即可)

3、配置chromedriver
将下载的文件解压至chrome浏览器的安装路径下
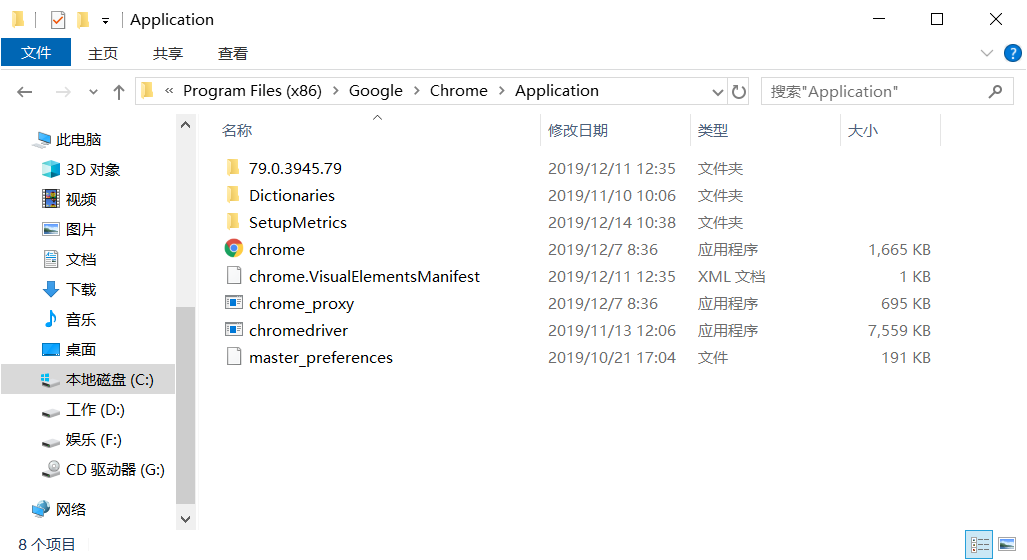
配置环境变量
路径为文件解压路径

4、使用selenium库请求访问网站就可以使用解析库来拿到我们想要的信息了
例如,我们想要这个标题信息,右键审查元素查看代码
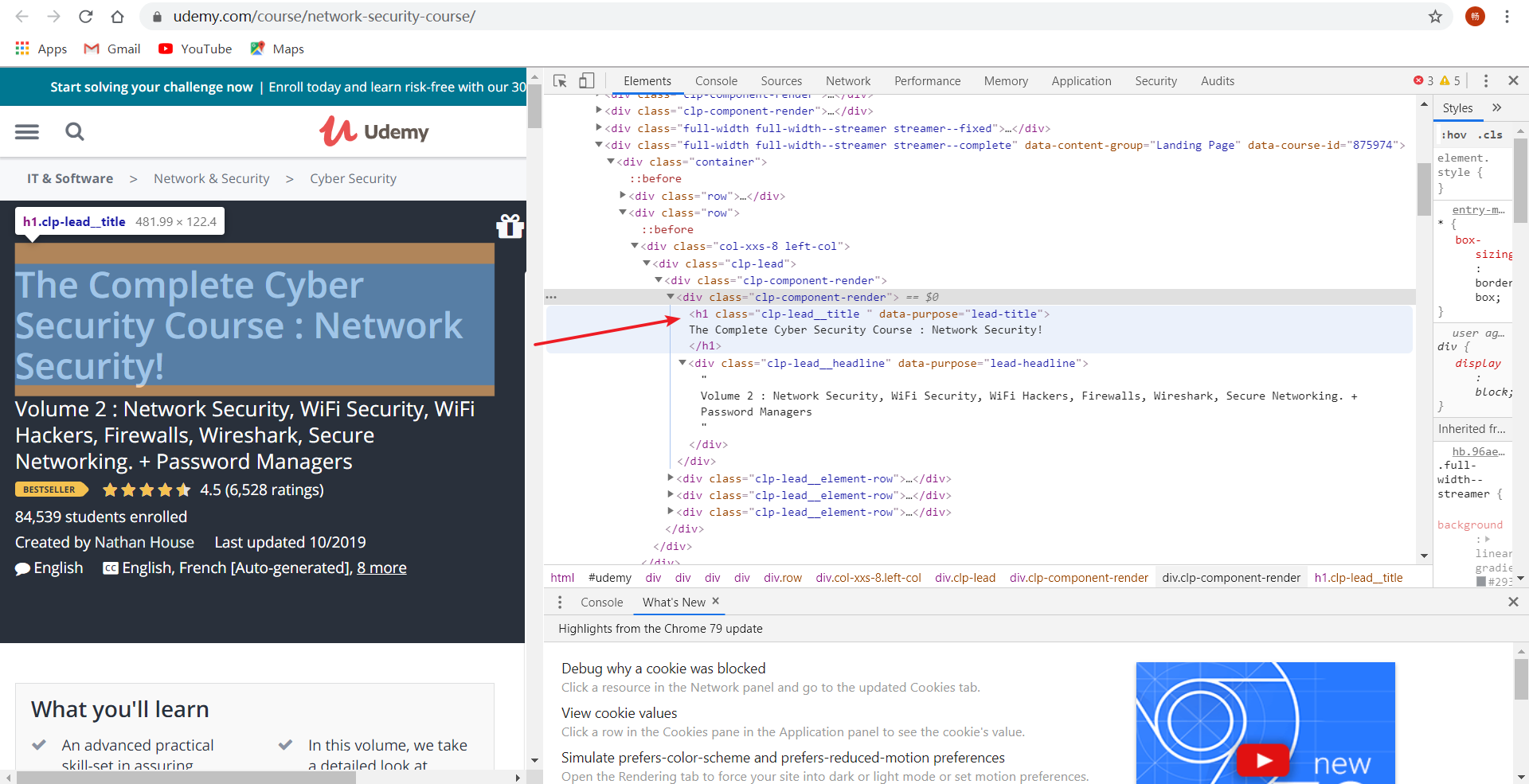
from selenium import webdriver
from bs4 import BeautifulSoup
url = 'https://www.udemy.com/course/network-security-course/'
#模拟浏览器请求网站
driver = webdriver.Chrome()
res = driver.get(url)
doc = BeautifulSoup(driver.page_source, 'html.parser')
course = doc.find('h1', class_='clp-lead__title').get_text().replace('
','')
print(course)
#关闭浏览器
driver.quit()
结果: