因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地
- 爬虫实现方式:
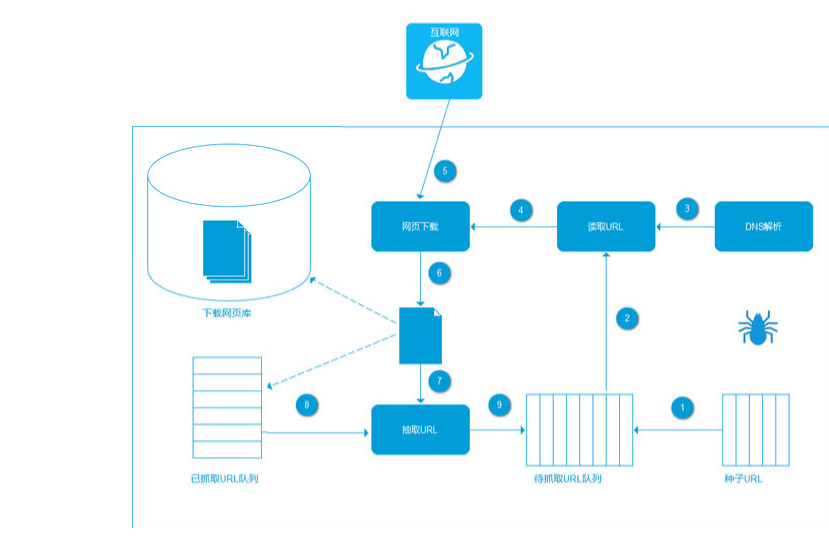
1.首先选取你需要的抓取的URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。(下面找的别人的图)

- 环境 :
- python
- re
- requests
- 正则:
pic_url = re.findall('"objURL":"(.*?)",',html, re.S)
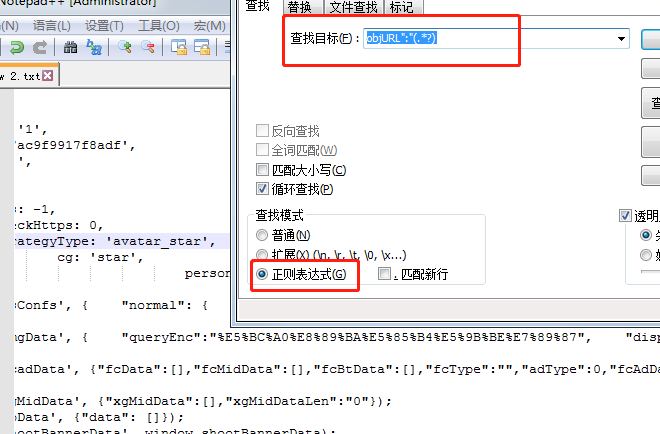
- 小技巧:这边的正则如果你不太确定有没有匹配到的话可以使用notepad++来匹配下
- 第一步查看你需要抓取网页右击查看源代码
- 第二步把代码贴入notepad++中
- 第三步f12查询选择正则进行匹配
- 也可用这个网址:http://tool.oschina.net/regex/#
- 废话不多说直接上代码
import re
import requests
def download(html):
#通过正则匹配
pic_url = re.findall('"objURL":"(.*?)",',html, re.S)
i = 1
for key in pic_url:
print("开始下载图片:"+key +"
")
try:
pic = requests.get(key, timeout=10)
except requests.exceptions.ConnectionError:
print('图片无法下载')
continue
#保存图片路径
dir = '保存路径' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
def main():
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word=lay'
result = requests.get(url)
download(result.text)
if __name__ == '__main__':
main()
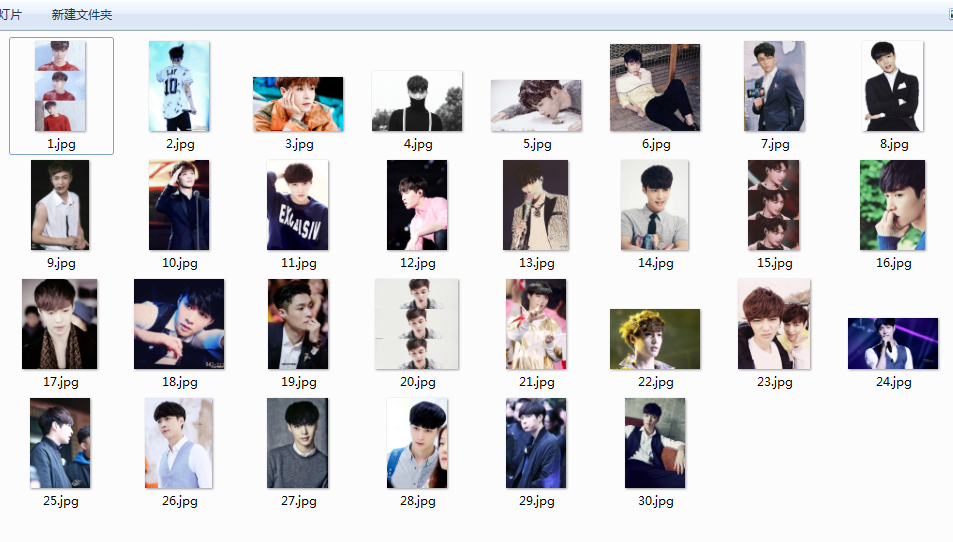
- 最后找到你下载图片的文件,然后看下小绵羊的盛世美颜