1. 目标:
对猫眼电影前100名的爬取,并将结果以文件的形式保存下来
2. 准备工作:
requests库
3. 抓取分析
offset代表偏移量值,分开请求10次,就可以获取前100的电影
4.抓取首页
5.正则提取
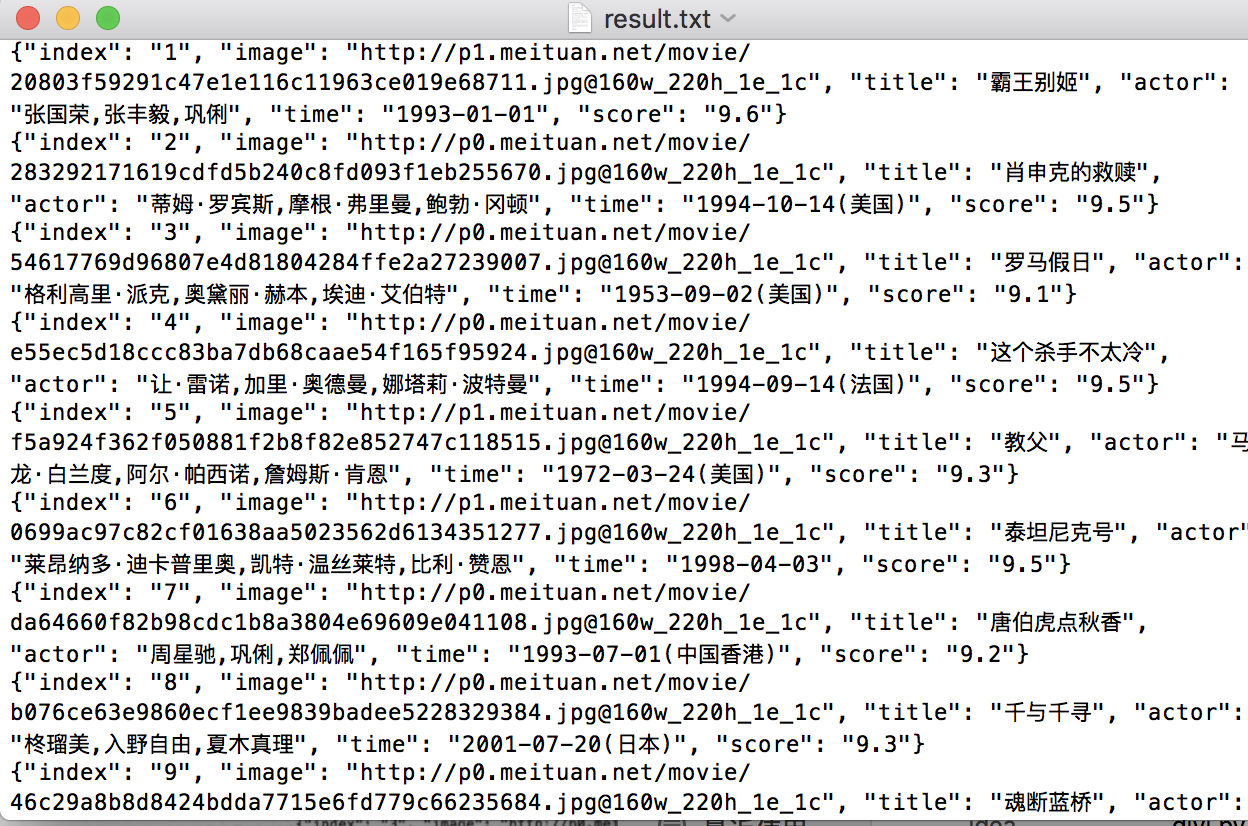
6.文件提取
7.代码整合
8.每页爬取
总代码:
1 import json 2 import requests 3 from requests.exceptions import RequestException 4 import re 5 import time 6 7 8 def get_one_page(url): 9 try: 10 headers = { 11 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36' 12 } 13 response = requests.get(url, headers=headers) 14 if response.status_code == 200: 15 return response.text 16 return None 17 except RequestException: 18 return None 19 20 21 def parse_one_page(html): 22 pattern = re.compile('<dd>.*?board-index.*?>(d+)</i>.*?data-src="(.*?)".*?name"><a' 23 + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>' 24 + '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S) 25 items = re.findall(pattern, html) 26 for item in items: 27 yield { 28 'index': item[0], 29 'image': item[1], 30 'title': item[2], 31 'actor': item[3].strip()[3:], 32 'time': item[4].strip()[5:], 33 'score': item[5] + item[6] 34 } 35 36 37 def write_to_file(content): 38 with open('result.txt', 'a', encoding='utf-8') as f: 39 f.write(json.dumps(content, ensure_ascii=False) + ' ') 40 41 42 def main(offset): 43 url = 'http://maoyan.com/board/4?offset=' + str(offset) 44 html = get_one_page(url) 45 for item in parse_one_page(html): 46 print(item) 47 write_to_file(item) 48 49 50 if __name__ == '__main__': 51 for i in range(10): 52 main(offset=i * 10) 53 time.sleep(1)