1. 数据库读写分离
读写分离,基本的原理就是让主数据库(master)处理事务性增、删、改操作(INSERT,DELETE,UPDATE),从数据库(slave)处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
主库负责写数据、读数据。读库仅负责读数据。每次有写库操作,同步更新cache,每次读取先读cache在读DB
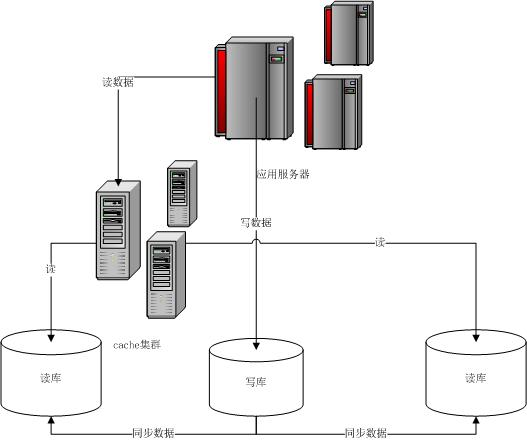
MySQL读写分离基本原理是让master数据库处理写操作,slave数据库处理读操作。master将写操作的变更同步到各个slave节点(解决主从数据库同步延迟问题)。

MySQL读写分离能提高系统性能的原因在于:
- 物理服务器增加,机器处理能力提升。拿硬件换性能。
- 主从只负责各自的读和写,极大程度缓解X锁和S锁争用。
- slave可以配置myiasm引擎,提升查询性能以及节约系统开销。
- master直接写是并发的,slave通过主库发送来的binlog恢复数据是异步。
- slave可以单独设置一些参数来提升其读的性能。
- 增加冗余,提高可用性。
MySQLProxy介绍
下面使用MySQL官方提供的数据库代理层产品MySQLProxy搭建读写分离。
MySQLProxy实际上是在客户端请求与MySQLServer之间建立了一个连接池。所有客户端请求都是发向MySQLProxy,然后经由MySQLProxy进行相应的分析,判断出是读操作还是写操作,分发至对应的MySQLServer上。对于多节点Slave集群,也可以起做到负载均衡的效果。

2.MySQL主从复制入门
首先,我们看一个图:
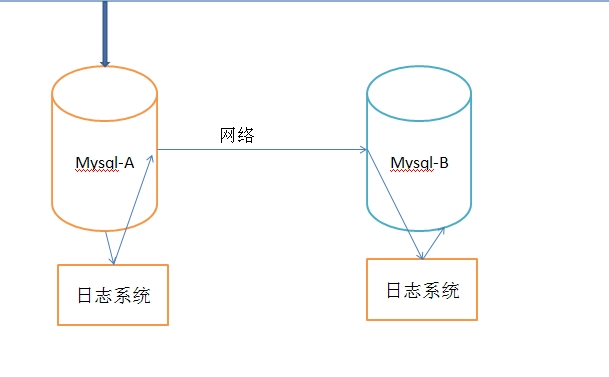
影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中。
假设,实时的将变化了的日志系统中的数据库事件操作,在MYSQL-A的3306端口,通过网络发给MYSQL-B。
MYSQL-B收到后,写入本地日志系统B,然后一条条的将数据库事件在数据库中完成。
那么,MYSQL-A的变化,MYSQL-B也会变化,这样就是所谓的MYSQL的复制,即MYSQL replication。
在上面的模型中,MYSQL-A就是主服务器,即master,MYSQL-B就是从服务器,即slave。
日志系统A,其实它是MYSQL的日志类型中的二进制日志,也就是专门用来保存修改数据库表的所有动作,即bin log。【注意MYSQL会在执行语句之后,释放锁之前,写入二进制日志,确保事务安全】
日志系统B,并不是二进制日志,由于它是从MYSQL-A的二进制日志复制过来的,并不是自己的数据库变化产生的,有点接力的感觉,称为中继日志,即relay log。
可以发现,通过上面的机制,可以保证MYSQL-A和MYSQL-B的数据库数据一致,但是时间上肯定有延迟,即MYSQL-B的数据是滞后的。
【即便不考虑什么网络的因素,MYSQL-A的数据库操作是可以并发的执行的,但是MYSQL-B只能从relay log中读一条,执行下。因此MYSQL-A的写操作很频繁,MYSQL-B很可能跟不上。】
3.主从复制的几种方式
同步复制
所谓的同步复制,意思是master的变化,必须等待slave-1,slave-2,...,slave-n完成后才能返回。
这样,显然不可取,也不是MYSQL复制的默认设置。比如,在WEB前端页面上,用户增加了条记录,需要等待很长时间。
异步复制
如同AJAX请求一样。master只需要完成自己的数据库操作即可。至于slaves是否收到二进制日志,是否完成操作,不用关心。MYSQL的默认设置。
半同步复制
master只保证slaves中的一个操作成功,就返回,其他slave不管。
这个功能,是由google为MYSQL引入的。
4.主从复制分析
问题1:master的写操作,slaves被动的进行一样的操作,保持数据一致性,那么slave是否可以主动的进行写操作?
假设slave可以主动的进行写操作,slave又无法通知master,这样就导致了master和slave数据不一致了。因此slave不应该进行写操作,至少是slave上涉及到复制的数据库不可以写。实际上,这里已经揭示了读写分离的概念。
问题2:主从复制中,可以有N个slave,可是这些slave又不能进行写操作,要他们干嘛?
可以实现数据备份。
类似于高可用的功能,一旦master挂了,可以让slave顶上去,同时slave提升为master。
异地容灾,比如master在北京,地震挂了,那么在上海的slave还可以继续。
主要用于实现scale out,分担负载,可以将读的任务分散到slaves上。
【很可能的情况是,一个系统的读操作远远多于写操作,因此写操作发向master,读操作发向slaves进行操作】
问题3:主从复制中有master,slave1,slave2,...等等这么多MYSQL数据库,那比如一个JAVA WEB应用到底应该连接哪个数据库?
当 然,我们在应用程序中可以这样,insert/delete/update这些更新数据库的操作,用connection(for master)进行操作,select用connection(for slaves)进行操作。那我们的应用程序还要完成怎么从slaves选择一个来执行select,例如简单的轮循算法。
这样的话,相当于应用程序完成了SQL语句的路由,而且与MYSQL的主从复制架构非常关联,一旦master挂了,某些slave挂了,那么应用程序就要修改了。能不能让应用程序与MYSQL的主从复制架构没有什么太多关系呢?可以看下面的图:
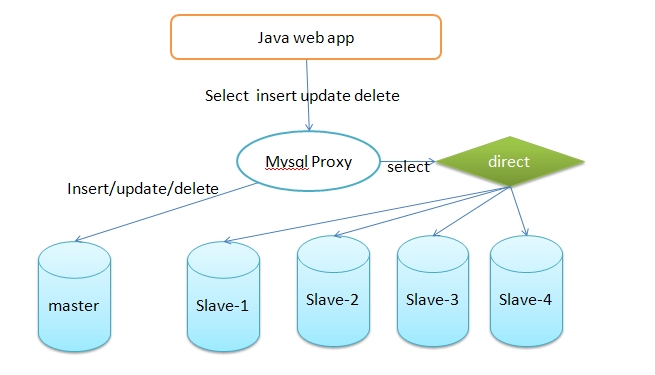
找一个组件,application program只需要与它打交道,用它来完成MYSQL的代理,实现SQL语句的路由。
mysql proxy并不负责,怎么从众多的slaves挑一个?可以交给另一个组件(比如haproxy)来完成。
这就是所谓的MYSQL READ WRITE SPLITE,MYSQL的读写分离。
问题4:如果mysql proxy , direct , master他们中的某些挂了怎么办?
总统一般都会弄个副总统,以防不测。同样的,可以给这些关键的节点来个备份。
问题5:当master的二进制日志每产生一个事件,都需要发往slave,如果我们有N个slave,那是发N次,还是只发一次?
如果只发一次,发给了slave-1,那slave-2,slave-3,...它们怎么办?
显 然,应该发N次。实际上,在MYSQL master内部,维护N个线程,每一个线程负责将二进制日志文件发往对应的slave。master既要负责写操作,还的维护N个线程,负担会很重。可 以这样,slave-1是master的从,slave-1又是slave-2,slave-3,...的主,同时slave-1不再负责select。 slave-1将master的复制线程的负担,转移到自己的身上。这就是所谓的多级复制的概念。
问题6:当一个select发往mysql proxy,可能这次由slave-2响应,下次由slave-3响应,这样的话,就无法利用查询缓存了。
应该找一个共享式的缓存,比如memcache来解决。将slave-2,slave-3,...这些查询的结果都缓存至mamcache中。
问题7:随着应用的日益增长,读操作很多,我们可以扩展slave,但是如果master满足不了写操作了,怎么办呢?
scale on ?更好的服务器? 没有最好的,只有更好的,太贵了。。。
scale out ? 主从复制架构已经满足不了。
可以分库【垂直拆分】,分表【水平拆分】。
5 数据库的垂直切分和水平切分
数据切分可以是物理上的,对数据通过一系列的切分规则将数据分布到不同的DB服务器上,通过路由规则路由访问特定的数据库,这样一来每次访问面对的就不是单台服务器了,而是N台服务器,这样就可以降低单台机器的负载压力。
数据切分也可以是数据库内的,对数据通过一系列的切分规则,将数据分布到一个数据库的不同表中,比如将article分为article_001,article_002等子表,若干个子表水平拼合有组成了逻辑上一个完整的article表,这样做的目的其实也是很简单的。 举个例子说明,比如article表中现在有5000w条数据,此时我们需要在这个表中增加(insert)一条新的数据,insert完毕后,数据库会针对这张表重新建立索引,5000w行数据建立索引的系统开销还是不容忽视的。但是反过来,假如我们将这个表分成100 个table呢,从article_001一直到article_100,5000w行数据平均下来,每个子表里边就只有50万行数据,这时候我们向一张只有50w行数据的table中insert数据后建立索引的时间就会呈数量级的下降,极大了提高了DB的运行时效率,提高了DB的并发量。当然分表的好处还不知这些,还有诸如写操作的锁操作等,都会带来很多显然的好处。
综上,分库降低了单点机器的负载;分表,提高了数据操作的效率,尤其是Write操作的效率。
