一、调度分类
调度分为两种,一是应用之间的,二是应用内部作业的。
(一)应用之间
我们前面几章有说过,一个spark-submit提交的是一个应用,不同的应用之间是有调度的,这个就由资源分配者来调度。如果我们使用Yarn,那么就由Yarn来调度。调度方式的配置就在$HADOOP_HOME/etc/hadoop/yarn-site.xml中
- <property>
- <name>yarn.resourcemanager.scheduler.class</name>
- <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
- </property>
(二)应用内部
参考《Spark基础入门(三)--------作业执行方式》可以看到,SparkContext底层会触发调用runJob的方法阻塞式的提交job,提交job的线程会处于阻塞状态,同一个线程中,后面的job需要等待前面job完成才能提交。但当多线程执行时,则可以并发提交Job。
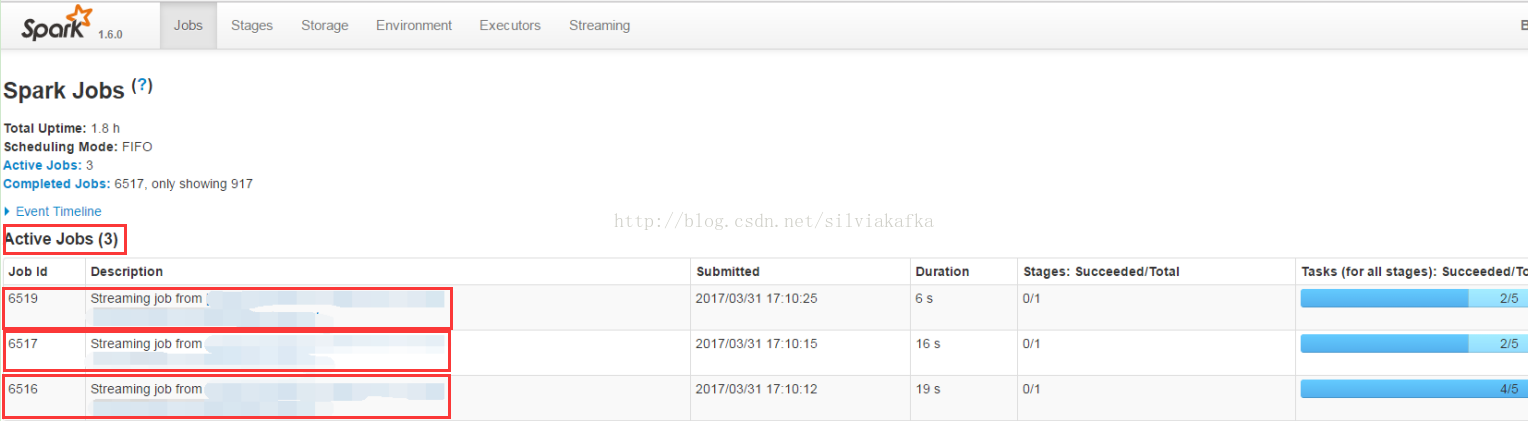
例如SparkStreaming运行并发提交时,可以看到一个SparkStreaming的项目中多个job在同时跑:
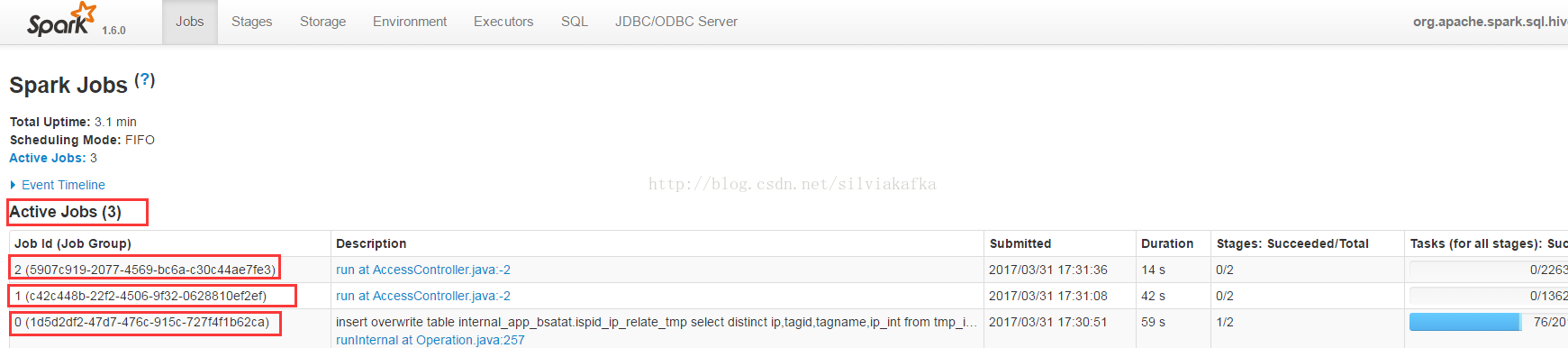
再例如Thriftserver,多个用户通过beeline连接Thriftserver提交自己的查询,所有的查询都是并行运行的:
我们重点介绍应用内部的调度,调度方式的配置在
$SPAKR_HOME/conf/spark-defaults.conf
- spark.scheduler.mode = FIFO/FAIR
二、调度原理
结合《Spark基础入门(三)--------作业执行方式》
(一)作业提交与调度池的创建
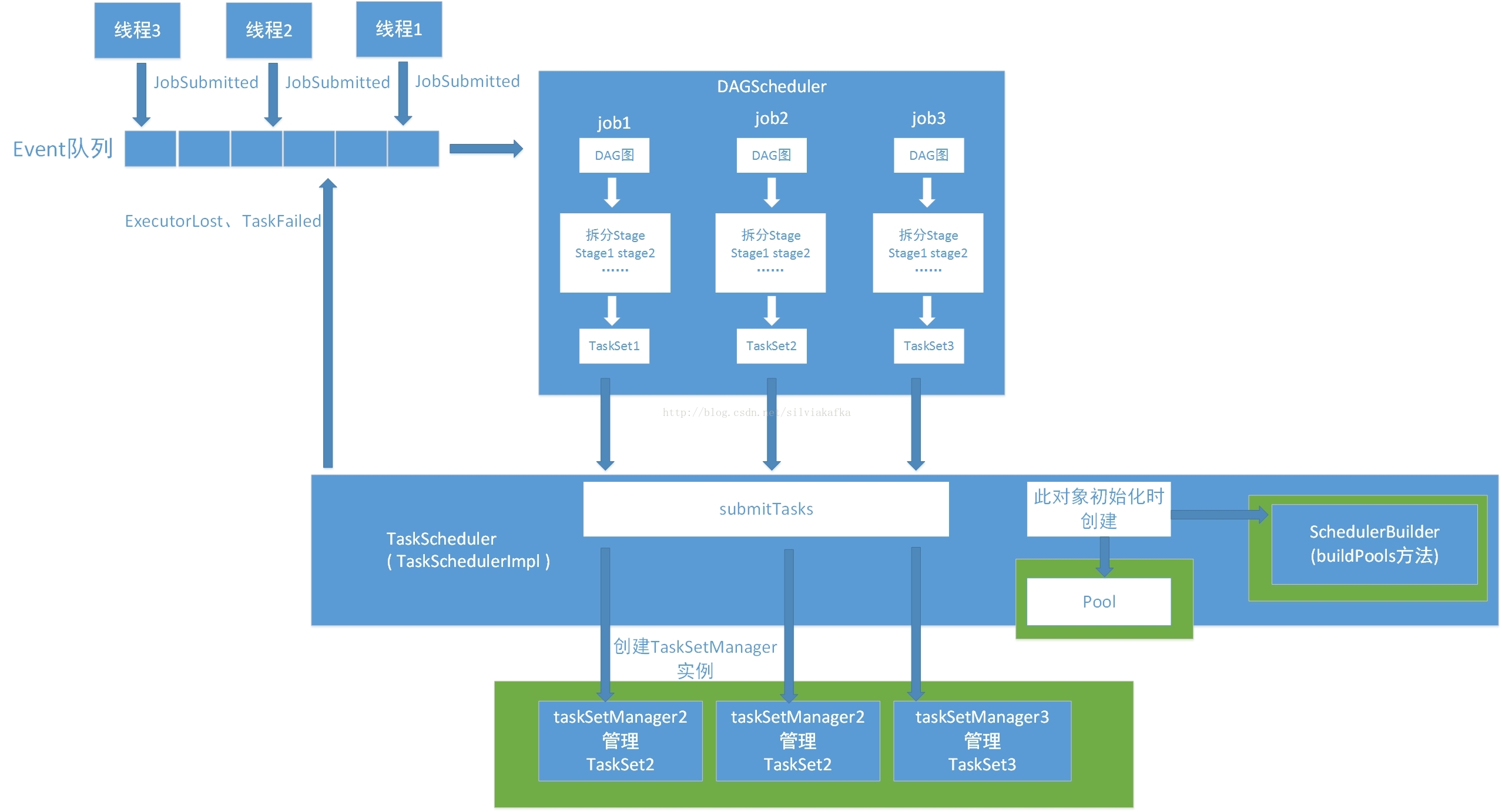
1. DAGScheduler采取的生产者消费者模型,存在一个Event队列,用户和TaskScheduler会生产event到这个队列中,DAGScheduler中会有一个Daemon线程去消费这些event并产生对应的处理。DAGScheduler可以处理的Event包括:JobSubmitted、CompletionEvent、ExecutorLost、TaskFailed、StopDAGScheduler。
2. DAGScheduler 在接收到JobSubmitted的Event之后,会首先计算出其DAG图,然后划分Stage,最后提交TaskSet到TaskScheduler(通过调用TaskScheduler的submitTasks,TaskScheduler还有cancelTasks的方法)
3. TaskScheduler的submitTasks方法最后会创建TaskManager的实例,由它去管理里面的TaskSet。
4. SparkContext是多线程安全的,可以有多个线程提交Job,这个Job也就是sparkAction
5. 每个线程提交Job时,是按Stage为最小单位来提交的,提交一个stage的TaskSet(一堆task任务)有一个TaskSetManager会来管理TaskSet,一个TaskSet对应一个TaskSetManager
6. TaskScheduler在初始化时,会创建一个Pool,用于调度;还会创建SchedulerBuilder,会去构造刚刚这个Pool。
7. SchedulerBuilder在TaskSchedulerImpl类中的定义如下,SchedulerBuilder会根据用户设定的调度模式(比如FIFO或者Fair)调用其buildPools方法,将下面的TaskSetManager按照一定的组织形式放到Pool中。上图绿色框图圈出来的部分。比如使用的FIFO,则以FIFOSchedulableBuilder类来build pool,如果使用FAIR,则使用FairChedulableBuilder
- var schedulableBuilder: SchedulableBuilder = null
- ...
- def initialize(backend: SchedulerBackend) {
- this.backend = backend
- // temporarily set rootPool name to empty
- rootPool = new Pool("", schedulingMode, 0, 0)
- schedulableBuilder = {
- schedulingMode match {
- case SchedulingMode.FIFO =>
- //rootPool包含了一组TaskSetManager
- new FIFOSchedulableBuilder(rootPool)
- case SchedulingMode.FAIR =>
- //rootPool包含了一组Pool树,这棵树的叶子节点都是TaskSetManager
- new FairSchedulableBuilder(rootPool, conf)
- }
- }
- schedulableBuilder.buildPools() //在FIFO中的实现是空
- }
(二)作业调度
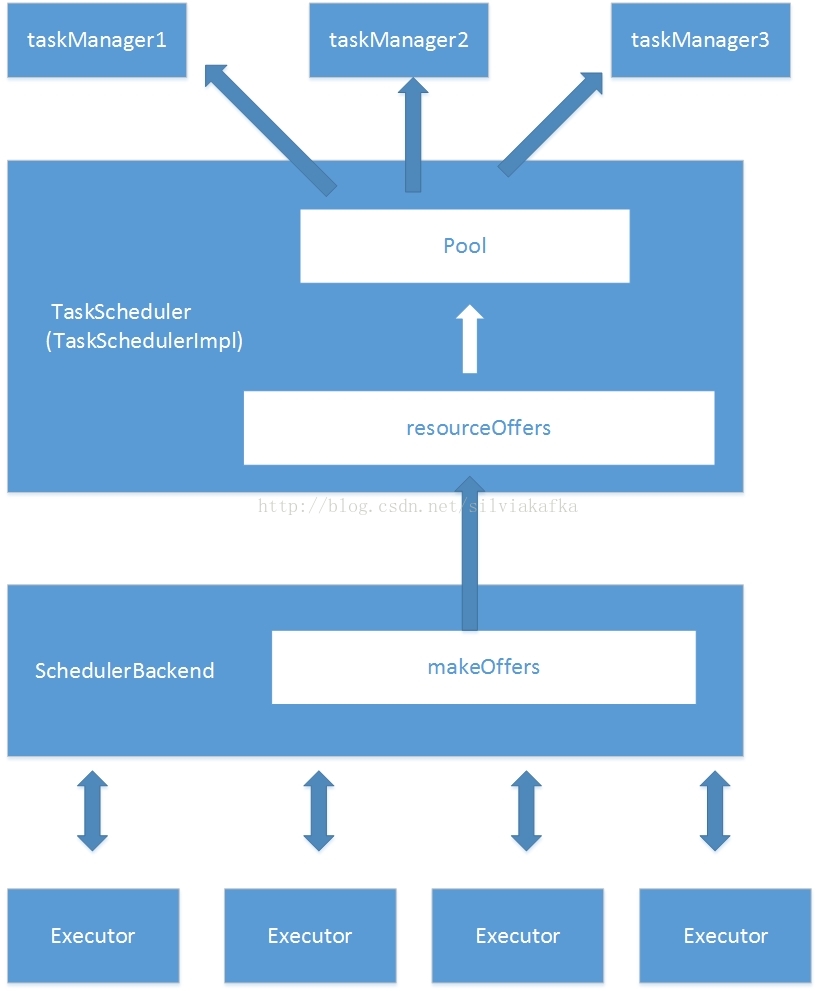
上述都是基础工作,pool和调度对象建立联系之后,才开始真正的调度。
1. 调度由TaskScheduler进行,只有在有新的计算资源时才会进行作业调度。
2. TaskScheduler后面还有SchedulerBackend,SchedulerBackend会负责与Executor交互。
3. SchedulerBackend会调用makeOffers,触发TaskScheduler调用resourceOffers方法。resourceOffers方法会根据当前的设置,选用一个调度算法,进行作业调度。
- var taskSetSchedulingAlgorithm: SchedulingAlgorithm = {
- schedulingMode match {
- case SchedulingMode.FAIR =>
- new FairSchedulingAlgorithm()
- case SchedulingMode.FIFO =>
- new FIFOSchedulingAlgorithm()
- }
- }
4. 有两种触发SchedulerBackend调用makeOffers的场景:
(1) 定时任务:SchedulerBackend在启动时会创建DriverEndPoint,DriverEndPoint中有定时任务,一定时间(spark.scheduler.revive.interval,默认为1s)进行一次调度(给自身发送ReviveOffers消息, 进行调用makeOffers进行调度)
(2)资源释放:当Executor执行完成已分配任务时,会向Driver发送StatusUpdate消息,表明一个Executor资源已经释放,则调用makeOffers(executorId)方法。
三、调度算法
(一)FIFO(First in first out)
三个线程提交三个Job,则按照顺序,先执行Job1,执行结束之后再执行Job2,然后再执行Job3。
1. buildPools算法
对于FIFO模式的调度,rootPool管理的直接就是TaskSetManager。SchedulerBuilder的buildPools方法会遍历所有的TaskSetManager,然后将他们直接挂在rootPool下面。
FIFO调度模式只有一层,会在叶子节点TaskSetManager中选择调度哪一个
- /**FIFO模式下的Pools的构建/
- private[spark] class FIFOSchedulableBuilder(val rootPool: Pool)
- extends SchedulableBuilder with Logging {
- override def buildPools() {
- // 实际什么都不做
- }
- //添加下级调度实体的时候,直接添加到rootPool
- override def addTaskSetManager(manager: Schedulable, properties: Properties) {
- rootPool.addSchedulable(manager)
- }
- }

2. 调度算法
- /**
- * FIFO排序的实现,主要因素是优先级、其次是对应的Stage
- * 优先级高的在前面,优先级相同,则靠前的stage优先
- */
- private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm {
- override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
- //优先级越小优先级越高
- val priority1 = s1.priority
- val priority2 = s2.priority
- var res = math.signum(priority1 - priority2)
- if (res == 0) {
- //如果优先级相同,那么Stage靠前的优先
- val stageId1 = s1.stageId
- val stageId2 = s2.stageId
- res = math.signum(stageId1 - stageId2)
- }
- if (res < 0) {
- true
- } else {
- false
- }
- }
- }
首先比较优先级
如果优先级相同,就比较Stage的大小。
在FIFO中,优先级即是JobID。而JobID是顺序生成的,所以也就是先生成的JobID比较小,参考代码可以看到优先级(JobID)越小,越先调度。
对同一个作业(Job)来说越先生成的Stage,其StageId越小,
有依赖关系的多个Stage之间,DAGScheduler会控制Stage是否会被提交到调度队列中(若其依赖的Stage未执行完前,此Stage不会被提交),其调度顺序可通过此来保证。但若某Job中有两个无入度的Stage的话,则先调度StageId小的Stage。
3. 实验
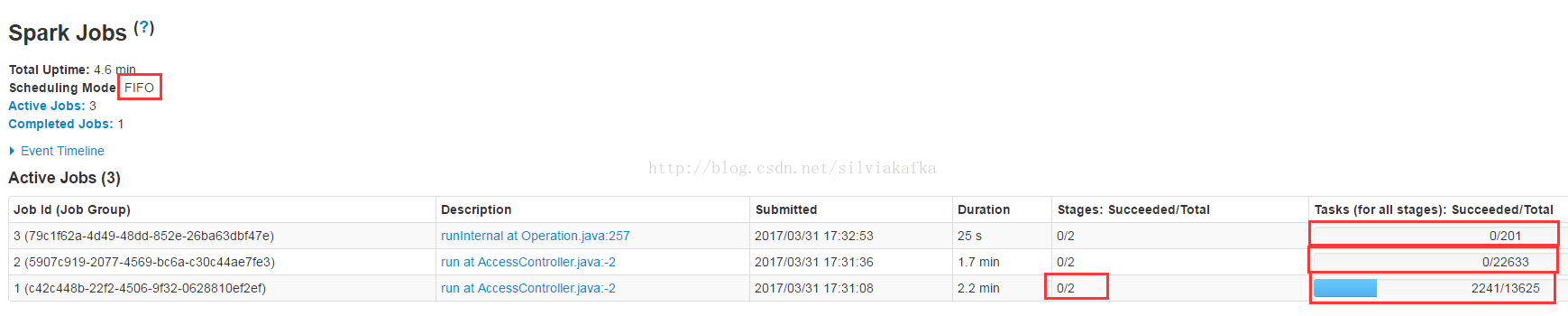
这个算法对外表现出来就是一个Job1先执行完了之后下一个Job2,那么如果Job1运行需要3个小时,而Job2运行只需要1分钟,结果Job2从提交到结束会需要3小时一分钟。非常不友好、不灵活。
(二)FAIR
首先配置$SPAKR_HOME/conf/spark-defaults.conf
- spark.scheduler.mode = FAIR
1. buildPools算法
- /**FAIR模式下的Pools的构建*/
- private[spark] class FairSchedulableBuilder(val rootPool: Pool, conf: SparkConf)
- extends SchedulableBuilder with Logging {
- ....省略代码...
- override def buildPools() {
- ...省略...
- buildDefaultPool()
- }
- private def buildDefaultPool() {
- if (rootPool.getSchedulableByName(DEFAULT_POOL_NAME) == null) {
- val pool = new Pool(DEFAULT_POOL_NAME, DEFAULT_SCHEDULING_MODE,
- DEFAULT_MINIMUM_SHARE, DEFAULT_WEIGHT)
- rootPool.addSchedulable(pool)
- ......
- }
- }
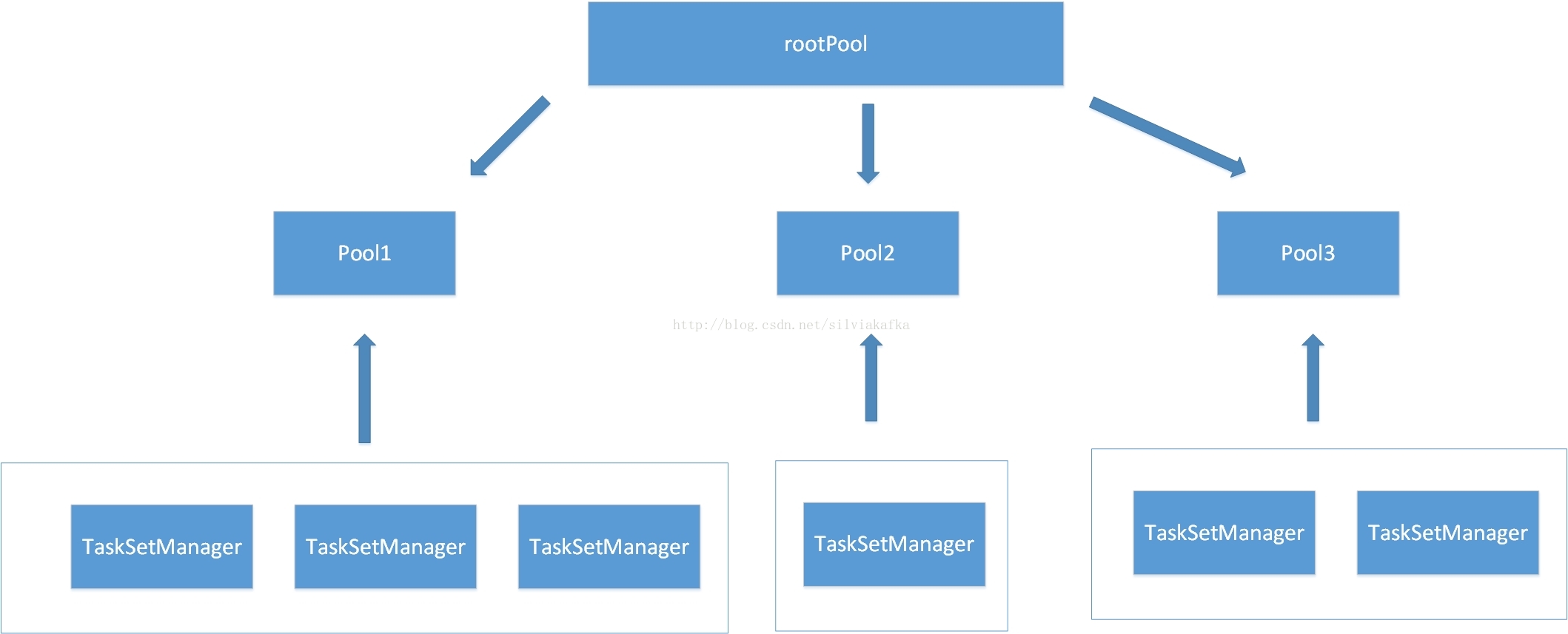
模型如上,Fair模型的调度是两级调度。rootPool下面管理的是其他pool,下面的pool才去管理TaskManager。
配置方式:
1)添加池子
添加$SPAKR_HOME/conf/fairscheduler.xml可以设置调度的多个池子,如果不设置,则默认底下只有一个defaultPool池子。
- <?xml version="1.0"?>
- <allocations>
- <pool name="default">
- <schedulingMode>FAIR</schedulingMode>
- <weight>1</weight>
- <minShare>0</minShare>
- </pool>
- <pool name="pool1">
- <schedulingMode>FAIR</schedulingMode>
- <weight>1</weight>
- <minShare>0</minShare>
- </pool>
- </allocations>
2)配置TaskSetManager与池子之间的关系
线程1提交了一个action,这个action触发了一个jobId为1的job,会交给TaskSetManager1来管理。
在提交这个action之前,代码中设置spark.scheduler.pool:
SparkContext.setLocalProperty(“spark.scheduler.pool”,”pool_name_1”)
注意这里的setLocalProperty,笔者认为应该是线程私有的对象。
如果不加设置,jobs会提交到default调度池中。由于调度池的使用是Thread级别的,只能通过具体的SparkContext来设置local属性(即无法在配置文件中通过参数spark.scheduler.pool来设置,因为配置文件中的参数会被加载到SparkConf对象中)。所以需要使用指定调度池的话,需要在具体代码中通过SparkContext对象sc来按照如下方法进行设置:
sc.setLocalProperty("spark.scheduler.pool", "test")
设置该参数后,在该thread中提交的所有job都会提交到test Pool中。
如果接下来不再需要使用到该test调度池,
sc.setLocalProperty("spark.scheduler.pool", null)
我们将不同线程提交的job给隔离到不同的池子里了
2. 调度算法
- private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
- override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
- //最小共享,可以理解为执行需要的最小资源即CPU核数
- val minShare1 = s1.minShare
- val minShare2 = s2.minShare
- //运行的任务的数量
- val runningTasks1 = s1.runningTasks
- val runningTasks2 = s2.runningTasks
- //运行中的任务的数量与最小CPU核数比较,如果小于,则说明处于饥饿状态
- val s1Needy = runningTasks1 < minShare1
- val s2Needy = runningTasks2 < minShare2
- //饥饿程度越大(runningTask远小于minshare),算出来的数值越小
- val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0).toDouble
- val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0).toDouble
- //权重越高,算出来的数值越小
- val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
- val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
- var compare: Int = 0
- //饥饿的优先
- if (s1Needy && !s2Needy) {
- return true
- } else if (!s1Needy && s2Needy) {
- return false
- } else if (s1Needy && s2Needy) {
- //都处于挨饿状态则饥饿程度越大的优先
- compare = minShareRatio1.compareTo(minShareRatio2)
- } else {
- //都不挨饿,则权重高的优先
- compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
- }
- if (compare < 0) {//小于0时,返回true
- true
- } else if (compare > 0) {//大于0时,返回false
- false
- } else {
- //如果都一样,那么比较名字,按照字母顺序比较,不考虑长度,所以名字比较重要
- s1.name < s2.name
- }
- }
- }
上述算法总结下来就是:
1.饥饿的优先(minShare)
2.都处于挨饿状态则饥饿程度越大的优先(running/minShare越小的优先)
3.都不挨饿,则权重程度高的优先(running/weight越小的优先)
4.算出来的值相同时,则比较名字(按照字母顺序比较)
3. 案例分析
20核分配
三个池子hello(minshare:5/weight:15), apple(minshare:2/weight:5), pool(minshare:3/weight:1)
初始状态:0<5 0<2 0<3
全部饥饿
饥饿程度 0% 0% 0%
按名字分配 1
饥饿程度 0% 1/2(50%) 0%
按名字 1
饥饿程度 0% 1/2(50%) 1/3(33.3%)
按饥饿程度1
饥饿程度 1/5(20%) 1/2(50%) 1/3(33.3%)
按饥饿程度1
饥饿程度 2/5(40%) 1/2(50%) 1/3(33.3%)
按饥饿程度2/5(40%) 1/2(50%) 2/3(66.7%)
按饥饿程度3/5(60%) 1/2(50%) 2/3(66.7%)
按饥饿程度3/5(60%) 2/2(100%) 2/3(66.7%)
按饥饿程度4/5(80%) 2/2(100%) 2/3(66.7%)
按饥饿程度4/5(80%) 2/2(100%) 3/3(100%)
按饥饿 5/5(100%) 2/2(100%) 3/3(100%)
此时已经分配10个核
全部不饥饿,权重程度 5/15(33.3%) 2/5(40%) 3/1(300%)
按权重程度6/15(40%) 2/5(40%) 3/1(300%)
按名字 6/15(40%) 3/5(60%) 3/1(300%)
按权重程度 7/15(46.7%) 3/5(60%) 3/1(300%)
按权重程度 8/15(53.3%) 3/5(60%) 3/1(300%)
按权重程度 9/15(60%) 3/5(60%) 3/1(300%)
按名字 9/15(60%) 4/5(80%) 3/1(300%)
按权重程度 10/15(66.7%) 4/5(80%) 3/1(300%)
按权重程度 11/15(73.3%) 4/5(80%) 3/1(300%)
按权重程度 12/15(80%) 4/5(80%) 3/1(300%)
按名字 12/15(80%) 5/5(100%) 3/1(300%)
此时20核全部分配完
如果用户配置一个指定调度池权重为2, 那么这个调度池将会获得相对于权重为1的调度池2倍的资源
4. 池子内部的调度
第一小层是Pool(资源池)间的公平调度,第二小层是Pool内的。注意,Pool内部调度默认是FIFO的,需要设置{spark_base_dir}/conf/fairscheduler.xml,针对具体的Pool设置调度规则
<pool name="default">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>0</minShare>
</pool>
但pool内已经没有minShare、weight了,所以笔者猜测pool内minShare全是0,weight全是1。然后也就是公平的平均分配所有的资源。
四、TaskSetManager内部调度
当资源已经分配给一个taskSetManager之后,再就是执行任务内部的调度逻辑。因为分配的资源是某个executor上的,每个Task又有自己prefer的节点(为了计算的本地性),他们之间可能不是完全的匹配。
例如资源executor(机器c上的)调度给了一个taskSetManager,而taskSetManager中此时只有a,b两个task(它们prefer的节点是a,b),那么如果此时将c资源给a task,那么a可能计算就是rack(机架中的),然后很短时间内,又有一个a资源调度过来,而此时只能把它给b task。而实际上最佳的方式应该是把a资源给a task,c资源给b task。
所以这里有一个等待机制,包括以下参数:spark.locality.wait.process、spark.locality.wait.node、spark.locality.wait.rack。TaskSetManager会根据等待时间降低自己的要求。(从process本地进程---->node本地节点---->rack同机架上---->any任意匹配)。这种等待机制会带来一定延迟,但如果这种调整有效那么也会节约很多计算时间(比如上例中,最后a上计算a task会比c上计算a task快很多)。
五、Thriftserver的调度
想要thriftserver达到SQL级别的公平调度,需要配置三个配置文件:yarn-site.xml、spark-defaults.conf、fairscheduler.xml。由于thriftserver的SQL没有按照不同用户区分多个Pool,所以其实并不能实现不同权重和minshare的设置,只能达到完全公平的分配(也就是(三)4)中提到的池子内的调度)。
但通过修改thriftserver的源码,可以实现不同sql分配到不同的池子里面,就可以实现sql级别的调度了。但池子必须提前配置好。
转载:https://blog.csdn.net/silviakafka/article/details/70735221