提示:本学习来自Ehco前辈的文章, 经过实现得出的笔记。
目标
http://tieba.baidu.com/f?kw=linux&ie=utf-8
网站结构
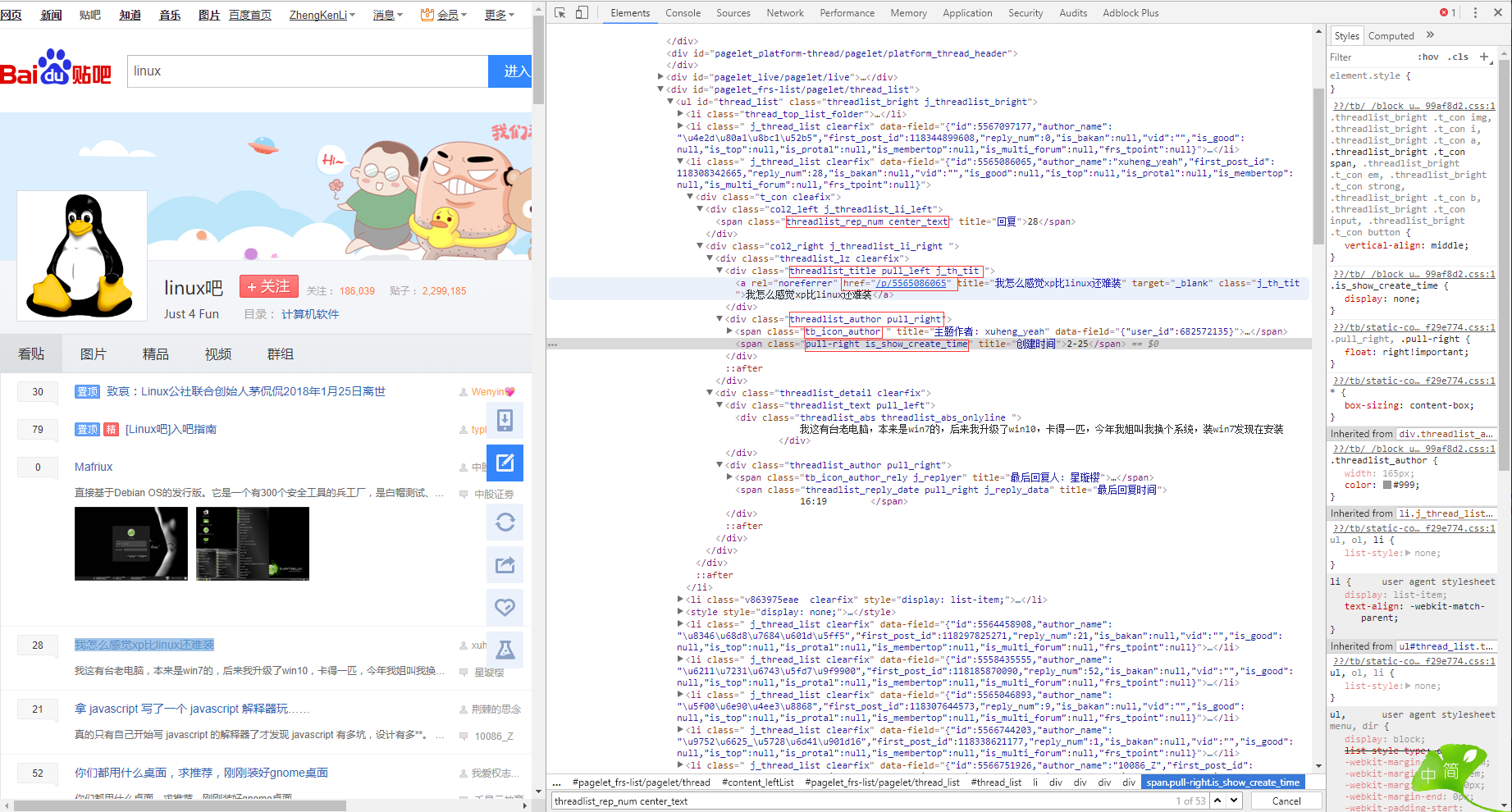
学习目标
由于是第一个实验性质爬虫,我们要做的不多,我们需要做的就是: 1. 从网上爬下特定页码的网页 2. 对于爬下的页面内容进行简单的筛选分析 3. 找到每一篇帖子的 标题、发帖人、日期、楼层、以及跳转链接 4. 将结果保存到文本。
发现规律
&pn=0 : 首页 &pn=50: 第二页 &pn=100:第三页 &pn=50*n 第n页 50 表示 每一页都有50篇帖子。
这样就能实现翻页操作
附上代码
import requests
import time
from bs4 import BeautifulSoup
def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return "error"
def get_content(url):
comments = []
html = get_html(url)
soup = BeautifulSoup(html, 'lxml')
liTags = soup.find_all('li', attrs={'class':' j_thread_list clearfix'})
for li in liTags:
comment = {}
try:
#标题
comment['title'] = li.find(
'a', attrs={'class':'j_th_tit '}).text.strip()
#链接
comment['link'] = "http://tieba.baidu.com/" +
li.find('a', attrs={'class' : 'j_th_tit'})['href']
#发帖人
comment['name'] = li.find(
'span', attrs = {'class':'tb_icon_author '}
).text.strip()
#发帖时间
comment['time'] = li.find(
'span', attrs={'class':'pull-right is_show_create_time'}
).text.strip()
#回复数量
comment['replyNum'] = li.find(
'span', attrs={'class':'threadlist_rep_num center_text'}
).text.strip()
comments.append(comment)
except:
print("出了点小问题")
return comments
def Out2File(dict):
with open('TTBT.txt', 'a+') as f:
for comment in dict:
f.write('标题: {} 连接: {} 发帖人: {} 发帖时间: {} 回复数量: {}
'.format(
comment['title'], comment['link'], comment['name'], comment['time'], comment['replyNum']
))
print("当前页面爬取完成")
def main(base_url, deep):
url_list = []
for i in range(0, deep):
url_list.append(base_url + '&pn' + str(50 * i))
print("所有的网页已经下载到本地! 开始筛选信息")
for url in url_list:
content = get_content(url)
Out2File(content)
print("所有的信息都已经保存完毕")
base_url = 'http://tieba.baidu.com/f?kw=linux&ie=utf-8'
deep = 3
if __name__ == '__main__':
main(base_url, deep)
结果

