1.词法分析程序的功能:
输入:所给文法的源程序字符串。
输出:二元组构成的序列。
其中:syn为单词种别码。
token为存放的单词自身字符串。
2.符号与种别码的对照表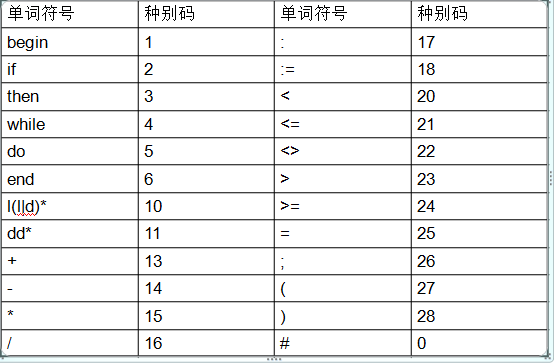
3.词法规则
<字母> A a|b|c|……y|z
<数字>
A→1|2|3|4|5|6|7|8|9
S→A|SA|SA0
<整数常数>
A→1|2|3|4|5|6|7|8|9
S→A|SA|SA0
<标识符>
A→a|b|c|……y|z
B→0|1|2|3|4|5|6|7|8|9
S→A|SB
<关键字>
S→if|else|while|do|for|int|char|……
<运算符>
S→+|-|x|/|=|#|<|>|<=|>=|:=
<界符>
S→(|)|,|;|.
4.源代码与调试程序截图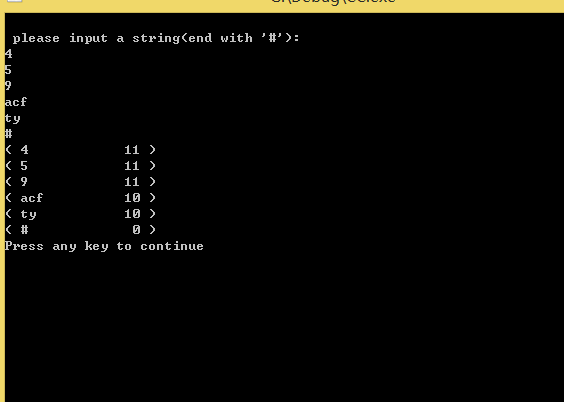
#include <stdio.h> #include <string.h> char prog[80],token[8],ch; int syn,p,m,n,sum; char *rwtab[6]={"begin","if","then","while","do","end"}; void scaner(void); main() { p=0; printf("\n please input a string(end with '#'):\n"); do{ scanf("%c",&ch); prog[p++]=ch; }while(ch!='#'); p=0; do{ scaner(); switch(syn) { case 11: printf("( %-10d%5d )\n",sum,syn); break; case -1: printf("you have input a wrong string\n"); //getch(); return 0; break; default: printf("( %-10s%5d )\n",token,syn); break; } }while(syn!=0); return 0;//getch(); } void scaner() { sum=0; for(m=0;m<8;m++) token[m]=0; ch=prog[p++]; m=0; while((ch==' ')||(ch=='\n')) ch=prog[p++]; if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A')))//可能是标示符或者变量名 { while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) //找到一个变量名或者关键字,直到遇到空格为止 { token[m++]=ch; ch=prog[p++]; } p--; syn=10; for(n=0;n<6;n++) //将识别出来的字符和已定义的标示符作比较 if(strcmp(token,rwtab[n])==0) { syn=n+1; break; } } else if((ch>='0')&&(ch<='9')) //数字 { while((ch>='0')&&(ch<='9')) { sum=sum*10+ch-'0'; //将字符串转换成数字 ch=prog[p++]; } p--; syn=11; } else { switch(ch) //其它字符 { case '<': token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=22; token[m++]=ch; } else { syn=20; p--; } break; case '>': token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=24; token[m++]=ch; } else { syn=23; p--; } break; case '+': token[m++]=ch; ch=prog[p++]; if(ch=='+') { syn=17; token[m++]=ch; } else { syn=13; p--; } break; case '-': token[m++]=ch; ch=prog[p++]; if(ch=='-') { syn=29; token[m++]=ch; } else { syn=14; p--; } break; case '!': ch=prog[p++]; if(ch=='=') { syn=21; token[m++]=ch; } else { syn=31; p--; } break; case '=': token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=25; token[m++]=ch; } else { syn=18; p--; } break; case '*': syn=15; token[m++]=ch; break; case '/': syn=16; token[m++]=ch; break; case '(': syn=27; token[m++]=ch; break; case ')': syn=28; token[m++]=ch; break; case '{': syn=5; token[m++]=ch; break; case '}': syn=6; token[m++]=ch; break; case ';': syn=26; token[m++]=ch; break; case '\"': syn=30; token[m++]=ch; break; case '#': syn=0; token[m++]=ch; break; case ':': syn=17; token[m++]=ch; break; default: syn=-1; break; } } token[m++]='\0'; }