1.选一个自己感兴趣的主题。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
我的主题:爬取腾讯体育-NBA
按F12使用开发者工具分析腾讯体育NBA新闻网站的结构,找到需要的类名字“list01”,爬取新闻标题和链接。
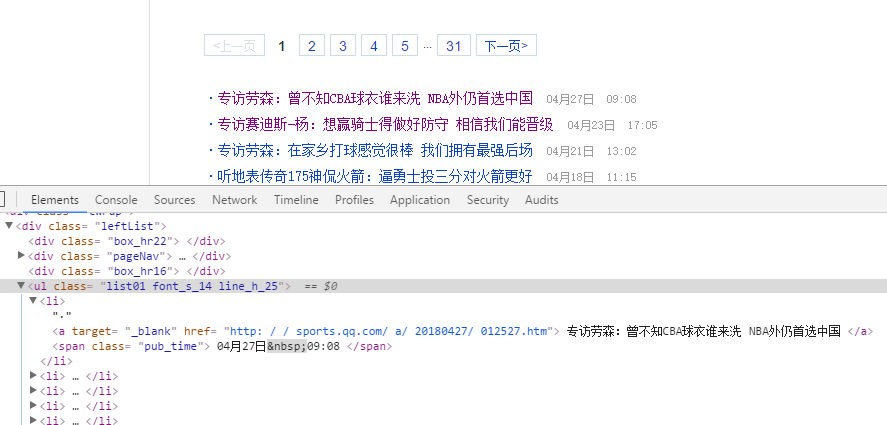
点开一条新闻链接,继续分析,找到需要的文章内容类名,然后进行分词分析。
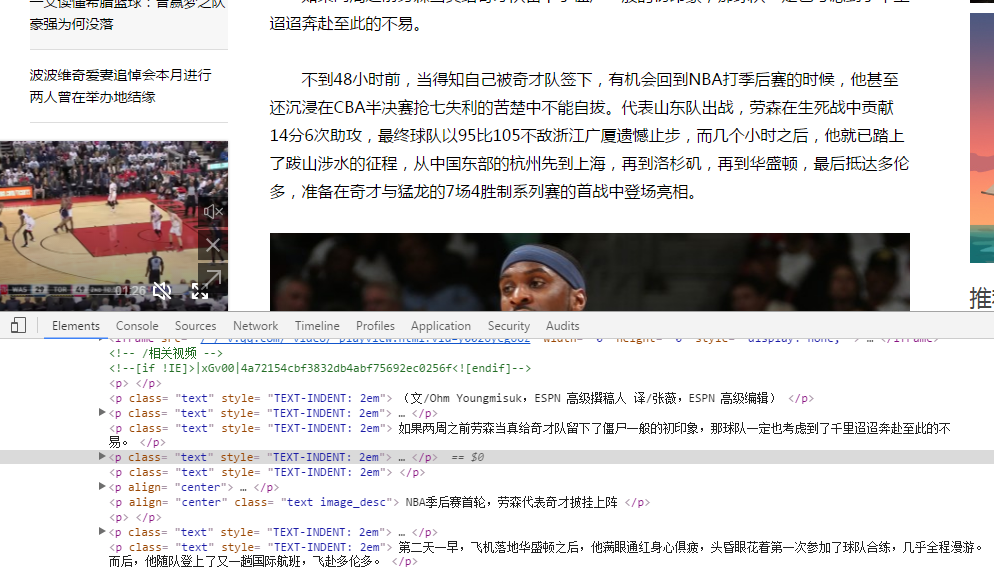
在实现的过程中遇到过不少问题,例如字符集charset,一开始使用了utf-8,结果出现乱码,后经查看网站结构解决,本网站使用的charset是gb2312。
还有一些调用参数问题等等。还有词云的字体问题,通过查询一些通用字体格式,最终实现。
词云效果图下:

最后提交爬取的全部数据、爬虫及数据分析源代码:
import requests from bs4 import BeautifulSoup import re import jieba # from PIL import Image,ImageSequence # import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud # 将词云写入到文件 def writeFile(keynews): f = open('cgpword.txt', 'a', encoding='utf-8') for word in keynews: f.write(" "+word) f.close() def getWordCloud(): keywords = open('cgpword.txt', 'r', encoding='utf-8').read() wc = WordCloud(font_path='C:windows/font/simkai.ttf', background_color='white', max_words=150).generate(keywords).to_file("cgp1.jpg") plt.imshow(wc) plt.axis('off') plt.show() #对新闻内容进行分词分析 def getnewsdetail(newsurl): resDescript = requests.get(newsurl) resDescript.encoding = "gb2312" soupDescript = BeautifulSoup(resDescript.text, 'html.parser') to = len(soupDescript.select(".text")) content = '' for p in range(0, to): content += soupDescript.select('.text')[p].text + ' ' # print(content) words = jieba.lcut(content) wcdict = {} keynews = [] for i in set(words): wcdict[i] = words.count(i) delete = {'你', '我', '他', '都', '已经', '着', '不', '她', '没有', '和', '他们', '中', '下', '什么', '一', '个', '道', '的', '们', '所', '在', '来', '有', '过', '从', '而', '才', '要', '因', '为', '地', '将', '上', '共', '自', '是', '令', '但', '被', '就', '也', '说', '语', '呀', '啊', '个', '人', '里', '罢', '内', '该', '与', '会', '对', '去', '出', '动', '却', '超', '已', '只', '放', '这', '比', '还', '则', '见', '到', '最', '话', '加', '更', '并', '把', '儿', '大', '小', '那', '很', ' ', '了', '-', ' ', ',', '。', '?', '!', '“', '”', ':', ';', '、', '.', '‘', '’'} for i in delete: if i in wcdict: del wcdict[i] sort_word = sorted(wcdict.items(), key=lambda d: d[1], reverse=True) # 排序 for dict in sort_word: keynews.append(dict[0]) writeFile(keynews) #获取该网站的所有新闻标题和链接 def getnewslist(newsurl): res = requests.get(newsurl) res.encoding = 'gb2312' soup = BeautifulSoup(res.text, 'html.parser') for newsList in soup.select('.list01')[0].select('li'): title = newsList.select('a')[0].text newsurl = newsList.select('a')[0]['href'] print(' 标题:{0} 新闻链接:{1} '.format(title, newsurl)) getnewsdetail(newsurl) url = "http://sports.qq.com/l/basket/original/qqinterview/list20150821155646.htm" resn = requests.get(url) resn.encoding = 'utf-8' soupn = BeautifulSoup(resn.text,'html.parser') getnewslist(url) for i in range(1, 3): if (i == 1): getnewslist(url) else: newsurl = "http://sports.qq.com/l/basket/original/qqinterview/list20150821155646_{}.htm".format(i) getnewslist(newsurl) getWordCloud()