MergeTree存储的文件结构
一张数据表被分成几个data part,每个data part对应文件系统中的一个目录。通过以下SQL可以查询data parts的信息。
select table, name, path, active, * from `system`.parts where table = '<table name>'
是一个目录,里面的文件结构如下:
- <data part 1>
○ checksums.txt
○ columns.txt
○ <column>.bin
○ <column>.mrk
○ count.txt
○ primary.idx
○ [partition.dat]
○ [minmax_<column>.idx]
○ [skp_idx_<column>.idx]
○ [skp_idx_
- <data part 2>
○ ……
○ ……
- <data part 3>
○ ……
○ ……
Part目录
数据存在Part目录中,一次批量Insert就会产生一个Part。多个Part从属于一个Partition,一个Partition的Parts会在后台合并。Parts目录的命名能反映其所属的Partition和记录ID范围:
<Partition ID>_<Min ID>_<Max ID>_<Level>
PartitionID是分区的键,可以是一个列也可以是多列。
Min ID,Max ID表示这个Part中的数据的最小ID和最大ID,构建出一个范围。Level是层级的概念,是自增的,可以理解成每次更新操作都相当于加了一”层“。
Parts会在后台按照Partition合并,这点很重要。
参考代码src\Storages\MergeTree\MergeTreeData.h
[column].bin | data.bin
存放某一列的真实数据的文件,当采用wide part模式时会为每一列生成这样的文件,文件名就是列的名字。
另外一种模式是compact part模式,这种模式下所有的列的数据放在一个文件data.bin里面。
当数据的压缩之前的原始大小超过阈值min_bytes_for_wide_part,或者数据行数超过阈值min_rows_for_wide_part 时,就会采用wide part模式,否则采用compact part模式。
.bin文件里面的数据是以block为单位存放,block可能是压缩的也可能不压缩。这个是根据clickhouse的参数max_compress_block_size 和 min_compress_block_size 决定的。如果决定要压缩,默认使用lz4压缩格式压缩。
block分为两个组成部分:
- header
header占9个字节,分别是:- [0] 编码器,比如lz4
- [1-4] 整个block压缩后的大小
- [5-8] 整个block压缩前的大小
- [9-24] checksum
- data
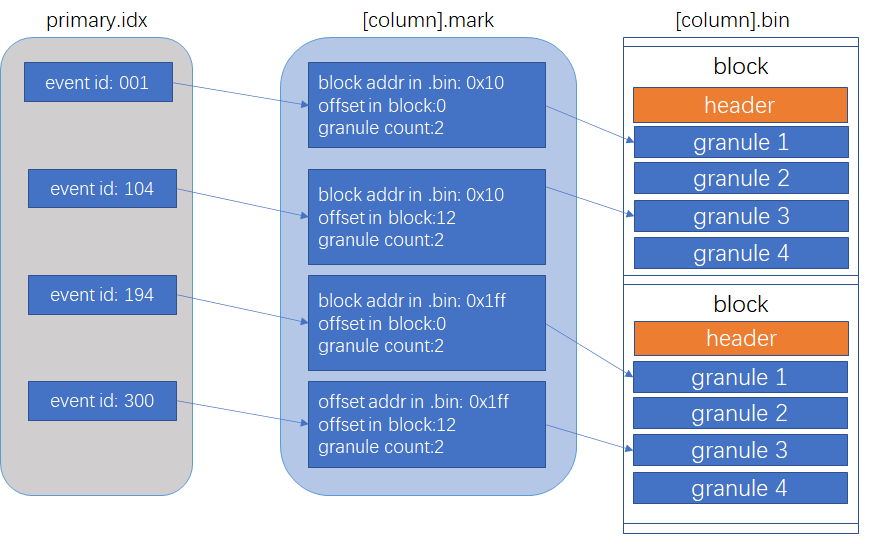
一个mark指向指向一个granule(颗粒)的第一行的位置,包含两个信息:1. block在文件中的相对位置;2. 在block中的相对位置。
Granule是一个概念,可以理解成数据颗粒,每个颗粒包含一列的若干行数据,数量一般情况由index_granularity设置决定。
[column].mrk
当需要读取某个范围内的数据时,例如读取主键10002000的某列数据,没有必要把主键01000以及主键2000以上的数据全部读到内存里来。.mrk文件(mark文件 / 标记文件)的引入就是为了解决这个最基本的问题的。
mark文件维持一个从mark到一组连续的granule(granule range)的映射,granule是属于某个block,一个block包含多个granule。存储的信息如下:
- offset_in_compressed_file:对应的block在压缩后的.bin文件的偏移量,由于实际的.bin文件里面就是存放压缩后的内容,也就可以理解成block块在.bin文件中的偏移位置。通过这个信息可以快速地读取block的内容。
- offset_in_decompressed_block:对应的第一个granule在解压缩后的block中的偏移量。block从磁盘中读取并解压缩到内存中以后,需要定位到granule的位置,这个信息就是用来快速定位到对应的granule在block中的偏移位置的。
以下是对应的实现类``的实际代码。它保存两个long值,一个是block的offset,一个是block内的offset。
size_t offset_in_compressed_file;
size_t offset_in_decompressed_block;
Mark的引入使得索引不需要映射到具体的行,而是需要大致范围地映射到某个mark上,减小了索引文件,减少了索引项,减少了IO(回想一般数据库中的B+树的索引),加快了搜索速度。clickhouse的索引指向的是mark,而mark是代表一列的n行数据,而不是一条数据,因此clickhouse里的索引也称为稀疏索引。
参考代码:src\Compression\CompressedReadBufferFromFile.cpp,src\Formats\MarkInCompressedFile.h
primary.idx
在Clickhouse中,primary key是order by的列或者是多列的order by的前部分,数据又是根据order by来存储,因此clickhouse中的数据的primary key在存储中总是有序的。primary.idx 作为主索引,维护的是 primary key -> mark的映射,主索引中不会存放所有的主键,更不会维持所有的主键到mark的映射关系。但是因为其存放的主键都是有序的,因此可以通过二分查找快速定位到需要的主键在哪个mark上。
例如下图的primary index,如果要找primary key = 5 的某列数据,则通过二分查找,我们知道primary key = 7以及大于7的和primary key = 1以及小于1的肯定不是要找的范围,因此要找的数据只会在primary key = 4 对应的mark上(由于一般是按照primary key由小到大排序,因此primary = 4 实际上是对应的mark上的数据中最小的primary key)。
skp_idx_[column].idx & skp_idx_[column].mrk
Skipping index 为跳数索引,也是一种稀疏索引。目的是跳过无用区域缩小查询范围,提升查询效率。Skipping index分为几类:
-
minmax
范围查询,包括相等查询时排除不可能的数据范围。 -
set(max rows)
用于相等查询。 -
ngram bloom filter
按ngram算法分词的布隆过滤器,快速确认要找的数据不在某个或某几个连续的granule上。
-
token bloom filter
跟ngram bloom filter差不多,只是按照标点符号分词。
Skipping index是从index key指向mark,例如{min, max} -> mark;{bloom filter} -> mark。
columns.txt
记录列的信息,包括名称、类型。
count.txt
记录当前分区Data part的数据总行数。
default_compression_codec.txt
保存block的压缩算法。
Partition.dat
保存一个值,就是partition的编号,从0开始。
Partition 合并
每次插入数据的操作都会产生一个新的partition目录,因此clickhouse周期性地或者人为强制触发分区合并的操作。分区合并就是把多个相同的Partition ID的partition目录合并为一个目录,因为原本这些数据就是属于一个partition的。
强制触发合并partition是通过optimize命令完成的,例如:
optimize table <table name> [final]
默认情况下是一次合并一部分,避免全部合并阻塞clickhouse其他操作。如果要一次全部合并所有,则要加final
很显然合并之后的partition包含原来的partition的所有数据,因此新合并后的partition目录的名字是:
PartitionID_{所有MinBlockNum中的最小}_{所有MaxBlockNum中的最大}_{自增的Level}
Level是自增的,每次合并增一。