注:本系列所有博客将持续更新并发布在github上,您可以通过github下载本系列所有文章笔记文件
1 引言
线性回归算法应该是大多数人机器学习之路上的第一站,因为线性回归算法原理简单清晰,但却囊括了拟合、优化等等经典的机器学习思想。去年毕业时参加求职面试就被要求介绍线性回归算法,但由于当初过于追求神经网络、SVN、无监督学习等更加高大尚的算法,反而忽略了线性回归这些基础算法,当时给出的答案实在是差强人意。
这一篇关于线性回归的总结我也犹豫过要不要写,如果你看了我上两篇关于最小二乘和梯度下降算法介绍的博客,你就会发现,关于最小二乘法和梯度下降算法的介绍都是以线性回归为例展开,所以,综合来说,之前两篇博文对一元线性回归还是多元线性回归算法都已经有了还算全面的总结,再写一篇关于线性回归的文章总感觉有些多余。不过,为了让我对机器学习的总结更加系统,还是决定专门总结一下。
2 什么是线性回归
说到线性回归,我们得先说说回归与分类、线性与非线性这些概念的区别。
回归和分类都是有监督学习(机器学习分有监督学习和无监督学习)中的概念。从算法的目标或者作用上看,分类的目标就如同字面上的意思,就是分类,将数据分门别类,而且类别是有限的(数学上称为离散的)。但回归算法不同,回归算法的目标是预测,说详细些就是从已有数据和结果中获取规律,对其它数据的位置结果进行预测,预测结果的数量数无限的(数学上叫连续的)。举个例子我们可以根据楼房的建材、面积、用途将茅草房、普通住房、厂房等等有限的几类,这就是分类;另外,我们可以根据房屋面积、地段、装修等因素对楼房房价进行预测,预测结果有无限种可能,可能是10000元/平米,也能是10001.1元/平米——这就是回归的过程。
对于线性和非线性的解释,我至今还没有见到过一个让我觉得满意的数学定义,所以,我也从直观认识上说说我的看法。我们高中时学习函数就是从一元一次函数学起的,一元一次函数在数学上可以表示为:
在二维坐标轴上,其表现为一条直线。如果是三维空间中的二元一次函数,数学上表示为:
其在空间上图形为一平面。以此类推,在更高维(n维)的平面上,多元一次函数表达式为:
[f(x)={{ heta }_{0}}+{{ heta }_{1}}{{x}_{1}}+{{ heta }_{2}}{{x}_{2}}+ldots +{{ heta }_{n}}{{x}_{n}}]
在多维空间上,其图形我们称为为超平面。
如果一个数据模型能够用上述二维直线、三维平面或者更多维空间上的超平面去拟合,我们就可以说这个模型是线性模型。
最后,综合上面内容总结一下什么是线性回归:
线性回归(Linear Regression)是一种通过属性的线性组合来进行预测的回归模型,其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真实值之间的误差最小化。
3 最优解
上面提到,线性回归的目的就是找到一个线性模型,是的预测值与真实值之间的误差最小,这就是一个优化的问题。为什么要优化呢?看看下图:
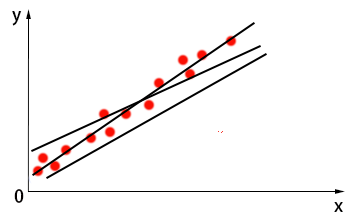
正如你眼前所见,图中的点代表数据,能够对这些数据点进行大概拟合的直线不止一条,到底哪一条才是最好呢?以上图中数据为例,假设此时模型为${y}'=f(x)={{ heta }_{0}}+{{ heta }_{1}}{{x}_{1}}$,图像如下所示,我们要对其拟合程度进行评价:
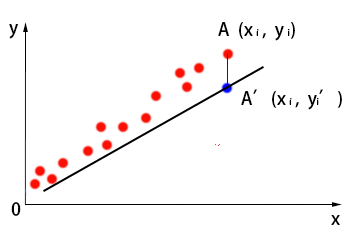
点$A({{x}_{i}},{{y}_{i}})$为数据集中某一点,使用模型预测时,结果为${A}'({{x}_{i}},{{{{y}'}}_{i}})$。我们用高中时学过,对于${A}$与${A}'$之间的误差,我们可以用它们之间的欧氏距离的平方来表示:
这是对一个点的拟合程度评价,但数据集中可不止$A({{x}_{i}},{{y}_{i}})$一个数据点,所以,我们需要对每个点进行误差评估,然后求和,也就是误差平方和作为这个线性模型对数据集的总体拟合程度评估:
我们将$J({{ heta }_{0}},{{ heta }_{1}})$作为损失函数,也有资料中称为目标函数。这里,${{ heta }_{0}},{{ heta }_{1}}$是模型中$x$的参数。在不同的模型中,${{ heta }_{0}},{{ heta }_{1}}$取不同值,我们要做的就是求目标函数$J({{ heta }_{0}},{{ heta }_{1}})$取最小值时的${{ heta }_{0}},{{ heta }_{1}}$确切值,换句话说就是求$J({{ heta }_{0}},{{ heta }_{1}})$的最优解问题。
关于求最优解问题,最常用的算法就是最小二乘法和梯度下降法,这两种方法在前两篇博文中都有详细介绍,如果你尚不清楚其中原理和过程,还是去看看吧,这很重要,也很基础。
上面说的是一元线性回归模型,对于多元线性回归模型,原理也是一样的,只不过需要求解的参数不止${{ heta }_{0}},{{ heta }_{1}}$两个了就是,这里不再多说。下面我们用代码实现一元线性回归模型。
4 代码实现
以下代码参考《深度学习之Pytorch》一书中内容,代码采用Python的pytorch实现。
在实现模型之前,首先我们要制造一个数据集,在[0, 10]区间范围内,随机生成100个数:
import torch x = torch.unsqueeze(torch.linspace(0, 10, 100), dim=1) print(x)
输出的内容有100行,这就是一个列向量,我们以则100个数作为数据集中的自变量,也就是X,假设我们需要拟合的模型为:$y=f(x)=0.5x+15$,为了更加符合真实数据集中随机误差的效果,我们在生成y的时候,加上一些服从高斯分布随机误差:
y = 0.5 * x + 15 + torch.rand(x.size()) print(y)
输出结果为:
tensor([[15.0477],
[15.0557],
[15.3653],
……
[20.7046],
[20.1751]])
在二维坐标轴上,这些点如下所示:
数据有了,我们可以开始搭建我们的模型了:
class LinearRegression(nn.Module): def __init__(self): super(LinearRegression, self).__init__() self.linear = nn.Linear(1, 1) # 因为是一元线性回归,所以输入和输出的维度都是1 def forward(self, x): out = self.linear(x) return out if torch.cuda.is_available(): model = LinearRegression().cuda() else: model = LinearRegression() criterion = nn.MSELoss() # 这里选择使用误差平方和作为损失函数,就是上文中说的函数J optimizer = torch.optim.SGD(model.parameters(), lr=1e-2) # 定义梯度下降算法进行优化 num_epochs = 1000 # 定义迭代次数 for epoch in range(num_epochs): if torch.cuda.is_available(): inputs = Variable(x).cuda() target = Variable(y).cuda() else: inputs = Variable(x) target = Variable(y) # 向前传播 out = model(inputs) loss = criterion(out, target) # 向后传播 optimizer.zero_grad() # 注意每次迭代都需要清零 loss.backward() optimizer.step() if (epoch + 1) % 20 == 0: print('Epoch[{}/{}], loss:{:.6f}'.format(epoch + 1, num_epochs, loss.item())) model.eval() if torch.cuda.is_available(): predict = model(Variable(x).cuda()) predict = predict.data.cpu().numpy() else: predict = model(Variable(x)) predict = predict.data.numpy() plt.plot(x.numpy(), y.numpy(), 'ro', label='Original Data') plt.plot(x.numpy(), predict, label='Fitting Line') plt.show() print(str(model.state_dict()['linear.weight']) + " " + str(model.state_dict()['linear.bias']))
训练出来的模型效果如下所示:

代码最后一行输出为:
tensor([[0.5206]], device='cuda:0') tensor([15.3803], device='cuda:0')
也就是说,模型训练结果中,${{ heta }_{0}},{{ heta }_{1}}$分别为15.3803和0.5206.