下载数据包
链接:https://grouplens.org/datasets/movielens/1m/
解压:
四个文件分别是数据介绍,电影数据表,电影评分表,用户表
进行电影数据分析
进入ipython,新建一个项目
从用户表读取用户信息
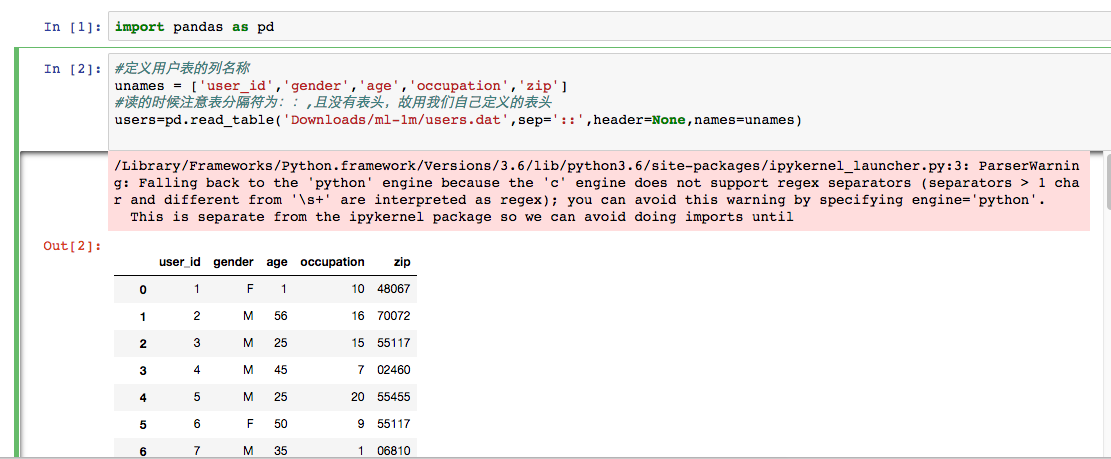
警告原因,C语言实现的引擎不支持某些特性,最终用Python引擎实现
打印列表长度,共有6040条记录

查看前五条记录
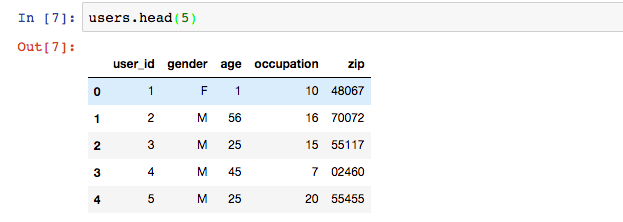 其中age对应的年龄段在readme表中有对应说明
其中age对应的年龄段在readme表中有对应说明
同样方法,导入电影数据表,电影评分表
查看导入数据数量,评分表为1000209条,电影数据表有3883条

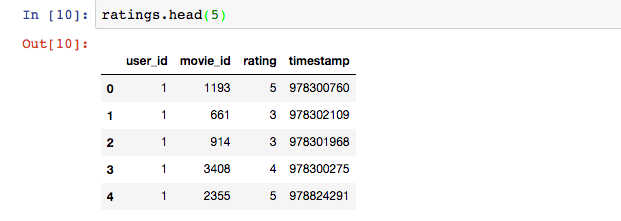
查看评分表前五条数据
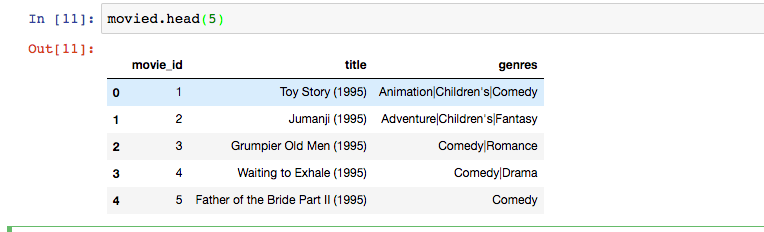
查看电影数据前五条
导入完成之后,我们可以发现这三张表类似于数据库中的表
要进行数据分析,我们就要将多张表进行合并才有助于分析
使用merge函数合并

先将users与ratings两张表合并再跟movied合并
查看合并后的表长度和前十条数据
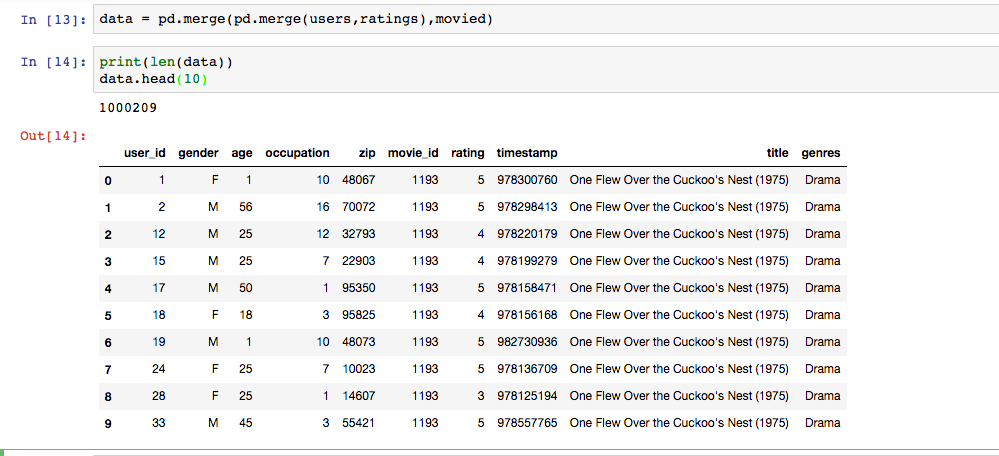
合并后的每一条记录反映了每个人的年龄,职业,性别,邮编,电影ID,评分,时间戳,电影信息,电影分类等一系列信息
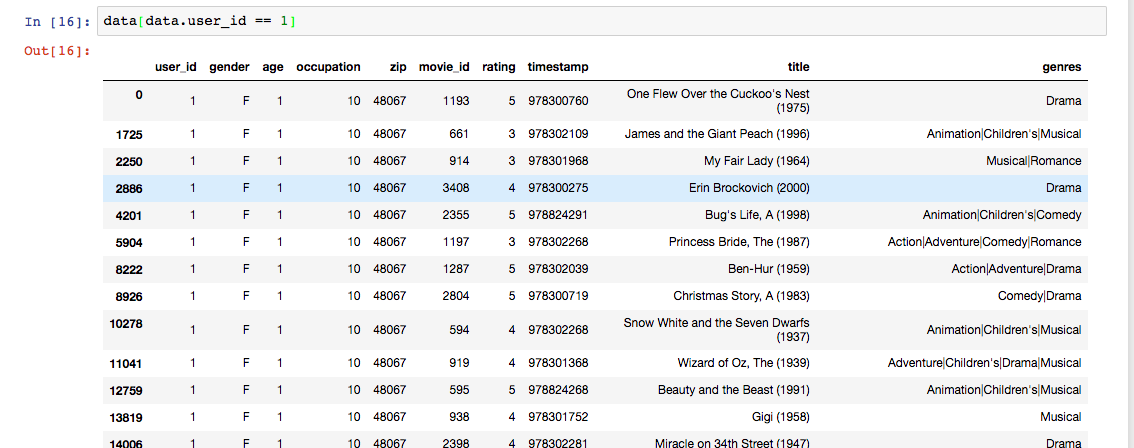
比如我们查看用户id为1的所有信息
查看每一部电影不同性别的平均评分
运用数据透视
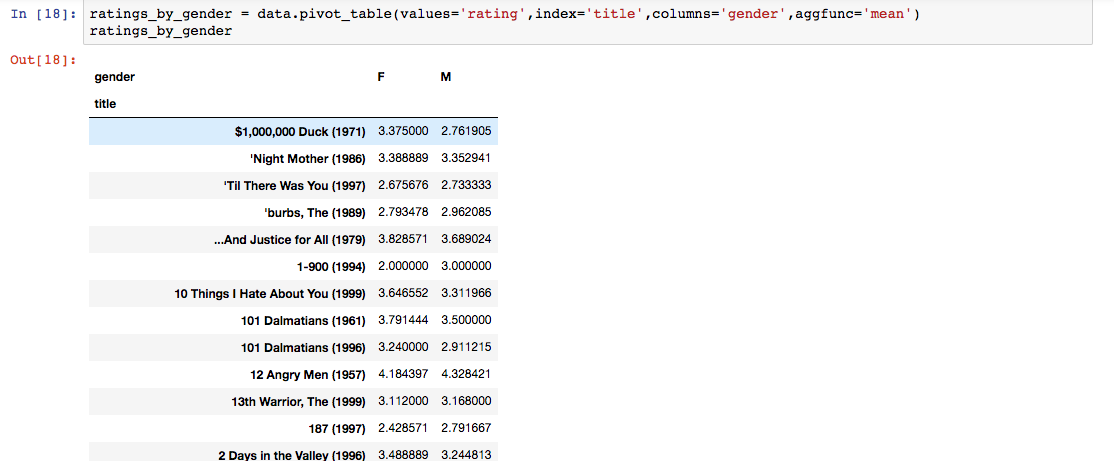
表中结构为每一部电影男性跟女性的评分平均值
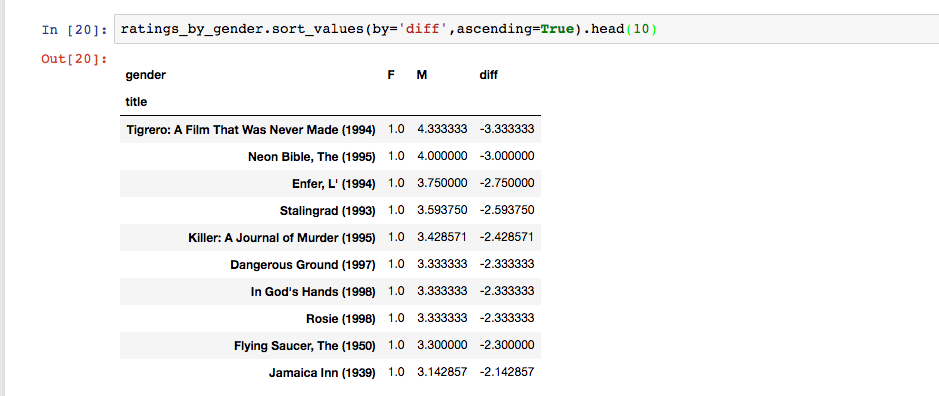
查看电影分歧最大的那部电影
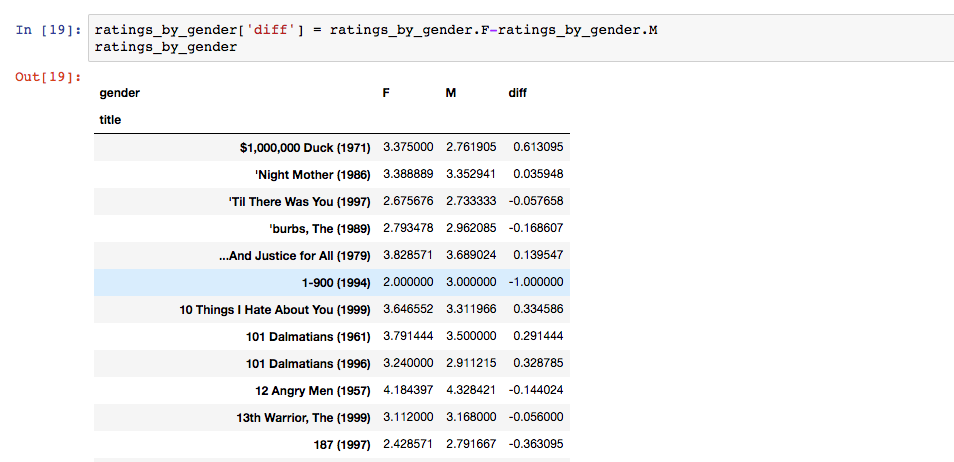
加一列评分差值
按照diff排序
查看评分最多的电影
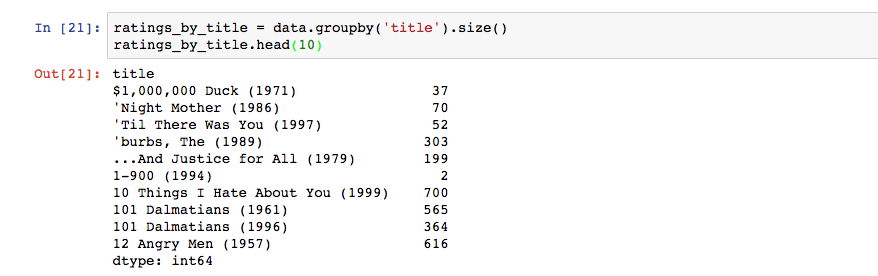
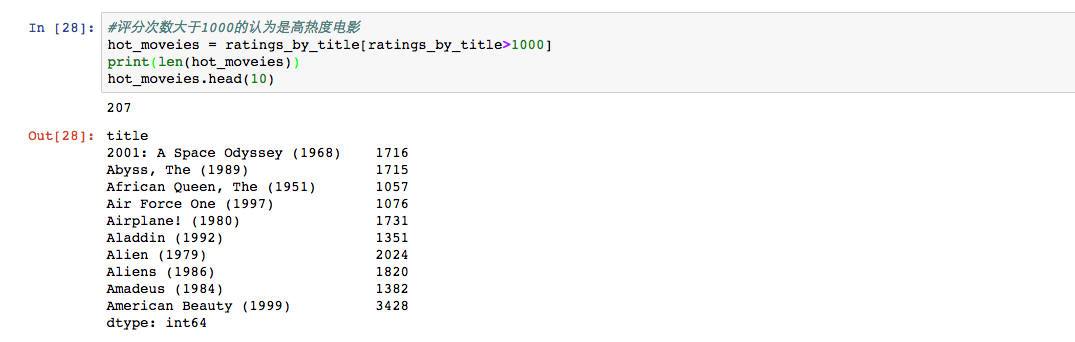
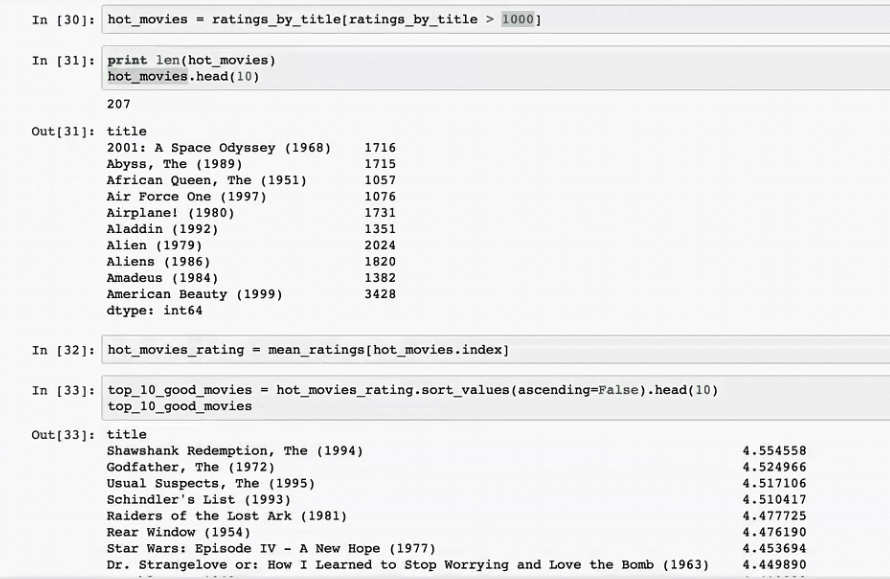
查看最热门电影
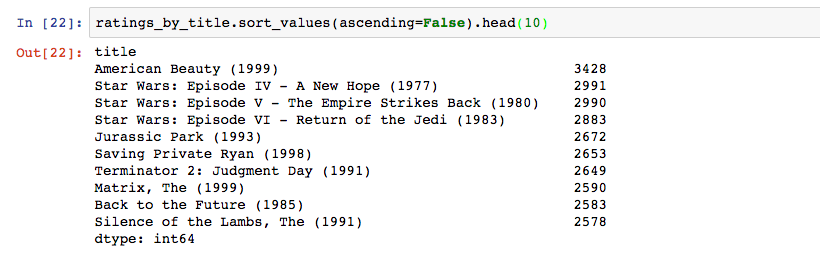
查看最高分电影
先算出每部电影平均得分
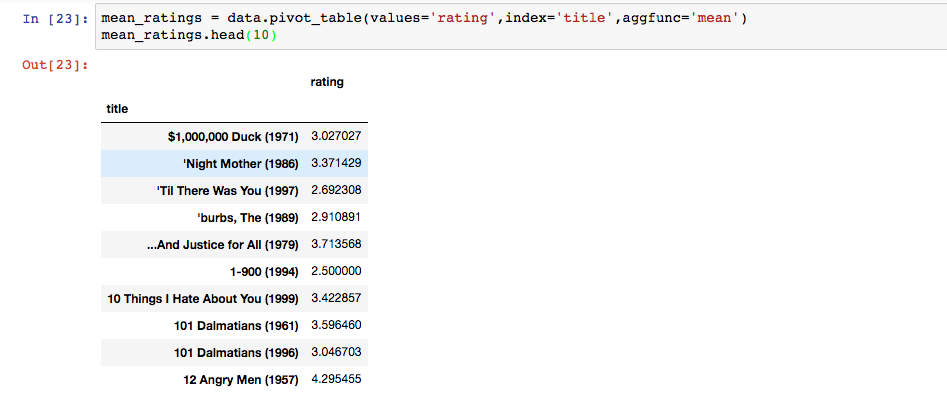
对电影平均得分排序
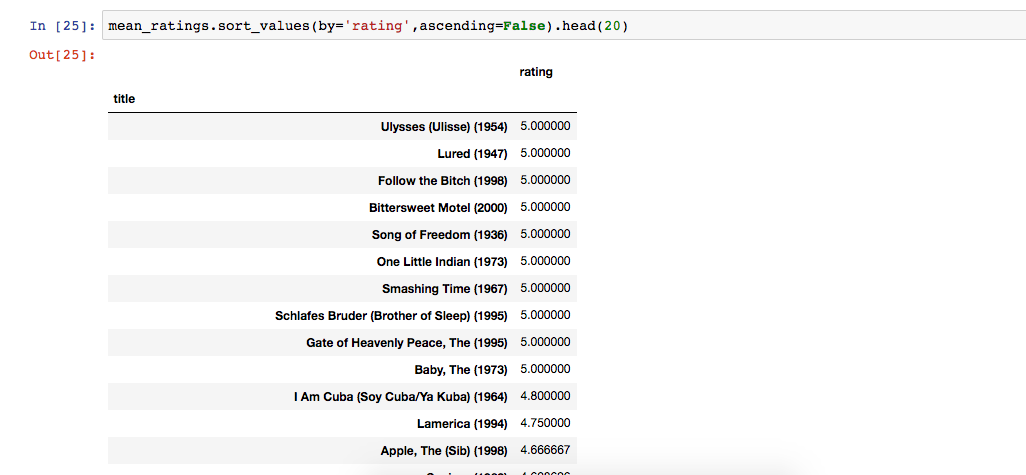
当然,从严格意义上仅仅通过单一条件电影评分高低我们还不能判断这部电影是否是一部真正的好电影,因为评分均分跟观影人数也有关系
先按照热度找出热度高的电影,有207部电影符合条件,然后我们可以在评分数据透视中筛选出符合条件的数据