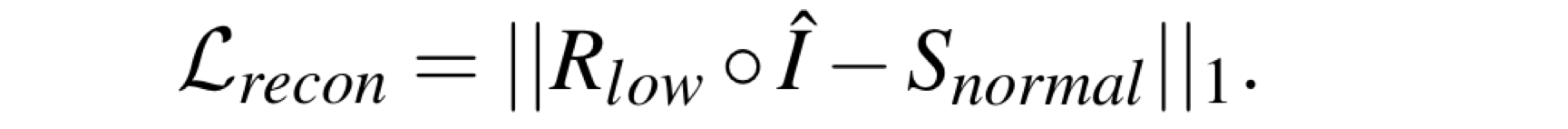这篇文章来自 BMVC 2018。低光图像增强一直是一个火热的领域,在过去的几十年中,有很多传统的方法用于增强低光图像,但这些方法都在一定程度上限制了增强效果。随着深度学习的兴起,卷积神经网络也被应用在这个领域,这篇文章是将Retinex理论与深度学习结合的文章,下面就一起来看看这篇文章的设计方法。
项目地址:https://github.com/weichen582/RetinexNet。
摘要
Retinex 模型是低光图像增强的有效工具,假设观测到的图像可以分解为反射率和光照。大多数现有的基于 Retinex 的方法都为这种高度不适应分解精心设计了手工制定的约束和参数,当应用于各种场景时,这可能受到模型容量的限制。在本文中,作者收集了包含低/正常光图像对的数据集(LOL),并提出了在该数据集上学习的 Deep Retinex-Net,包括用于分解的分解网络和用于照明调整的增强网络。在分解网络的训练过程中,不存在分解反射率和光照的 ground-truth。该网络仅在关键的约束条件下学习,包括成对低/正常光图像共享的一致反射率,以及照明的平滑性。在分解的基础上,通过增强网络 Enhance-Net 对光照进行后续的亮度增强,联合去噪时对反射率进行去噪操作。Retinex-Net 是端到端可训练的,因此学习到的分解本质上适合调节亮度。大量实验表明,该方法不仅在低光增强时获得了良好的视觉效果,而且提供了良好的图像分解方案。
引言
引言部分先介绍了一些传统的低光图像增强方法,并指出了这些方法存在的不足以及面临的困难。为了克服这些困难,提出了一个数据驱动的 Retinex 分解方法,在此基础上建立了一个 Retinex-Net 深度网络,该网络集成了图像分解和连续的增强操作。分解子网 Decom-Net 用来将观察到的图像分解为独立于光线的反射率和结构感知的光照平滑,在两个约束条件下学习 Decom-Net(低/正常光的图像具有相同的反射率;照明图应该是平滑的,但保留主要结构,这是通过结构感知的总变化损失获得的)。Enhance-Net 用来调整光照图以保持大区域的一致性,同时通过多尺度级联来裁剪局部分布。由于暗区噪声往往较大,甚至在增强过程中被放大,因此引入了反射率去噪(这部分作者在文中写到,但是代码并没有去噪模块)。
主要贡献
在真实场景中捕获的成对低/正常光照图构建了一个大规模数据集,这是在低光增强领域的首次尝试;
构建了一种基于 Retinex 理论的深度学习图像分解方法,分解网络采用连续的低光增强网络进行端到端的训练,因此该框架具有良好的光照调节能力;
提出了一种结构感知的总变化约束用于深度图像分解。通过在梯度较强的地方减少总变化的影响,成功地平滑了光照图并保留了主要结构。
数据驱动的图像分解
在训练阶段,Decom-Net 每次都会获取成对的低/正常光图像,并在低光图像和正常光照图像共享相同的反射率的指导下学习低光图像及其对应的正常光图像的分解。需要注意的是,尽管分解是用成对的数据进行训练的,但在测试阶段,只需要用低光图像作为输入即可。在训练过程中,不需要提供反射率和光照的 ground-truth,仅将反射率一致性和光照平滑度等作为损失函数嵌入到网络中。因此,网络的分解是从成对的低/正常光图像中自动学习的,并且自然而然地适合于描述不同光照条件下图像之间的光照变化。
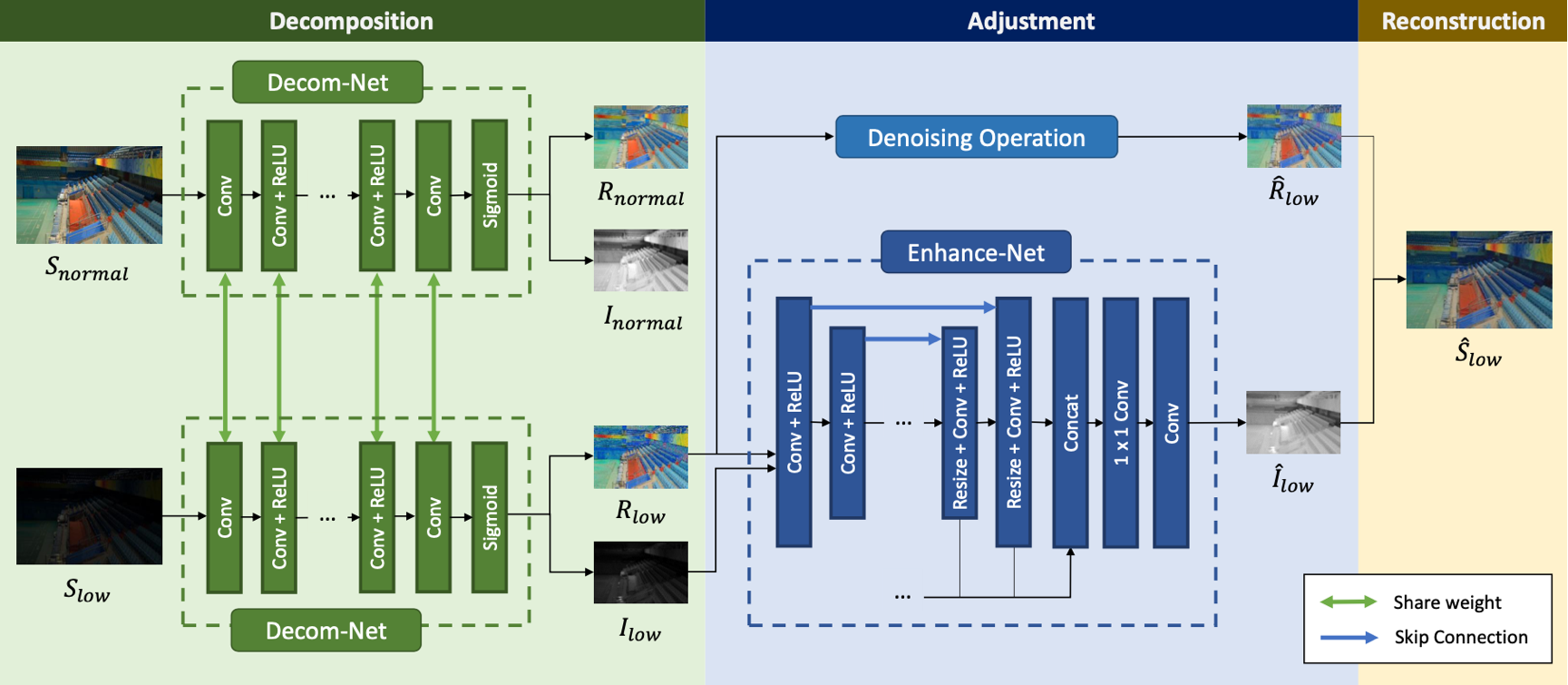
网络的体系架构如图所示。Decom-Net 用低光和正常光图像作为输入,然后从中估计低光图像和正常光图像的反射率。首先用一个 3×3 的 Conv 从输入图像中提取特征,然后,使用 5 个 3×3 的 Conv + ReLU 将 RGB 图像映射为反射率和光照,再使用一个 3×3 的 Conv 从特征空间投影反射率和光照,最后使用 Sigmoid 函数将反射率和光照约束在 [0,1] 之间。
总的损失函数由三部分组成:重建损失(Lrecon)、反射率一致性损失(Lir)、光照平滑损失(Lis):
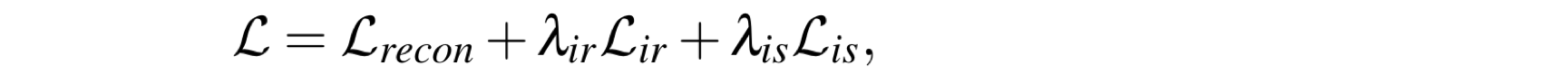
其中重建损失:
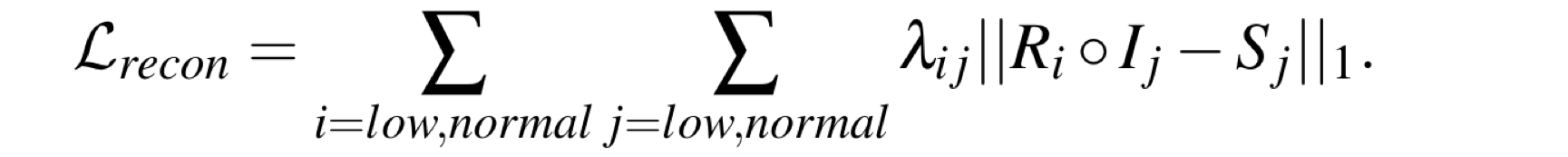
反射率一致性损失:
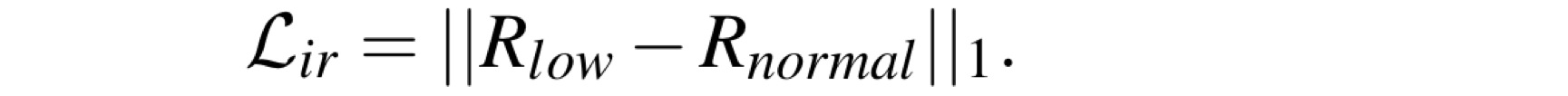
结构平滑损失
总变化最小化(TV)是使整个图像的梯度最小化的方法,经常被用于各种图像恢复任务的平滑先验(进行各种图像恢复任务之前用作平滑度)。然而,在图像结构较强或亮度变化较大的区域,直接使用 TV 作为损失函数是行不通的。这是由于无论该区域是文本细节还是强边界,光照图的梯度都是均匀减小的。
为了使损失意识到图像结构,利用反射图的梯度对原始TV函数进行加权:
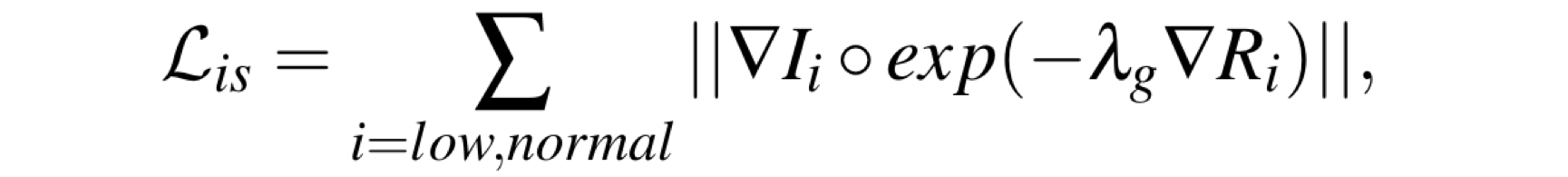
其中 ∇ 为水平和垂直方向上的梯度。
多尺度照明调整
Enhance-Net 采用了 encoder-decoder 的体系结构。对输入图像进行小尺度连续下采样,使网络能够了解大尺度的光照分布情况,这给网络带来了自适应调节能力。利用大尺度光照信息,进行上采样重建局部光照分布。
为了实现光照的分层调整,即在保持全局光照一致性的同时调整局部光照分布的多样性,提出了一种多尺度连接方法。如果有 M 个上采样块,每个块都提取一个 C 通道的特征图,通过最近邻插值在不同尺度上调整这些特征的大小到最终的尺度,并将它们连接到 C×M 通道的特征图。然后,通过 1×1 卷积层,将级联特征还原为 C 个通道,最后使用 3×3 卷积层重建光照图。
一个下采样块由一个步长为 2 的 Conv + ReLU 组成。在上采样块中,使用了 resize-convolutional(由一个最近邻插值操作,一个步长为 1 的 Conv + ReLU 组成)。
Enhance-Net 的损失函数由两部分组成:重建损失、光照平滑损失。
其中重建损失: