在线微博数据可视化,即时采集微博数据,通过不同词云进行展示数据
完整代码gitee地址:https://gitee.com/lyc96/weibo
1.先来效果图(压压惊)
1)输入明星完整名字

2)点击查看后,可以看到明星的言语文字可视化,有六种图形,可以随意切换
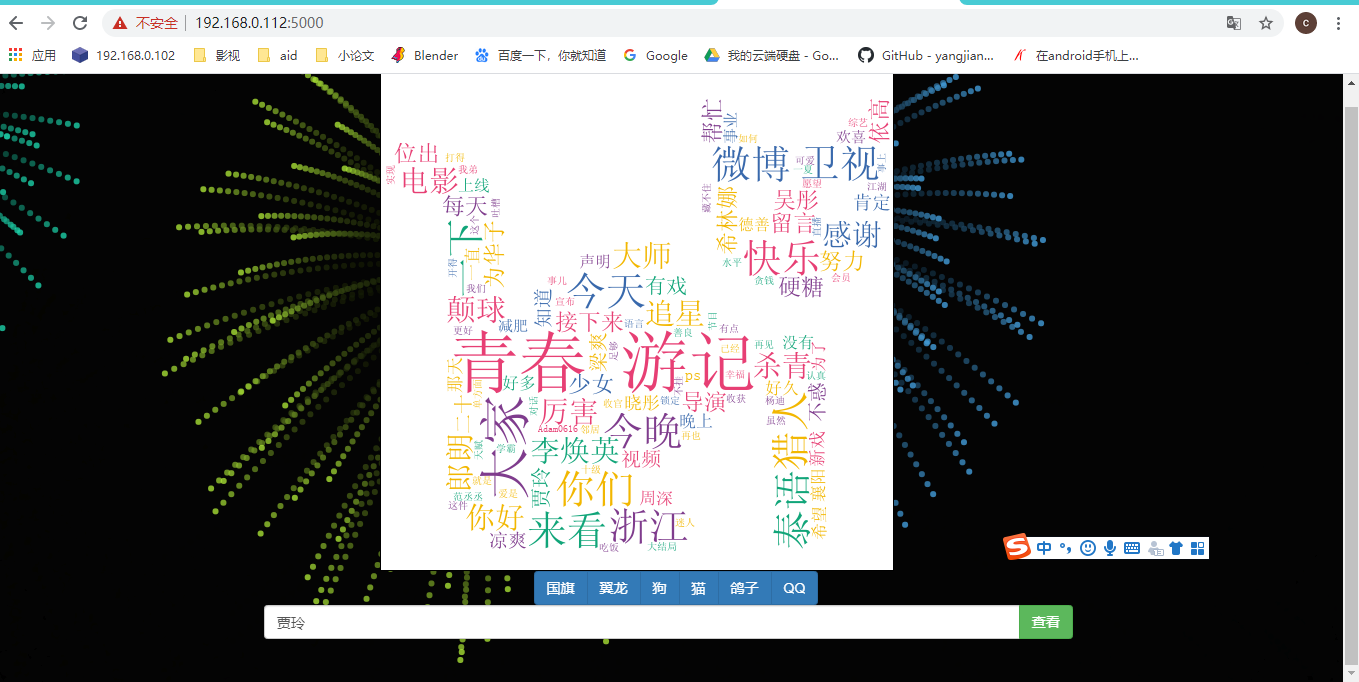
2.程序功能介绍
1)根据明星姓名去爬取该明星的微博言论,并存储到文本文件(项目中不涉及任何数据库存储),程序中也会根据日期进行去重爬取,避免程序重复爬取同一条微博。
2)采集好的明星微博文本存储到txt文本中,使用stylecloud进行词云生成图片(有六种图形词云,可以在网页端进行切换)
3.python后端代码


1 # -*- coding: utf-8 -*- 2 """ 3 Created on Sun Jul 19 12:03:56 2020 4 5 @author: 李运辰 6 """ 7 import requests 8 import time 9 import os 10 import json 11 from stylecloud import gen_stylecloud 12 import jieba 13 from flask_cors import CORS 14 from flask import Flask,render_template,request,Response,redirect,url_for 15 #内网ip 16 app = Flask(__name__) 17 ###此处改为自己的ip地址,在index.html中两次也记得更改 18 ip="192.168.0.112" 19 ### 20 root="static/data/" 21 pagedata="pagedata/" 22 textdata="textdata/" 23 24 # 睡眠时间 传入int为休息时间,页面加载和网速的原因 需要给网页加载页面元素的时间 25 def s(int): 26 time.sleep(int) 27 headers = { 28 29 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36' 30 } 31 """初始化""" 32 def initialization(): 33 #初始化爬取记录文本 34 if not os.path.exists(root): 35 os.mkdir(root) 36 if not os.path.exists(root+pagedata): 37 os.mkdir(root+pagedata) 38 if not os.path.exists(root+textdata): 39 os.mkdir(root+textdata) 40 41 def write(path,t): 42 #记录当前爬取页数 43 with open(path,"a+",encoding='utf8') as f: 44 f.writelines(str(t)) 45 f.writelines(" ") 46 47 def search(name_s,url,since_id): 48 49 #url = "https://m.weibo.cn/api/container/getIndex?uid=1566301073&t=0&luicode=10000011&lfid=100103type=1&q=贾玲&type=uid&value=1566301073&containerid=1076031566301073" 50 start=1 51 if since_id is not None and len(since_id)>1: 52 url+="&since_id="+since_id 53 start=0 54 response = requests.get(url,headers = headers) 55 56 datas = response.json() 57 #print(data) 58 ok = str(datas['ok']) 59 try: 60 with open(root+pagedata+name_s+".txt","r") as f: #设置文件对象 61 pagelist = f.read() 62 except: 63 pagelist=[] 64 65 if ok is not None and ok=='1': 66 data = datas['data'] 67 since_ids = data['cardlistInfo']['since_id'] 68 print(since_ids) 69 cards = data['cards'] 70 print(len(cards)) 71 for i in range(start,len(cards)): 72 date = cards[i]['mblog']['created_at'] 73 if str(date) not in pagelist: 74 text1 = cards[i]['mblog']['text'] 75 write(root+textdata+name_s+".txt",clean(text1)) 76 write(root+pagedata+name_s+".txt",date) 77 78 """去掉表情...,等html标签""" 79 def clean(s): 80 istart=-1 81 try: 82 istart = s.index('<') 83 iend = s.index('>') 84 s = s[:istart]+s[iend+1:] 85 except: 86 pass 87 try: 88 istart = s.index('<') 89 except: 90 pass 91 if istart>=0: 92 return clean(s) 93 else: 94 #print(s) 95 return(s) 96 97 def geturl(name_g): 98 url1="https://m.weibo.cn/api/container/getIndex?containerid=100103type=1%26q="+name_g+"&page_type=searchall" 99 response = requests.get(url1,headers = headers) 100 datas = response.json() 101 uid = str(datas['data']['cards'][0]['card_group'][0]['user']['id']) 102 newurl = "https://m.weibo.cn/api/container/getIndex?uid="+uid+"&t=0&luicode=10000011&lfid=100103type=1&q="+name_g+"&type=uid&value="+uid+"&containerid=107603"+uid 103 return newurl 104 105 def jieba_cloud(file_name,icon): 106 with open(file_name,'r',encoding='utf8') as f: 107 word_list = jieba.cut(f.read()) 108 result = " ".join(word_list) #分词用 隔开 109 #制作中文云词 110 icon_name="" 111 if icon=="1": 112 icon_name='' 113 elif icon=="2": 114 icon_name='fas fa-dragon' 115 elif icon=="3": 116 icon_name='fas fa-dog' 117 elif icon=="4": 118 icon_name='fas fa-cat' 119 elif icon=="5": 120 icon_name='fas fa-dove' 121 elif icon=="6": 122 icon_name='fab fa-qq' 123 """ 124 # icon_name='',#国旗 125 # icon_name='fas fa-dragon',#翼龙 126 icon_name='fas fa-dog',#狗 127 # icon_name='fas fa-cat',#猫 128 # icon_name='fas fa-dove',#鸽子 129 # icon_name='fab fa-qq',#qq 130 """ 131 picp=file_name.split('.')[0] +str(icon)+'.png' 132 if icon_name is not None and len(icon_name)>0: 133 gen_stylecloud(text=result,icon_name=icon_name,font_path='simsun.ttc',output_name=picp) #必须加中文字体,否则格式错误 134 else: 135 gen_stylecloud(text=result,font_path='simsun.ttc',output_name=picp) #必须加中文字体,否则格式错误 136 137 return picp 138 ############################flask路由 139 #进入首页 140 @app.route('/') 141 def index(): 142 return render_template('index.html') 143 #获取图片 144 @app.route('/find') 145 def find(): 146 #global history 147 #采集数据 148 name_i = request.args.get('name') 149 150 if not os.path.exists(root+textdata+name_i+'.txt'): 151 u = geturl(name_i) 152 search(name_i,u,"") 153 #制作词云 154 file_name = root+textdata+name_i+'.txt' 155 picpath = jieba_cloud(file_name,"1") 156 157 return Response(json.dumps(picpath), mimetype='application/json') 158 #切换图标 159 @app.route('/switchs') 160 def switchs(): 161 #global history 162 #采集数据 163 name_i = request.args.get('name') 164 icon = request.args.get('ic') 165 #制作词云 166 file_name = root+textdata+name_i+'.txt' 167 picpath = jieba_cloud(file_name,str(icon)) 168 return Response(json.dumps(picpath), mimetype='application/json') 169 ############################end 170 171 if __name__ == "__main__": 172 """初始化""" 173 initialization() 174 app.run(host=''+ip, port=5000,threaded=True)
4.完整代码gitee地址:https://gitee.com/lyc96/weibo