之前教过大家如何爬取手机APP数据【以某乎为实战案例,教你用Python爬取手机App数据】
思路:主要是通过手机设置代理,然后在pc端开启抓包工具获取数据包,然后在编写python代码(get方式)去请求数据
上次有粉丝说,那个是ios手机安卓手机现在需要root权限才可以安装证书,那么今天就不以手机为例,以电脑PC端为例,这样大家都可以上手尝试
今天教大家抓到post数据包之后,怎么编写python代码去狗仔构造数据包,这里以获取『微信公众号』文章的阅读数、点赞数、在看数为例进行讲解(之所以以这个例子,主要还是有点难度的,所以给大家分享一下这个技术)
1、抓包工具
同样,这里还是使用Fiddler
为什么要用抓包工具,不直接复制文章链接在浏览器里面采集?
因为在浏览器里面打开看不到阅读数、点赞数、在看数等
所以这里采用抓包的方式
1.配置Fiddler
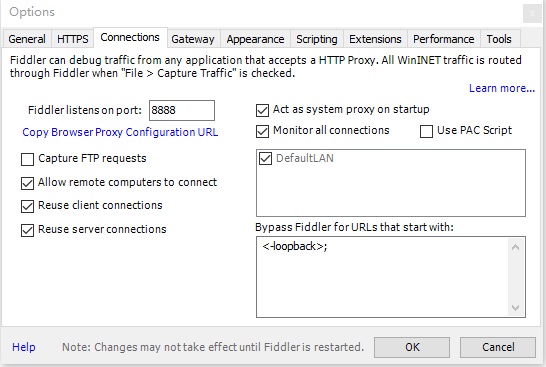
端口设置为8888
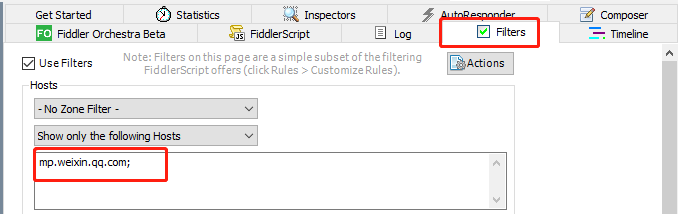
这里设置一下过滤域名,目的是只查看需要查看的域名数据包
2.安装证书
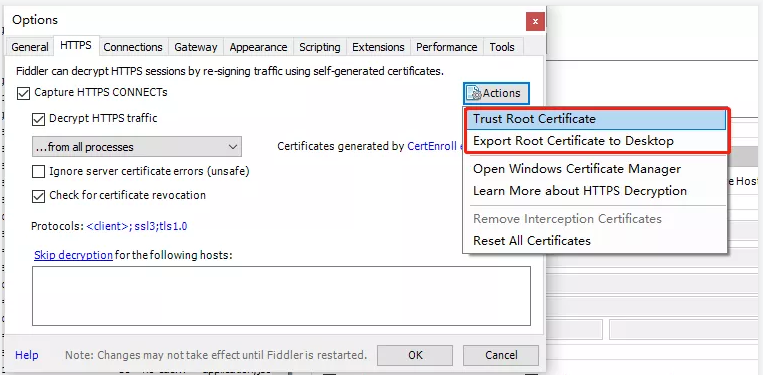
点击第一个可以在pc机上安装证书,Fiddler就可以抓取https数据包
2、pc端代理
在设置-代理,里面设置相应的ip和端口(这里ip是本机ip127.0.0.1,和fiddler中对应的端口)
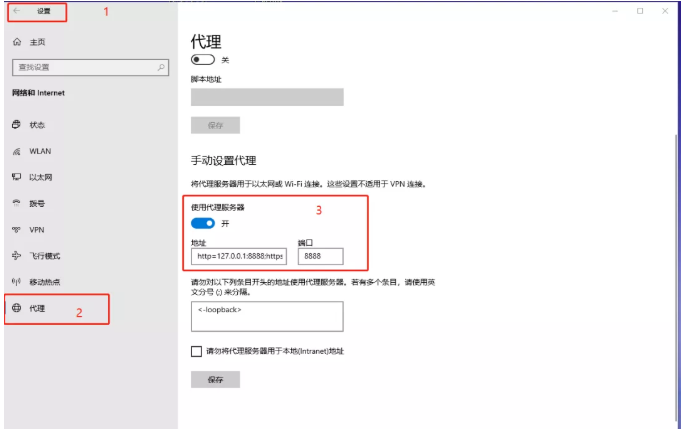
下面就可以开始抓包
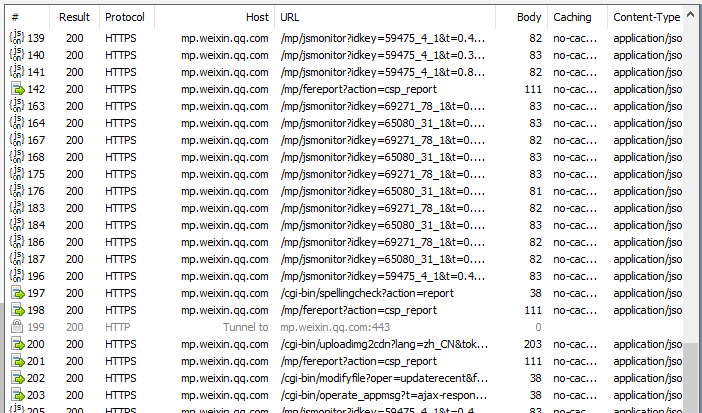
3、开始抓包
在pc机上打开微信公众号文章,比如
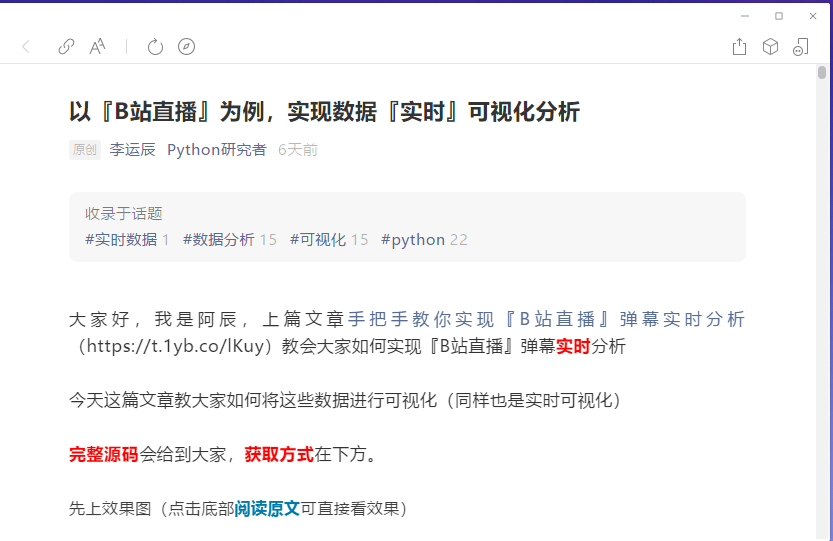
打开之后再Fiddler可以看到数据包
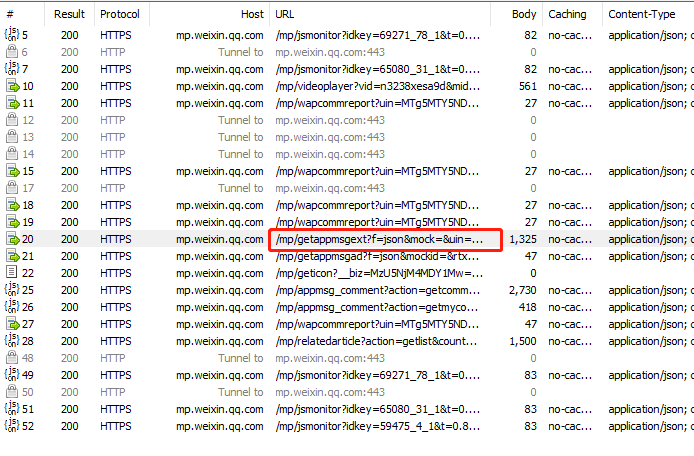
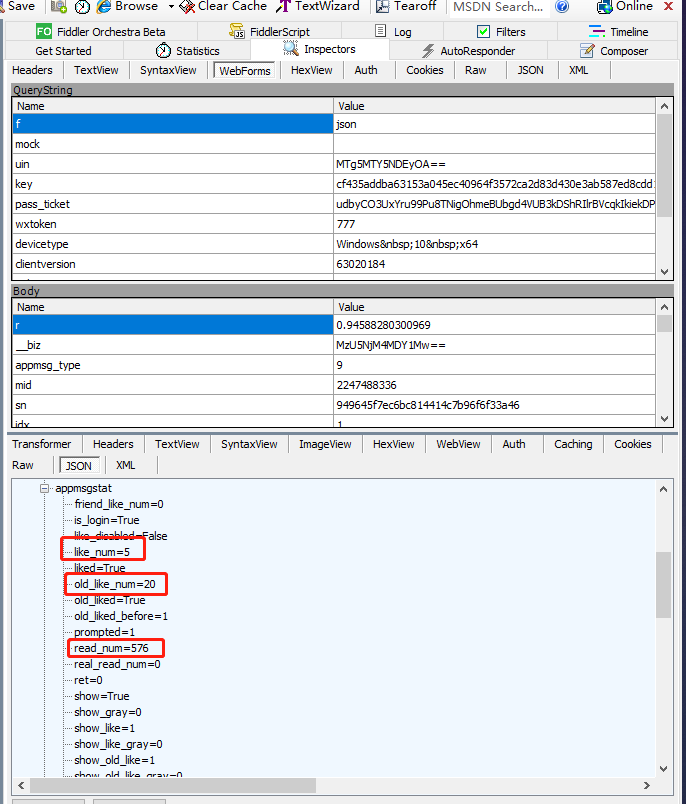
比如原文中阅读数:576、点赞:20、在看:5


对应数据包返回的json数据
4、编程构造Post请求
抓到数据包之后,我们可以知道cookie、表单,请求链接等信息
开始编写代码之前,先给大家说一下,大概需要用到哪些数据(表单里面有很多参数,但是大部分是不需要的),蓝色选中的就是需要的参数,其他的可以忽略
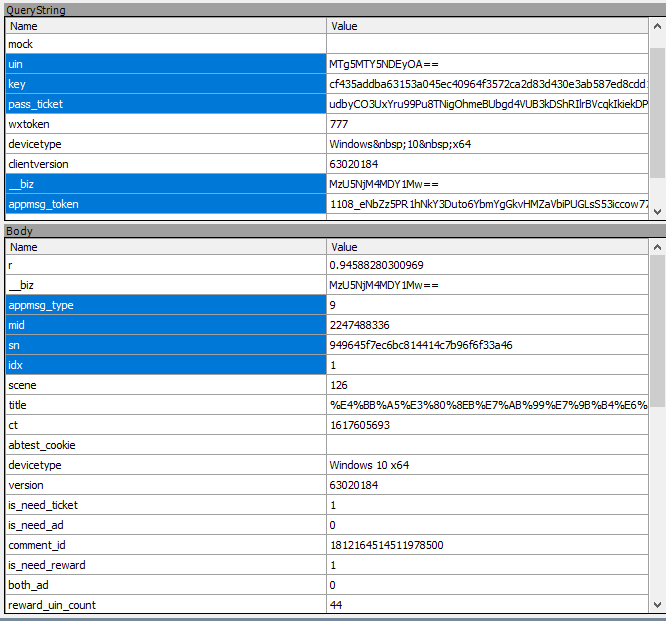
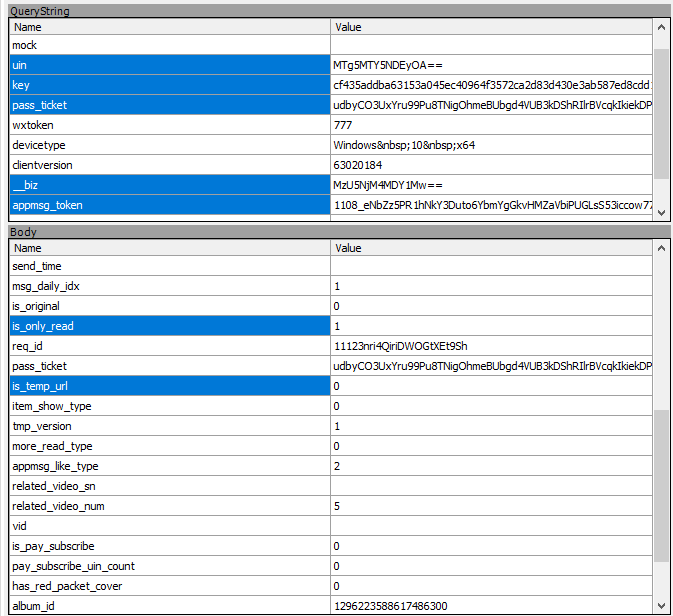
请求头(这里替换cookie),User-Agent是模拟手机浏览器
# 目标url
origin_url= "http://mp.weixin.qq.com/mp/getappmsgext"
headers = {
"Cookie": yourcookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.27.400 QQBrowser/9.0.2524.400"
}
这里是请求需要的其中三个参数(这个三个数通用的,可以不用改)
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9", # 新参数,不加入无法获取like_num
}
剩下的其他参数(每个参数配备了相应的说明)
###同一个公众号,这个不变
your__biz =""
###每一篇文章mid都不同
article_mid=""
###每一篇文章sn都不同
article_sn=""
###不变
article_idx="1"
###几十分钟有效,之后需要再次抓包更新
yourappmsg_token="1108_eNbZz5PR1hNkY3Duto6YbmYgGkvHMZaVbiPUGLsS53iccow77rh73HxzFPHQby1-Lw8AqItVlg_d96MU"
构造请求
origin_url = "https://mp.weixin.qq.com/mp/getappmsgext?"
appmsgext_url = origin_url + "__biz={}&mid={}&sn={}&idx={}&appmsg_token={}&x5=1".format(your__biz, article_mid, article_sn, article_idx, yourappmsg_token)
content = requests.post(appmsgext_url, headers=headers, data=data).json()
print(content)
print(content["appmsgstat"]["read_num"], content["appmsgstat"]["old_like_num"],content["appmsgstat"]["like_num"])

可以看到已经成功发送post成功,并且提取出对应的阅读数、点赞数、在看数
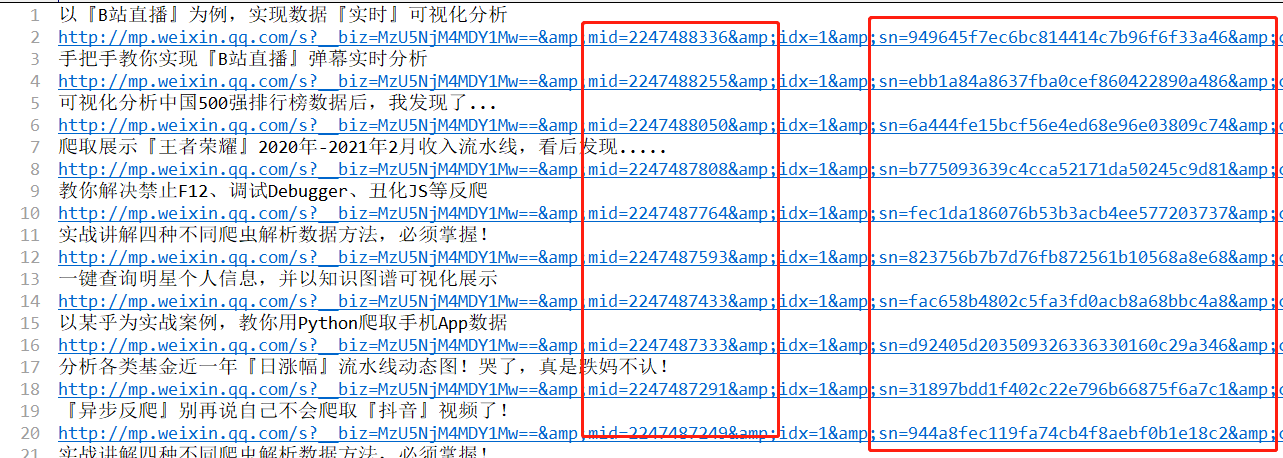
5、扩展
同一个公众号,如果需要获取其他文章的这些数据,只需要改变mid和sn就可以了,不同文章的链接如下图所示
6、小结
本文讲解了如何爬取PC端数据(以微信公众号为例),过程很详细,满满干货,希望可以起到抛砖引玉效果,让大家学到更多技术!
推荐阅读
公众号后台添加微信,可领取代码
