今天就介绍一个爬虫进阶的内容,利用异步请求库 aiohttp 来提升你的爬虫速度。
以前我有写过一篇文章,说的是很多人在学完一些高级特性,却一直不懂得如何使用,甚至越学越迷茫,导致学到最后只会对编程越来越厌倦。
我的建议是不管是什么高级的概念和技巧,一定要懂得高级概念能有什么作用,在项目中会怎么使用。通过具体的项目实战,对高级概念有个具体的认知,而不是只有空洞的表面学习。
这就好比你在玩游戏的时候,你懂得出这个装备会非常牛x,但具体牛x在哪里,就需要你回头认真的看装备属性的描述。
《虫术》这部书就是想让大家知道,不同等级的虫术之间会有什么效果,差别又有多大。对于具体的技术细节教程,我不会去讲解,因为这样就失去了小说原本的乐趣。但最后我会给出对应的技术教程文章,需要进一步了解的同学,自行学习。
所以今天我不会从最基础的概念来讲解什么是异步,什么是协程,我们就直接来看下用上来异步框架 aiohttp 的爬虫,到底有多牛逼。
aiohttp
aiohttp 是一个支持异步请求的库,利用它的 asyncio 配合我们可以非常方便地实现异步请求操作。
安装方式如下:
1 pip install aiohttp
然后我们直接来看下一个使用了 aiohttp 的爬虫和一个没有使用异步的爬虫,它们之间的速度到底差多少。
flask 请求环境
首先我利用 flask 库,在本地搭建一个网站,网站的内容非常的简单,先等待 3 秒,然后输出「高阶虫术:异步请求术」。
运行下面的代码需要你安装好 flask 的库。
安装方式如下:
1 pip install flask
程序代码:
1 from flask import Flask 2 import time 3 4 app = Flask(__name__) 5 6 @app.route("/") 7 def index(): 8 time.sleep(3 ) 9 return "高阶虫术:异步请求术" 10 11 if __name__ == '__main__': 12 app.run(threaded=True)
运行程序就会在「http://127.0.0.1:5000」地址输出「高阶虫术:异步请求术」。
虫者二段普通请求
本地测试环境都已搭建好,我们就可以开始创造我们的爬虫。首先身为虫者二段的我,第一反应想到的是利用 requests 库进行请求,随后我写下了下面的代码。
1 import requests 2 import time 3 4 start = time.time() 5 6 def get(url): 7 response = requests.get(url) 8 result = response 9 return result 10 11 def request(): 12 url = "http://127.0.0.1:5000" 13 print("Wating for", url) 14 result = get(url) 15 print("Get response from", url, "Result:", result) 16 17 18 tasks = [request() for _ in range(100)] 19 end = time.time() 20 print("Cost time:", end - start)
我们通过循环来对本地地址进行 100 次的请求,最后输出总耗时数。
输出结果如下:
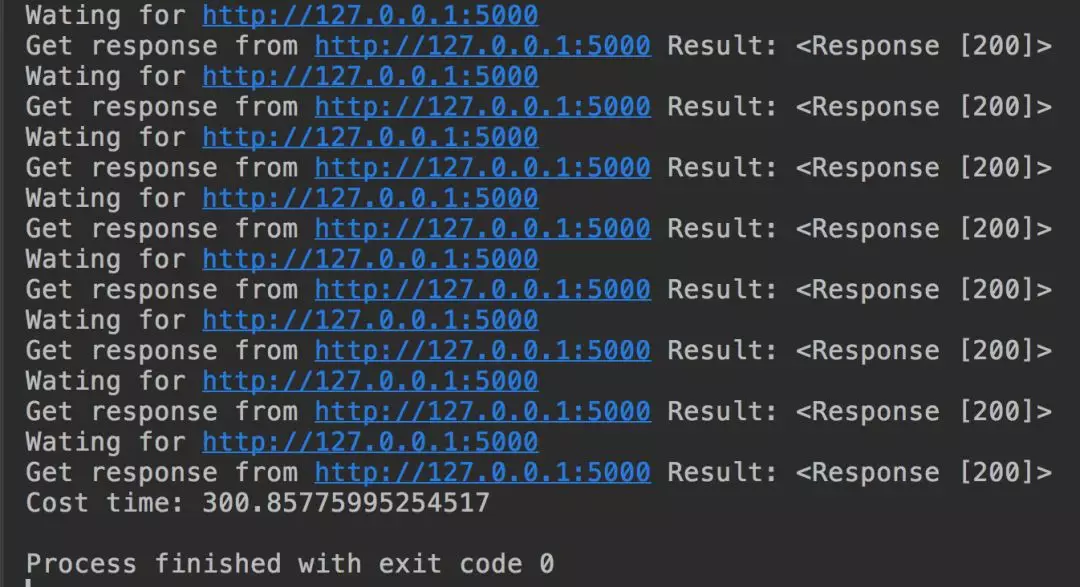
虫者二段所写的代码果然惨不忍睹,总耗时:300 多秒,慢的令人发指。
虫尊三段异步请求
随后在看了《虫术》之后,得到高人虫尊的指点习得「高阶虫术:异步请求术」我对上面的代码进行了修改。
1 import asyncio 2 import requests 3 import aiohttp 4 import time 5 6 start = time.time() 7 8 async def get(url): 9 session = aiohttp.ClientSession() 10 response = await session.get(url) 11 result = await response.text() 12 session.close() 13 return result 14 15 async def request(): 16 url = "http://127.0.0.1:5000" 17 print("Wating for", url) 18 result = await get(url) 19 print("Get response from", url, "Result:", result) 20 21 tasks = [asyncio.ensure_future(request()) for _ in range(100)] 22 loop = asyncio.get_event_loop() 23 loop.run_until_complete(asyncio.wait(tasks)) 24 25 26 end = time.time() 27 print("Cost time:", end - start)
最后输出结果:
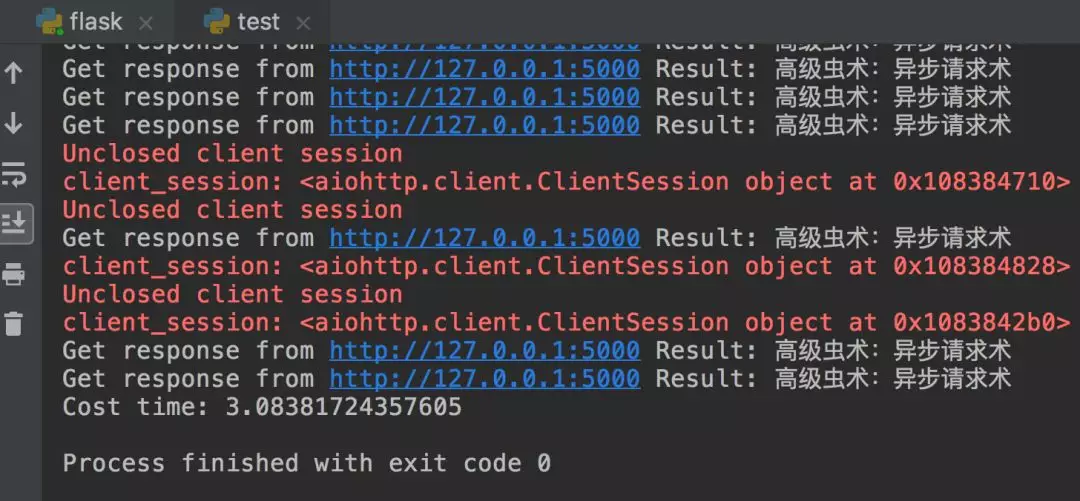
3.08 秒!在短短的 3 秒时间里,我就完成这 100 次的请求!速度提升了 100 倍!
爬虫的世界风云涌动,处处充满着危机,不同等级的虫师有着天与地的差别,唯有强大的虫师才能生存下来。
关于异步请求具体的细节,可以看崔庆才的这篇教程。