二叉查找树
查找(search)和插入(insert)
查找过程跟二分法查找一样:如果当前节点的值大于查找值,就去左子树里面找,否则去右子树里面找。
插入过程如下:1.若当前的二叉查找树为空,则插入的元素为根节点,2.若插入的元素值小于根节点值,则将元素插入到左子树中,3.若插入的元素值不小于根节点值,则将元素插入到右子树中。
#include <stdlib.h> #include <stdio.h> #include <sys/time.h> struct _pnode { int data; struct _pnode *left; struct _pnode *right; }; typedef struct _pnode* pnode; static pnode search(pnode p, int x) { int find = 0; while (p && !find) { if (x == p->data) { find = 1; } else if (x < p->data) { p = p->left; } else { p = p->right; } } if (p == NULL) { printf("not found "); } return p; } // Resursive static pnode insert(pnode q, int x) { pnode p = (pnode) malloc(sizeof(struct _pnode)); p->data = x; p->left = NULL; p->right = NULL; if (q == NULL) { q = p; } else if (x < q->data) { q->left = insert(q->left, x); } else { q->right = insert(q->right, x); } return q; } static void InOrder(pnode root) { if (!root) { printf("tree is empty "); return; } pnode p = root; if (p->left) { InOrder(p->left); } printf("%d ", p->data); if (p->right) { InOrder(p->right); } } int main() { int n, key; struct timeval tv; pnode p, BT = NULL; for (n=0; n<10; n++) { gettimeofday(&tv, NULL); srandom(tv.tv_usec); key = random() % 100; printf("insert key=%d ", key); BT = insert(BT, key); } InOrder(BT); if (p = search(BT, key)) { printf(" key=%d found", p->data); } return 0; }
上面的函数InOrder演示了如何中序遍历一棵二叉树,运行结果:
[root@localhost tmp]# ./a.out insert key=32 insert key=78 insert key=15 insert key=94 insert key=57 insert key=40 insert key=30 insert key=90 insert key=35 insert key=31 15 30 31 32 35 40 57 78 90 94 key=31 found[root@localhost tmp]#
验证了二叉查找树的中序遍历是一个有序序列!
中序遍历的非递归方法:
static void InOrder2(pnode root) //非递归中序遍历 { stack<pnode> s; pnode p = root; while (p || !s.empty()) { while (p) { s.push(p); p=p->left; } if (!s.empty()) { p=s.top(); cout<<p->data<<" "; s.pop(); p=p->right; } } }
插入过程也可以采用非递归的方法:
// Non-recursive static pnode insert_BST(pnode q, int x) { pnode p = (pnode) malloc(sizeof(struct _pnode)); p->data = x; p->left = NULL; p->right = NULL; if (q == NULL) { return p; } pnode root = q; while (q->left != p && q->right != p) { if (x < q->data) { if (q->left) { q = q->left; } else { q->left = p; } } else { if (q->right) { q = q->right; } else { q->right = p; } } } return root; }
以上介绍的插入方法会导致新增新结点一定在叶子这一层,当插入的节点较多时,可能会导致树的高度大幅增加。可以简单测试一下,构造包含100个节点的二叉树,然后计算树的高度:
static int TreeDepth (pnode p) { if (!p) return 0; int nLeft = TreeDepth(p->left); int nRight = TreeDepth(p->right); return (nLeft > nRight) ? (nLeft+1) : (nRight+1); } int main() { int n, key; struct timeval tv; pnode p, BT = NULL; for (n=0; n<100; n++) { gettimeofday(&tv, NULL); srandom(tv.tv_usec); key = random() % 100; BT = insert_BST(BT, key); } printf("depth=%d ", TreeDepth(BT)); return 0; }
多次运行的结果如下:
[root@localhost tmp]# ./a.out depth=16 [root@localhost tmp]# ./a.out depth=17 [root@localhost tmp]# ./a.out depth=17 [root@localhost tmp]# ./a.out depth=16 [root@localhost tmp]# ./a.out depth=12 [root@localhost tmp]# ./a.out depth=13
100个节点的高度就能到17,显然离log100的理想值有点远。
考虑最极端的情况,将1~100按顺序插入
int main() { int n, key; struct timeval tv; pnode p, BT = NULL; for (n=0; n<100; n++) { //gettimeofday(&tv, NULL); //srandom(tv.tv_usec); //key = random() % 1000; BT = insert_BST(BT, n); } printf("depth=%d ", TreeDepth(BT)); return 0; }
树的高度达到100了,这个时候各种操作(插入/查找)的性能已经下降到O(n)了,其实已经退化成一个链表了。
[root@localhost tmp]# ./a.out depth=100
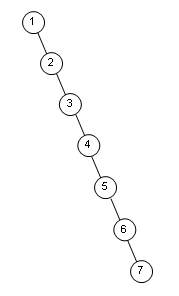
如何解决这个问题呢?关键在于如何最大限度的减小树的深度,平衡二叉树(AVL)正是基于这个想法提出的,后面还会专门介绍下。
最小值(MIN)和最大值(MAX)
最小值只要沿着左子树一直往左走就可以找到;最大值只要沿着右子树一直往右走就可以找到;
static pnode min(pnode p) { while (p && p->left) { p = p->left; } return p; } static pnode max(pnode p) { while (p && p->right) { p = p->right; } return p; } int main() { int n, key; struct timeval tv; pnode p, BT = NULL; for (n=0; n<10; n++) { gettimeofday(&tv, NULL); srandom(tv.tv_usec); key = random() % 100; printf("insert key=%d ", key); BT = insert_BST(BT, key); } p = min(BT); if (p) { printf("min=%d ", p->data); } p = max(BT); if (p) { printf("max=%d ", p->data); } return 0; }
运行结果:
[root@localhost tmp]# ./a.out insert key=6 insert key=57 insert key=20 insert key=19 insert key=46 insert key=92 insert key=48 insert key=52 insert key=85 insert key=59 min=6 max=92
前驱(predecessor)与后继(successor)
一个节点的前驱是指所有比它小的节点里面最大的那个;
一个节点的后继是指所有比它大的节点里面最小的那个;
换句话说,在二叉查找树的中序遍历中,某个节点的前一个和后一个就分别是其前驱和后继。
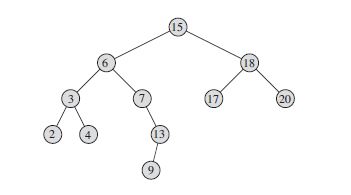
求某节点p的后继结点y,分两种情况:
1、如果p有右子树,那么y是p右子树中的最小值,如上图节点7的后继是节点9;
2、如果p无右子树,那么y是p最低祖先节点,且y的左儿子也是p的祖先,如上图节点4的后继是节点6;
前驱和后继互为镜像操作,实现如下:
static pnode parent(pnode p, pnode node) { if (!node) return NULL; while (p && node != p->left && node != p->right) { if (p->data > node->data) { p = p->left; } else { p = p->right; } } return p; } static pnode successor(pnode root, pnode node) { pnode p; if (node->right) { return min(node->right); } p = parent(root, node); while (p && node == p->right) { node = p; p = parent(root, p); } return p; } static pnode predecessor(pnode root, pnode node) { pnode p; if (node->left) { return max(node->left); } p = parent(root, node); while (p && node == p->left) { node = p; p = parent(root, p); } return p; } int main() { int n, key; struct timeval tv; pnode p, q, BT = NULL; int array[11] = {15, 6, 18, 3, 7, 17, 20, 2, 4, 13, 9}; for (n=0; n<11; n++) { key = array[n]; BT = insert_BST(BT, key); } p = search(BT, 13); q = successor(BT, p); printf("successor of 13 is %d ", q->data); q = predecessor(BT, p); printf("predecessor of 13 is %d ", q->data); return 0; }
上面的parent函数用于获取一个节点的父节点,运行结果:
[root@localhost tmp]# ./a.out successor of 13 is 15 predecessor of 13 is 9
删除(delete)
二叉查找树的删除,分三种情况进行处理,假设待删除节点记为p,
1、p没有子女,直接删除p,再修改其父节点的指针(注意分是根节点和不是根节点),如下图a;
2、p有1个子女,让p的子树与p的父亲节点相连即可(注意分是根节点和不是根节点),如下图b;
3、p有2个子女,找到p的后继节点y,且y一定没有左子树(否则y就不是p的直接后继了),删除y,然后让y的父亲节点成为y的右子树的父亲节点,并用y的值代替p的值,如下图c;
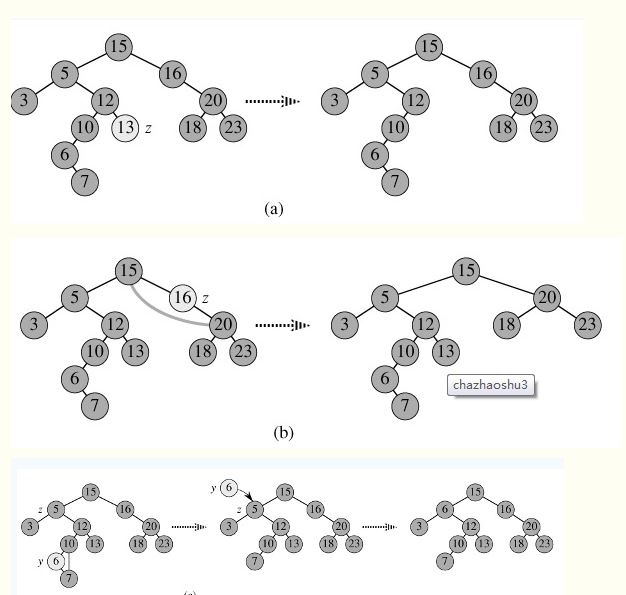
代码如下:
static void delete(pnode *root, pnode p) { pnode r = *root; pnode x = NULL; pnode y = NULL; pnode py; // y 是要删除的节点 if (NULL == p->left || NULL == p->right) { y = p; } else { y = successor(r, p); } // x是y的非NULL孩子,如果y是叶子节点,则x为NULL if (y->left) { x = y->left; } else { x = y->right; } py = parent(r, y); // 删除 y if (NULL == py) { // y 是root节点 r = x; } else if (y == py->left) { py->left = x; } else { py->right = x; } // p有两个孩子时,y是其后继,将后继节点的值覆盖p if (y != p) { p->data = y->data; } free(y); } int main() { int n, key; struct timeval tv; pnode p, q, BT = NULL; int array[12] = {15, 5, 16, 3, 12, 20, 10, 13, 18, 23, 6, 7}; for (n=0; n<12; n++) { key = array[n]; BT = insert_BST(BT, key); } p = search(BT, 5); delete(&BT, p); InOrder(BT); return 0; }
运行结果:
[root@localhost tmp]# ./a.out 3 6 7 10 12 13 15 16 18 20 23
注意:对应的p有两个孩子节点情况,也可以使用前驱,即找到p的前驱x,x一定没有右子树,所以可以删除x,并让x的父亲节点成为y的左子树的父亲节点,
本文介绍了BST树的基本操作,下面还有一篇文章介绍BST树的一些经典算法。