本身这段时间也在学习MySQL索引原理,想记录下来 ,碰巧的是半个小时前刷到了下面这篇文章。所以就摘抄部分,省的自己做总结了。以此记录、加深记忆。
博文链接(https://www.cnblogs.com/itwild/p/13703259.html)介绍的非常好,建议阅读。
各种索引之间的比较
Hash:
- 能够提供
O(1)的单数据行的查询性能 - 不支持范围查找
- 无法排序
- 不能避免全表扫描
红黑树(Red Black Tree):
是一种自平衡二叉查找树,在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
一般来说,索引本身也很大,往往不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗远远高于内存,所以评价一个数据结构作为索引的优劣最重要的指标就是查找过程中磁盘I/O次数。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的次数。在这里,磁盘I/O的次数取决于树的高度,所以,在数据量较大时,红黑树会因树的高度较大而造成磁盘IO较多,从而影响查询效率。
B -Tree:
B树中的B代表平衡(Balance),而不是二叉(Binary),B树是从平衡二叉树演化而来的。
为了降低树的高度(也就是减少磁盘I/O次数),把原来瘦高的树结构变得矮胖,B树会在每个节点存储多个元素(红黑树每个节点只会存储一个元素),并且节点中的元素从左到右递增排列。如下图所示:
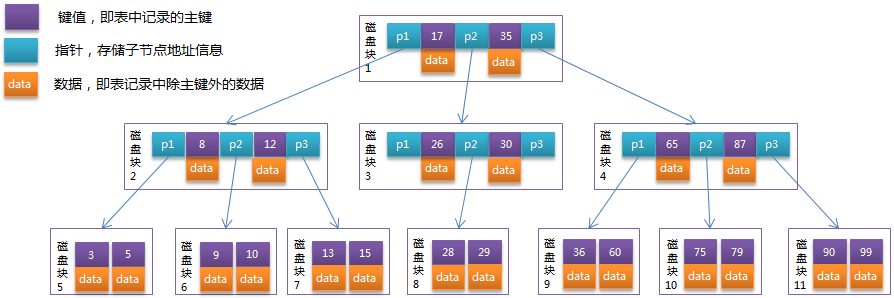
B-Tree在查询的时候比较次数其实不比二叉查找树少,但在内存中的大小比较、二分查找的耗时相比磁盘IO耗时几乎可以忽略。
B-Tree大大降低了树的高度,所以也就极大地提升了查找性能。
B +Tree
B+Tree是在B-Tree基础上进一步优化,使其更适合实现存储索引结构。InnoDB存储引擎就是用B+Tree实现其索引结构。
B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。而每一个节点的存储空间是有限的,如果data值较大时将会导致每个节点能存储的key的数量很小,这样会导致B-Tree的高度变大,增加了查询时的磁盘I/O次数,进而影响查询性能。在B+Tree中,所有data值都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以增大每个非叶子节点存储的key值数量,降低B+Tree的高度,提高效率。
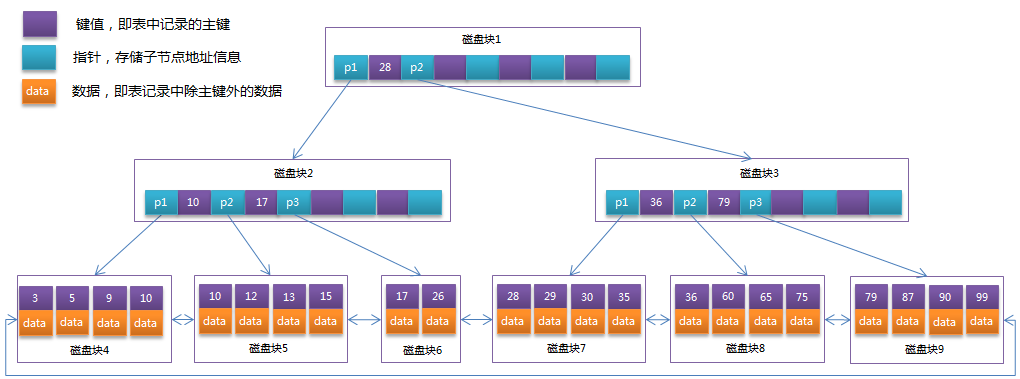
MyISAM、InnoDB存储引擎的索引实现
MyISAM:
MyISAM中,主键索引和非主键索引(Secondary key,也有人叫做辅助索引)在结构上没有任何区别,只是主键索引要求key是唯一的,而辅助索引的key可以重复。这里不再多加叙述。
InnoDB:
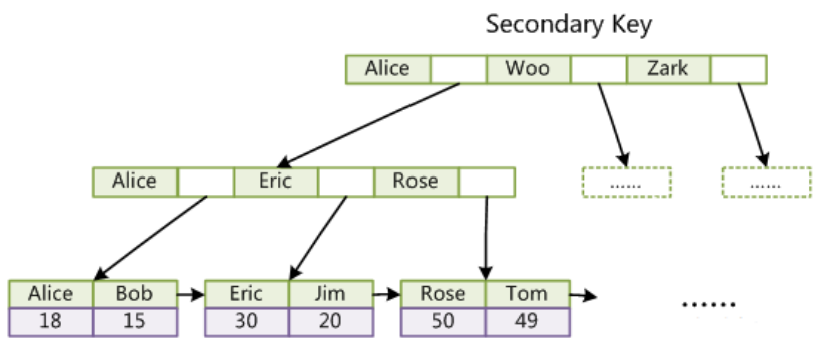
InnoDB的非主键索引data域存储相应记录主键的值。换句话说,InnoDB的所有非主键索引都引用主键的值作为data域。如下图所示:
MySQL存储引擎在磁盘中存储的数据文件
MyISAM: (非聚集索引)
frm:表的结构
MYD:数据文件
MYI:索引文件(非聚集)
InnoDB:(聚集索引)
frm:表的结构
ibd:数据+索引文件(聚集)