目录
滑动窗口算法
《代码大全》推荐先用伪代码来写框架,从最上层思考可以将抽象能力最大化,不会先陷入任何编程语言的实现细节中,通俗地说就是在蓝图层面解决问题。
滑动窗口算法非常适合用来查找数组连续区间,核心就是:
- while循环嵌套while循环
- 窗口收缩
- 窗口匹配
下面我们写出伪代码框架套路,并用这个套路来解相应的题,该思路来自labuladong的算法小抄,我自己改成了个人觉得更通用的版本,只需要实现is_need_shrink和is_match方法即可。
注意:先搞出来,再谈优化,别一开始就纠结是不是重复调用了,搞出来了这都简单
框架套路
求最小窗口(缩小后更新结果集)
结果集=[]
left=0
right=0
end = 数组大小
while right < end:
right++;
while 窗口需要收缩:
if 窗口满足要求:
结果集.添加([left,right])
left++;
return 结果集
求最大窗口(缩小前更新结果集)
结果集=[]
left=0
right=0
end = 数组大小
while right < end:
right++;
while 窗口需要收缩:
left++;
if 窗口满足要求:
结果集.添加([left,right])
return 结果集
实现大同小异,但是python代码几乎都是最少的,以下都用python实现
python翻译框架套路
求最小窗口
def min_window(array):
left = 0
right = 0
end = len(array)
res = []
while right < end:
right += 1
while is_need_shrink():
if is_match():
res.append([left, right]) # 在窗口缩小前更新
left += 1
return res
# 窗口需要收缩 todo
def is_need_shrink():
return True
# 窗口满足要求 todo
def is_match():
return True
求最大窗口
def max_window(array):
left = 0
right = 0
end = len(array)
res = []
while right < end:
right += 1
while is_need_shrink():
left += 1
if is_match():
res.append([left, right]) # 在窗口扩大后更新
return res
# 窗口需要收缩 todo
def is_need_shrink():
return True
# 窗口满足要求 todo
def is_match():
return True
res相当于添加了所有满足要求的[left, right]
1.is_need_shrink代表要收缩窗口
2.is_match函数代表窗口满足要求
我们大多时候只需要改这个两个函数即可
示例算法题
最小覆盖子串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
注意:
对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
示例 2:
输入:s = "a", t = "a"
输出:"a"
示例 3:
输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。
实现如下
# 最小覆盖子串,用了min_window框架
def minimum_window_substring(s, t):
left = 0
right = 0
end = len(s)
res = []
while right < end:
right += 1
while is_need_shrink(s, left, right, t):
if is_match(s, left, right, t):
res.append([left, right])
left += 1
return res
# 窗口需要收缩。完全匹配的时候收缩,和is_match效果一样
def is_need_shrink(s, left, right, t):
return is_match(s, left, right, t)
# 窗口已经匹配(当need_map的字符串数量和window_map的字符串数量完全匹配时)
def is_match(s, left, right, t):
need_map = {} # 构造需要匹配t的字符串的数量字典
for c in t:
need_map[c] = need_map.get(c, 0) + 1
need_cnt = len(need_map) # 需要匹配的数量
window_map = {} # 记录窗口已经匹配的字符串数量
match_cnt = 0 # 记录已经满足need_map的数量
for c in s[left:right]:
if c not in need_map:
continue
window_map[c] = window_map.get(c, 0) + 1
if window_map[c] == need_map[c]: # 如果数量相等,说明已经匹配
match_cnt += 1
return match_cnt == need_cnt
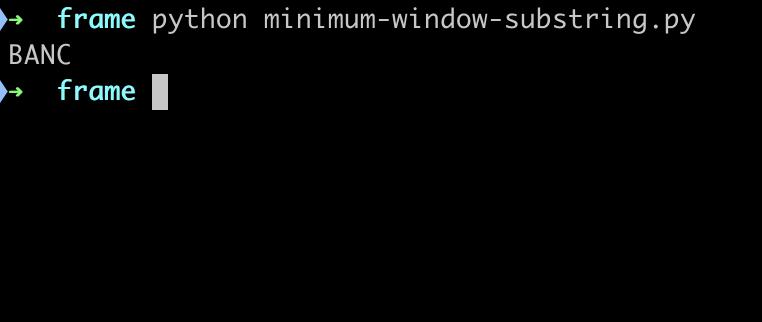
if __name__ == '__main__':
s = "ADOBECODEBANC"
t = "ABC"
res = minimum_window_substring(s, t)
# 在结果集中计算最小的,即为最小子串
min_len = len(s)
answer = ""
for v in res:
left, right = v[0], v[1]
if right - left < min_len:
min_len = right - left
answer = s[left:right]
if min_len == len(s):
print("")
else:
print(answer)
运行输出如下
字符串全排列子串
给你两个字符串 s1 和 s2 ,写一个函数来判断 s2 是否包含 s1 的排列。
换句话说,s1 的排列之一是 s2 的 子串 。
示例 1:
输入:s1 = "ab" s2 = "eidbaooo"
输出:true
解释:s2 包含 s1 的排列之一 ("ba").
示例 2:
输入:s1= "ab" s2 = "eidboaoo"
输出:false
实现如下
# 字符串全排列子串,用了min_window框架
def permutation_in_string(s, t):
left = 0
right = 0
end = len(s)
res = []
while right < end:
right += 1
while is_need_shrink(s, left, right, t):
if is_match(s, left, right, t):
res.append([left, right])
left += 1
return res
# 窗口需要收缩.窗口大于等于t长度时需要收缩
def is_need_shrink(s, left, right, t):
if right - left >= len(t):
return True
return False
# 窗口已经匹配。当need_map和window_map的所有字符串计数相同时
def is_match(s, left, right, t):
need_map = {} # 构造需要匹配t的字符串的数量字典
for c in t:
need_map[c] = need_map.get(c, 0) + 1
need_cnt = len(need_map) # 需要匹配的数量
window_map = {} # 记录窗口已经匹配的字符串数量
match_cnt = 0 # 记录已经满足need_map的数量
for c in s[left:right]:
if c not in need_map:
return False
window_map[c] = window_map.get(c, 0) + 1
if window_map[c] == need_map[c]: # 如果数量相完成等,说明匹配了c字符串
match_cnt += 1
return match_cnt == need_cnt
if __name__ == '__main__':
s = "eidbaooo"
t = "ab"
res = permutation_in_string(s, t)
for v in res:
print(f'{v[0]}~{v[1]} {s[v[0]:v[1]]}')
运行输出如下:

找出所有字母异位词
题目find-all-anagrams-in-a-string/
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词 指字母相同,但排列不同的字符串。
示例 1:
输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
示例 2:
输入: s = "abab", p = "ab"
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词。
这和上面的字符串排列子串完全相同套路,不同的是上面的只需要一个解即可,这个需要所有解。
实现如下
# 查找所有异位词,用了min_window框架
def find_all_anagrams_in_a_string(s, t):
left = 0
right = 0
end = len(s)
res = []
while right < end:
right += 1
while is_need_shrink(s, left, right, t):
if is_match(s, left, right, t):
res.append([left, right])
left += 1
return res
# 窗口需要收缩.窗口大于等于t长度时需要收缩
def is_need_shrink(s, left, right, t):
if right - left >= len(t):
return True
return False
# 窗口已经匹配。当need_map和window_map的所有字符串计数相同时
def is_match(s, left, right, t):
need_map = {} # 构造需要匹配t的字符串的数量字典
for c in t:
need_map[c] = need_map.get(c, 0) + 1
need_cnt = len(need_map) # 需要匹配的数量
window_map = {} # 记录窗口已经匹配的字符串数量
match_cnt = 0 # 记录已经满足need_map的数量
for c in s[left:right]:
if c not in need_map:
return False
window_map[c] = window_map.get(c, 0) + 1
if window_map[c] == need_map[c]: # 如果数量相完成等,说明匹配了c字符串
match_cnt += 1
return match_cnt == need_cnt
if __name__ == '__main__':
s = "cbaebabacd"
t = "abc"
res = find_all_anagrams_in_a_string(s, t)
for v in res:
print(f'{v[0]}~{v[1]} {s[v[0]:v[1]]}')
运行输出如下

最长无重复子串
题目longest-substring-without-repeating-characters
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
示例 4:
输入: s = ""
输出: 0
名字叫最长,这里需要的是最大窗口框架,也就是在窗口收缩前更新结果集
实现如下
# 最长无重复子串,用了max_window框架
def longest_substring_without_repeating_characters(s):
res = []
left = 0
right = 0
end = len(s)
while right < end:
right += 1
while is_need_shrink(s, left, right):
left += 1
if is_match(s, left, right):
res.append([left, right])
return res
# 窗口需要收缩。当有重复子串时,和is_match正好相反
def is_need_shrink(s, left, right):
return not is_match(s, left, right)
# 窗口已经匹配。没有重复子串
def is_match(s, left, right):
substr = s[left:right]
# 计算每个字符串个数
window_map = {}
for c in substr:
window_map[c] = window_map.get(c, 0) + 1
# 数量大于1说明有重复
if window_map[c] > 1:
return False
return True
if __name__ == '__main__':
s = "abcabcbb"
res = longest_substring_without_repeating_characters(s)
# 在结果集中计算最小的
max_len = 0
answer = ""
for v in res:
left, right = v[0], v[1]
if right - left > max_len:
max_len = right - left
answer = s[left:right]
print(answer)
运行输出如下

长度最小子数组
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
示例 2:
输入:target = 4, nums = [1,4,4]
输出:1
示例 3:
输入:target = 11, nums = [1,1,1,1,1,1,1,1]
输出:0
实现如下
# 长度最小的子数组,用了min_window框架
def min_sub_array_len(target, nums):
left = 0
right = 0
end = len(nums)
res = []
while right < end:
right += 1
while is_need_shrink(nums, left, right, target):
if is_match(nums, left, right, target):
res.append([left, right]) # 在窗口缩小前更新
left += 1
return res
# 窗口需要收缩 总和大于target时收缩,和is_match一样
def is_need_shrink(nums, left, right, target):
return is_match(nums, left, right, target)
# 窗口满足要求 总和大于target时收缩
def is_match(nums, left, right, target):
sum = 0
for v in nums[left:right]:
sum += v
return sum >= target
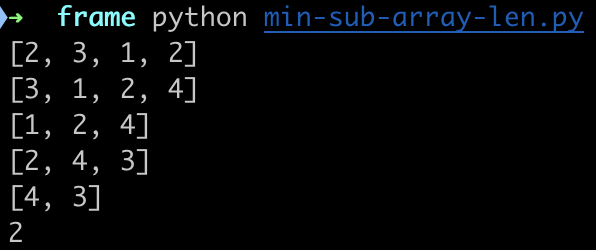
if __name__ == '__main__':
targe = 7
nums = [2, 3, 1, 2, 4, 3]
res = min_sub_array_len(targe, nums)
# 从所有答案中找出最小长度
min_len = len(nums)
for v in res:
left, right = v[0], v[1]
print(nums[left:right])
if right - left <= min_len:
min_len = right - left
print(min_len)
运行输出
优化
可以看到,不管怎么样,上来几乎都是这段代码,在把is_need_shrink和is_match写出来后,就可以去优化了
def min_window(array):
left = 0
right = 0
end = len(array)
res = []
while right < end:
right += 1
while is_need_shrink():
if is_match():
res.append([left, right]) # 在窗口缩小前更新
left += 1
return res
先搞出来了,我们就可以优化了
- 比如is_match和is_need_shrink可能相同,用一个就行了
- 比如循环里面重复计算need_map构造字典的操作,避免重复计算,可以提取到函数外部
- 比如res保存了所有的解,但有时候不需要所有的解,可以直接在is_match匹配时return
代码都搞出来了,这种优化都相对简单,套路才是最重要的,就是这样,giao~