一、索引帮助mysql高效获取数据排好序的数据结构。
二、索引存储位置:磁盘文件。
三、索引结构:二叉树、红黑树、hash、BTree、B+Tree 。索引结构为了更快找到目标数据。
四、数据结构
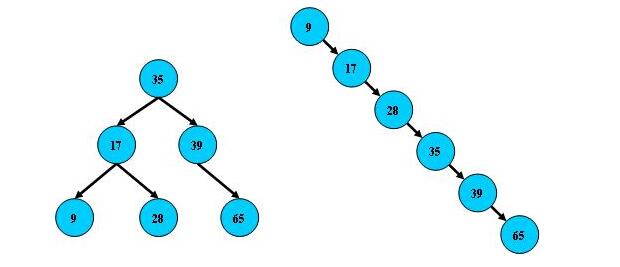
4.1、二叉树
定义:每个结点最多有两个子树,左子树比父节点小,右子树比父节点大。
缺点:会出现极端情况导致整棵树只有左子树或只有右子树。
图:
4.2、红黑树
定义:
缺点:数据量大会导致树层数比较多,这样就会造成查找数据慢。
图:

4.3、hash数据结构
定义:散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。 对目标值进行hash运算得到hash值和数据磁盘指针地址保存到hash表,这样就达到快速定位数据位置。
缺点:精确查找十分快速,但范围查找就碰壁了。
图:无
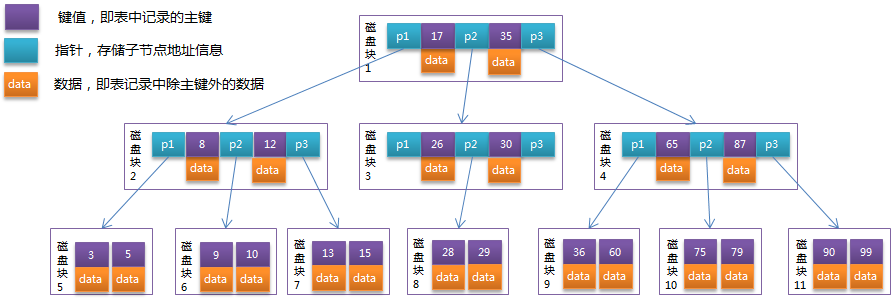
4.4、BTree
定义:一个节点可以存储多个数据,这样可以避免黑红树的缺点,树的层数很变小。
缺点: 节点里面数组数据:每个数据的结构=索引数据+数据记录(即叶子节点存储键值和数据记录)。
图:
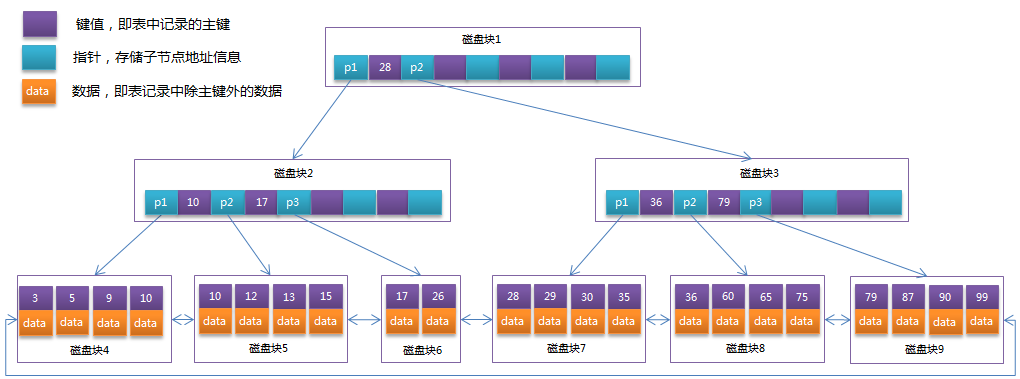
4.5、B+Tree
定义:B+Tree是在B-Tree基础上的一种优化。节点里面数组数据:每个数据只存储键信息,这样不存数据可以腾出空间放更多的键信息,让树层数越小。
- 非叶子节点只存储键信息。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
缺点:无
图:
五、mysql采用B+Tree数据结构存储数据
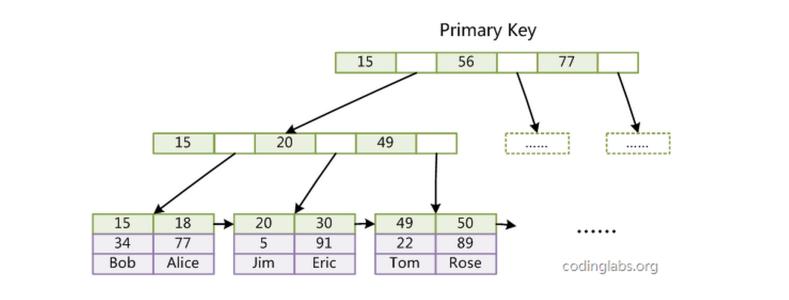
5.1、B+TREE叶子节点指针作用:定位值比它大的叶子节点。
5.2、引申出为什么mysql "!="或者“<>” 不走索引。从下图可以知道原因,因为B树的左节点是比右节点小,而且节点有指针很快能找到范围的数据,B树特性+指针的配合这样可以快速找到指定范围数据。
图:
六、mysql为什么用整型自增作为索引比较好。而UUID作为索引效率比较低?
- 索引存储在磁盘,而且树的每个节点分配的空间有大小。整型占空间比较小,这样可以存放多个键值。反之然后UUID占空间比较大。
- 整型比较方便,UUID比较需要先转成ASCII在进行比较