一、概述
主要学习纲要:
1、sklearn数据集与估计器
2、分类算法-k近邻算法
3、k-近邻算法实例
4、分类模型的评估
5、分类算法-朴素贝叶斯算法
6、朴素贝叶斯算法实例
7、模型的选择与调优
8、决策树与随机森林
★★★机器学习步骤:
- 收集数据
- 准备输入数据
- 分析输入数据
- 训练算法
- 测试算法
- 使用算法
机器学习步骤详见:《机学零》——第六节:https://blog.csdn.net/u010132177/article/details/103232316
二、数据划分(第2步:准备数据)
数据一般要分成两类:
- 【训练集】用于训练模型(建立模型) :一般占总数据比例:75%
- 【测试集】用于测试模型(评估模型) :一般占总数据比例:25%
2.1 sklearn数据集
1、数据集划分
2、sklearn数据集接口介绍
3、sklearn分类数据集
4、sklearn回归数据集
2.1.1 数据集划分Api
sklearn.model_selection.train_test_split
2.1.2 sklearn数据集接口
【为什么要用sklearn数据集】:自己的准备的数据集不一定准确,不一定真实,而且费时费力,所以学习中可以使用sklearn现成的数据集;
sklearn.datasets:
- 用于加载获取流行数据集
- datasets.load_*():获取小规模数据集,数据已包含在datasets里
datasets.fetch_*(data_home=None):
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
2.1.2 获取数据集返回的类型
load* 和 fetch*
-
返回的数据类型:datasets.base.Bunch(即字典格式)
-
data:特征数据数组,是 [n_samples * n_features] 的二维numpy.ndarray 数组
-
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
-
DESCR:数据描述
-
feature_names:特征名,新闻数据,手写数字、回归数据集没有
-
target_names:标签名,回归数据集没有
2.1.2-1 其中分类相关的数据集
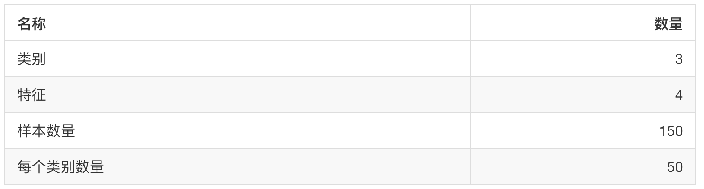
1.sklearn.datasets.load_iris()
- 加载并返回鸢尾花数据集
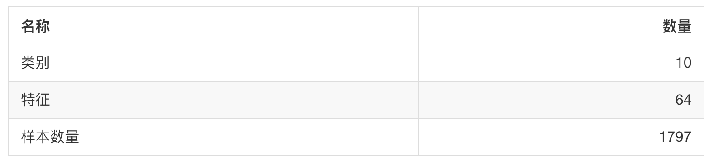
2.sklearn.datasets.load_digits()
- 加载并返回数字数据集
【调用自带数据集代码实例】——分类型数据集:
from sklearn.datasets import load_iris
li=load_iris() #实例化鸢尾花数据集
print('特征值:',li.data)
print('目标值:',li.target)
print('特征名:',li.feature_names)
print('数据描述:',li.DESCR)
'''结果:
特征值:共150行特征
[[5.1 3.5 1.4 0.2]
...
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
目标值:共3类,150个目标数值
[0 0 0...1 1 1...2 2 2]
特征名:4种特征名
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
数据描述:英文,主要描述数据的特征,目标,详细信息,略过
'''
2.2 数据集分割
sklearn.model_selection.train_test_split(*arrays, **options)
- 【x】: 数据集的特征值
- 【y】: 数据集的标签值
- 【test_size】: 测试集的大小,一般为float
- 【random_state】: 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- 【return】: 训练集特征值,测试集特征值,训练标签,测试标签(默认随机取)
2.2.1【分割数据集代码示例】
from sklearn.datasets import load_iris #自带数据集模块
from sklearn.model_selection import train_test_split #数据集分割模块
#【1】实例化鸢尾花数据集
li=load_iris()
#【2】数据集分割:分成训练集(x_train y_trian_);测试集(x_test y_test);注意返回数据顺序;
# 2.1 test_size=0.25,即:分割成测试集占25%,则训练集占比:75%;
x_train,x_test,y_trian,y_test=train_test_split(li.data,li.target,test_size=0.25)
print('训练集是:',x_train,y_trian)
print('测试集是:',x_test,y_test)
'''结果
训练集是(数量占比75%):
[[5.1 3.5 1.4 0.2]
...
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
[0 0 0...1 1 1...2 2 2]
测试集是(数量占比25%):略...
'''
2.3 用于分类的大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- subset: 'train'或'test','all',可选,选择要加载的数据集。训练集的“训练”,测试集的“测试”,两者的“全部”
- data_home: 数据集下载后的存放目录
datasets.clear_data_home(data_home=None)
- 清除目录下的数据
【大数据集调用代码例】——分类型大数据集《新闻类别》
from sklearn.datasets import fetch_20newsgroups #引入自带大数据集模块
news = fetch_20newsgroups(data_home=r'E:PycharmProjectsLearnMachine120newsbydate',subset='all')
print(news.data)
print(news.target)
运行会发很长时间下载数据集,这是一个新闻文章分类相关的数据集,后面会讲到
2.4 sklearn自带的 回归数据集
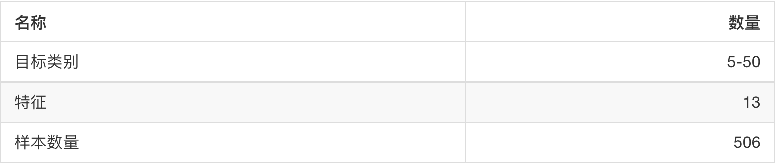
-
sklearn.datasets.load_boston()
- 加载并返回波士顿房价数据集
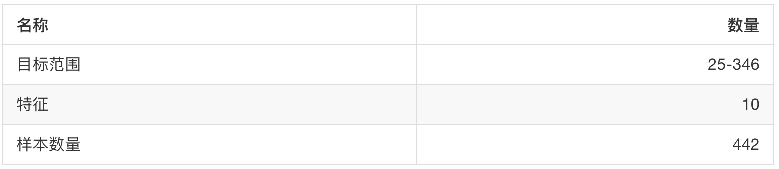
-
sklearn.datasets.load_diabetes()
- 加载和返回糖尿病数据集
【调用sklearn回归数据集示例】《波士顿房价》
from sklearn.datasets import load_boston #导入波士顿数据集包
boston_price=load_boston() #实例化
print('房价集特征名',boston_price.feature_names)
print('房价特征集',boston_price.data)
print('房价目标集',boston_price.target)
print('房价集描述:',boston_price.DESCR)
'''
房价集特征名 ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' 'B' 'LSTAT']
房价特征集 [[6.3200e-03 1.8000e+01 2.3100e+00 ... 1.5300e+01 3.9690e+02 4.9800e+00]...
房价目标集 [24. 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 15. 18.9 21.7 20.4...
房价集描述:(头尾略过)...
Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
...
'''
三、转换器
3.1数据集的标准化处理
回忆之前做特征工程的步骤?
- 实例化 (实例化的是一个转换器类(Transformer))
- 调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
【标准化转换图示】
数据集 ---fit_transform(X)--> 转换后的数据集
【相关单词】
- fit: 适合
- transform: 转型
- preprocessing: 预处理
- StandardScaler: 标准定标器
【标准化函数、库】
from sklearn.preprocessing import StandardScaler
单独使用:
StandardScaler().fit_transform([[1,3,5],[2,3,6]])
以下两个为一个整体:
fit()
transform()
【标准化代码示例】
from sklearn.preprocessing import StandardScaler #预处理:标准化数据集包
#fit_transform()是fit(),和transform()的组合,只要两步即可对数据进行转型
sta=StandardScaler() #【1】
ft=sta.fit_transform([[1,3,5],[2,3,6]]) #【2】
print('ft:',ft)
#fit(),transform()要3步都做才可对数据进行转型
sta2=StandardScaler() #【1】
sta2.fit([[1,3,5],[2,3,6]]) #【2】此处是不能直接输出任何结果的,输出会报错,它只做处理(计算平均值,⽅差等)不返回值
ft2=sta2.transform([[1,3,5],[2,3,6]]) #【3】此处才能返回值
print('ft2:',ft2)
'''结果
ft: [[-1. 0. -1.] [ 1. 0. 1.]]
ft2: [[-1. 0. -1.] [ 1. 0. 1.]]
'''
四、估计器——sklearn机器学习算法的实现Api
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类【实现了算法的API】
- 在估计器中有有两个重要的方法是fit和transform(用法见三)。
- fit方法用于从训练集中学习模型参数 :
- transform用学习到的参数转换数据

4.1估计器的工作流程

1、调用fit: fit(x_train, y_train)
2、向预估器(estimator)输入测试集的数据
- y_predict = predict(x_test)
- 预测的准确率: score(x_test, y_test)
4.2 用于分类的估计器:
sklearn.neighbors k-近邻算法
sklearn.naive_bayes 贝叶斯
sklearn.linear_model.LogisticRegression 逻辑回归
4.3 用于回归的估计器:
sklearn.linear_model.LinearRegression 线性回归
sklearn.linear_model.Ridge 岭回归
五、总结
至此特征工程三大块已经学完,下面,回忆一下