分布式缓存
分布式缓存是为了解决 数据库服务器 和 Web服务器 之间的瓶颈,如果一个网站流量很大这个瓶颈将会非常明显,每次数据库查询耗费的时间将不容乐观。对于更新速度不是很快的站点,可以采用静态化来避免过多的数据查询,可使用Freemaker或Velocity来实现页面静态化。对于更新数据以秒级的站点,静态化也不会太理想,可通过分布式缓存系统来解决,如Redis、MemCache、SSDB等。
分布式缓存系统出现的原因
- 互联网或电商应用系统中,业务需求复杂,必须对整个业务系统进行垂直拆分,以保证各个业务模块清晰并对外提供服务。
- 用户群体广泛就必然存在高并发的问题,如果将引用系统部署在单节点服务器上,势必会对单服务器造成巨大的访问压力,因此需要将系统部署到不同的节点上,同时也要将不同的数据分散到不同的节点上。
- 互联网时代大数据为王,人类正从IT时代走向DT时代,因为数据量大所以要对数据进行分布式处理。
【分布式缓存特性】
高性能:当传统数据库面临大规模数据访问时,磁盘I/O往往成为性能瓶颈,从而导致过高的响应延迟,能够将高速内存作为数据对象的存储介质,数据以key/value形式存储,理想情况下可以获得DRAM级的读写性能;
动态扩展性:支持弹性扩展,通过动态增加或减少节点应对变化的数据访问负载,提供可预测的性能与扩展性;同时最大限度地提高资源利用率;
高可用性:可用性包含数据可用性与服务可用性两方面.基于冗余机制实现高可用性,无单点失效,支持故障的自动发现,透明地实施故障切换,不会因服务器故障而导致缓存服务中断或数据丢失.动态扩展时自动均衡数据分区,同时保障缓存服务持续可用;
易用性:提供单一的数据与管理视图,API接口简单,,且与拓扑结构无关,动态扩展或失效恢复时无需人工配置,自动选取备份节点,多数缓存系统提供了图形化的管理控制台,便于统一维护。
分布式缓存优点
1,提升数据读取速度
2,提升系统扩展能力
3,降低存储成本
分布式缓存应用场景
1,用来缓存Web页面的内容片段,包括HTML、CSS和图片等,多应用于社交网站等;
2,缓存系统作为ORM框架的二级缓存对外提供服务,减轻数据库的负载压力,加速应用访问;
3,缓存包括Session会话状态及应用横向扩展时的状态数据等;,
4,并行处理,涉及大量中间计算结果需要共享;
5,分布式缓存提供了针对事件流的连续查询(continuousquery)处理技术,满足实时性需
6,分布式缓存为事务型应用提供高吞吐率、低延时的解决方案,支持高并发事务请求处理,多应用于铁路、金融服务和电信等领域。
数据存储方案
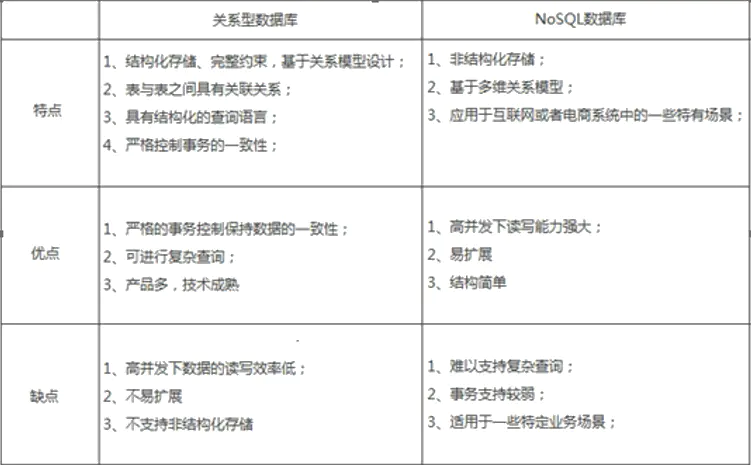
提到数据就不得不说数据库,目前主流的数据存储方案分为两个方向:
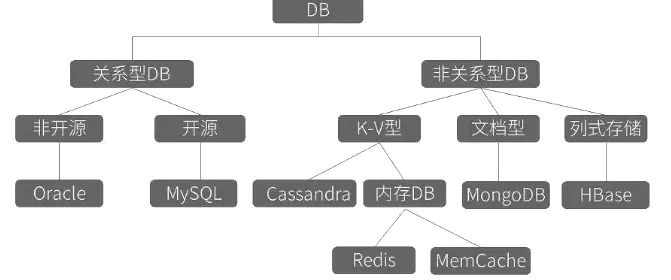
- 关系型数据库
如Oracle、MySQL、DB2、MSSQL... - 非关系型数据库
如MongoDB、HBase、Redis、LevelDB、CouchDB...
在Web开发中,经常要重复从数据库中获取相同的数据,这种重复的操作极大地增加了数据库的负载。缓存是解决这种问题最好的办法。
Redis就是一个高性能的、分布式的内存对象缓存系统,用于在动态应用中减少数据库负载,提升访问速度。
在用户第一次发送请求时,从关系型数据库RDBMS中获取数据并返回,同时将该数据保存到分布式缓存系统中。当用户再次发送请求时,直接从分布式缓存系统中获取,以提高性能。这里使用Redis做集群的主从策略来实现高可用架构。
分布式缓存产品
实际开发中经常使用的分布式缓存系统主要有Redis、MemCache、SSDB,这三者都是KV存储方案,各有优缺,但Redis相比较而言实用性更加广泛。由于Redis特点突出,支持多种数据类型,如String、Hash、Set、List、StoredSet,并且有高可用的解决方案和集群方案,支持水平扩容。也就解决了大部分企业的需求,而MemCache、SSDB相对来说,解决方案并不算那么完善。
Redis与MemCache的区别
- 线程操作
Redis使用单核而Memcache使用多核,也就是说,Redis属于单线程操作,MemCache属于多线程操作。在多个用户同时请求时,Redis是处理完一个请求以后再去处理下一个请求。而MemCache可以同时处理多个请求。
- 数据结构
Redis不仅支持简单的KV类型的数据,同时提供List、Set、Hash等数据结构的存储。
- 数据安全性
Redis和MemCache都是将数据存储在内存中,都属于内存数据库。但是MemCache服务宕机或重启后数据是不可恢复的,而Redis服务宕机或重启后可以恢复。因此Redis可以做持久化,它会将内存数据定期同步到磁盘中。
Redis提供两种持久化策略,默认支持的是RDB持久化以及需要手工开启的AOF持久化。而MemCache仅仅是将数据存储在内存中。
- 数据备份
Redis支持数据备份,需开启master-slave主从策略。
- 过期策略
MemCache在set时就指定了过期时间,而Redis可以通过expire设置Key的过期时间。
- 内存回收
MemCache有内存回收机制,当程序中为它设置的内存大小,一旦存储的数据超过时,它会去自动回收,也就是释放,不然会出现内存溢出的情况。这是因为MemCache的数据都是存储在内存中的。而Redis不会出现这种情况,因为Redis可以将数据持久化到磁盘上。
Redis和SSDB的区别
SSDB是基于Google性能极高的LevelDB作为存储引擎去架构的,特性与Redis基本一致,而且可以和Redis完美整合。SSDB完全可以替换Redis,它与Redis的API兼容并支持Redis的客户端,也就是说,在redis-cli上的所有操作在SSDB中同样适用。由于SSDB该性能的写特性,所以很多时候可以通过Redis+SSDB实现分布式缓存的策略,即"用SSDB写用Redis读"。
Redis
Redis是一个开源的面向键值对Key-Value类型数据的分布式NoSQL数据库系统,它的特点是高性能,适用于高并发的应用场景。可以说Redis纯粹是为应用而产生的。
Redis是一个高性能的KV数据库,并提供多种语言的API。Redis的缺点也很明显,对事务的处理很弱,也无法做太复杂的关系型数据库中的模型。
Redis支持存储的Value类型相对更多,典型的如字符串String、链表List、集合Set、有序集合Zset(sorted set)、哈希类型Hash,这些数据类型都支持push和pop、add和remove,以及取交集、并集、差集等更为复杂的操作。由于这些操作都是原子性的,在此基础上,Redis支持各种不同方式的排序。
与MemCache一样为了保证效率,数据都被缓存在内存中,区别在于Redis会周期性的把更新的数据写入磁盘,或把修改操作写入追加的记录文件中,并且在此基础上实现master-slave主从同步策略,也就是数据可以从主服务器向任意数量的从服务器上同步,从服务器可以关联其他类型的主服务器。因此,Redis的出现很大程度上弥补了MemCahe此类KV存储的不足,在部分场合可以对关系型数据库起到很好的补充作用。