简介
本文主要从常用的top命令入手,说明linux下的cpu 负载是怎么回事,以及帮助大家简单判断cpu负载高的原因。
[poc]
top查看机器负载
我们在linux下使用top指令将会输出如下图所示页面:
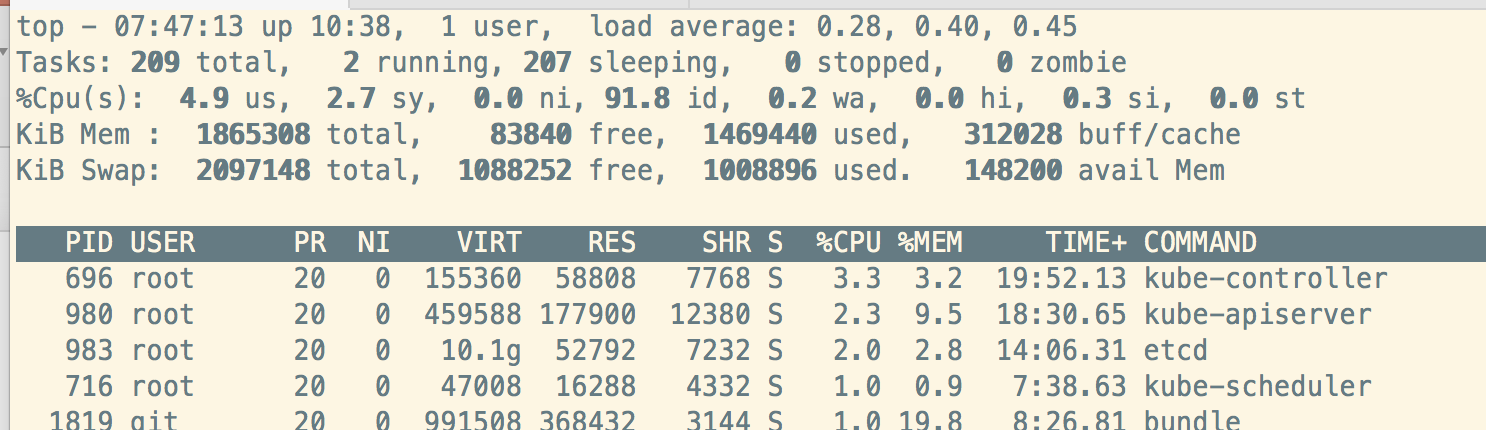
这里的load average以及缩写的us、sy、ni、id、wa、hi、si、st都是些什么意思呢?这些值在一个什么样的区间比较合理呢?如果值超过了合理区间,应该怎么处理呢?这篇将来聊聊这些问题。
load average
load average代表CPU的平均负载值,上面示例中的load average: 0.00, 0.03, 0.00分别表示当前CPU在1分钟、5分钟和15分钟内的平均负载。
这些负载值是怎么来的呢?
这些数据来自于文件/proc/loadavg,内核会负责统计出这些数据。
top和uptime命令显示的内容就来自于这个文件,根据proc的帮助文件可知,这里的值就是单位时间内处于运行状态以及等待磁盘 I/O状态的平均job数量。这里的运行状态和job都是内核的概念,这里进行说明:
1、 对于内核而言,进程和线程都是job
2、 job处于运行状态指job处于内核的运行队列中,正在或等待被CPU调度(用户空间的进程正在运行不代表需要被CPU调度,有可能在等待I/O,也有可能在sleep等等)
因为某一刻(瞬间)等待调度的进程多少并不能反映系统的整体压力,所以这里取了1,5和15分钟的平均值。
那么这个值的大小反映系统什么样的一个压力状态呢?这里以单核CPU为例
1、 小于1: 说明平均每次只有不到一个job在忙,对于单核的CPU来说,完全能处理过来
2、 等于1: 说明平均每次刚好有一个job在忙,对于单核的CPU来说,刚好能处理过来
3、 大于1: 说明平均每次有多于一个job在忙,对于单核的CPU来说,由于一次只能处理一个任务,所以肯定有任务在等待,说明系统负载较大,调度不过来,有job需要等待
对于单核cpu,一旦大于1,就说明job得不到及时调度,系统性能将会受到影响。对于2核心来说,该值大于2才说明cpu忙不过来。
那这个值多大比较合适呢?其实没有一个标准值,但一般的做法是预留一定的空间来应对系统负载的波动,建议控制在“0.7核数”以内,比如4核,那么0.74=2.8比较合适,一旦超过这个值,需要分析原因并着手解决。
top之%Cpu(s)
load average通过统计等待运行的平均job数量来推断CPU的繁忙程度,而%Cpu(s)则直接统计CPU处于不同状态的时间,比上面的load average更直观,所以在实际上也被使用的更多。
总体来说,CPU会处于下面三种状态中的一种:
1、 Idle: 处于空闲状态,没有任务需要调度
2、 User space: 正在运行user space的代码(处于用户态)
3、 Kernel: 正在运行内核的代码(处于内核态)
对上面这三种状态,内核又进一步细分为很多状态,这里以上面输出的8种状态为例进行说明:
1、 2.5 us : 表示CPU有2.5%的时间在运行用户态代码(即在运行用户态程序)
2、 1.8 sy : 表示CPU有1.8%的时间在运行内核态代码。内核负责管理系统的所有进程和硬件资源,所有的内核代码都运行在内核态,当用户态进程需要访问硬件资源时,如分配内存,读写I/O等,也需要通过系统调用进入内核态运行内核代码。%sy高说明内核占用太多资源,或者用户进程发起了太多的系统调用。
3、 3.1 ni : 表示CPU有3.1%的时间在运行niceness不为0的进程代码。默认情况下,进程的niceness值都为0,但可以通过命令nice来启动一个进程并指定其niceness值,niceness的取值范围是-20到19,值越小,表示优先级越高,越优先被内核调度。
4、 90.5 id : 表示CPU有90.5%的时间处于空闲状态
5、 1.7 wa : 表示CPU有1.7%的时间处于I/O等待状态。通常情况下,当CPU遇到一个I/O操作时,会先触发I/O操作,然后去干别的,等I/O操作完成后,CPU再接着继续工作,但如果这时系统比较空闲,CPU没有别的事情可以做,那么CPU将处于等待状态,这种处于等待状态的时间将会被统计进I/O wait,也就是说CPU处于I/O wait状态即CPU闲着没事干在等I/O操作结束,和idle几乎是一样的。这个值高说明CPU闲且I/O操作多或者I/O操作慢,但低并不能说明没有I/O操作或者I/O操作快,有可能是CPU在忙别的,所以这只是一个参考值,需要和其他的统计项一起来分析。
6、 0.0 hi & 0.4 si : 这两个值反映了CPU有多少时间花在了中断处理上,hi(hardware interrupts)是硬件中断,si(softirqs)是软件中断。硬件中断一般由I/O设备引起,如网卡、磁盘等,发生硬件中断后,CPU需要立即处理,当硬件中断中需要处理的事情很多时,内核会生成相应的软中断,然后将耗时且不需要立即处理完成的操作放在软中断中执行,比如当网卡收到网络包时,需要CPU立即把数据拷贝到内存中去,因为网卡自带的缓存较小,如果不及时处理的话后面的数据包就进不来,导致丢包,当数据拷贝到内存中之后,就不需要那么着急的处理了,这时候可以将处理数据包(协议栈)的代码放在软中断中执行。本人不是内核专家,关于软中断的部分请参考Understanding the Linux Kernel, 3rd Edition
7、 0.0 st : %st和虚拟机有关,当系统运行在虚拟机中时,当前虚拟机就会和宿主机以及其它的虚拟机共享CPU,%st就表示当前虚拟机在等待CPU为它服务的时间。该值越大,表示物理CPU被宿主机和其它虚拟机占用的时间越长,导致当前虚拟机得不到充足的CPU资源。如果%st长时间大于0,说明CPU资源得不到满足,这时可以考虑将虚拟机移到其它机器上,或者减少当前机器运行的虚拟机数量。
上面这些统计项的总和等于100%,除了%idle之外,其它的任何一项数值过高都代表系统有问题,下面进行问题解决。
负载过高问题处理
1、 %us过高 : 表示有用户态进程占用了过多的CPU,通过top命令可以很清楚的看到是哪个进程,如果这不是预期的行为,可以通过kill命令杀死相应的进程或者重启它
2、 %sy过高 : 如果只是偶尔过高的话,不用担心,但如果是持续走高的话,就需要重视,有可能是某些进程的系统调用太频繁,比如进程不停的往控制台输出日志,但如果用户态的进程都没有问题,那可能是内核里面的代码出现了问题,尤其是代码写的不好的驱动模块
3、 %ni过高 : 说明有人用nice程序运行了比较耗CPU的进程。如果niceness值大于0的话,就没什么好担心的,因为它的优先级比默认优先级要低,不会影响CPU性能,但最好还是确认一下该进程不会抢占系统的其它资源,如内存、磁盘I/O等,避免对系统整体性能造成影响。如果niceness值小于0的话,表示该进程优先级高且占用CPU资源多,需要确保该进程占用的CPU资源是符合预期的,如果不是,可以用top命令把它找出来并kill掉或者重启。
4、 %wa过高 : 意味着系统中有进程在做大量的I/O操作,或者在读写速度比较慢的I/O设备,比如频繁的读写磁盘,这时可以通过iotop命令来查看是哪些进程占I/O,然后再针对不同的进程做相应的处理;还有一种情况就是系统在频繁的使用交换分区,这时需要解决的就是内存的问题,而不是I/O的问题。
5、 %hi或者%si过高 : %hi过高一般是硬件出问题了,%si过高一般是内核里面的代码出问题了
6、 %st 过高 : 正如上面介绍介绍的那样,%st过高表示当前虚拟机得不到足够的CPU资源。这时可以考虑将当前虚拟机搬迁到其它的主机上,或者想办法降低当前主机的负载,比如关掉一些其它的虚拟机。
总结
load average和%Cpu(s)以不同的方式给出了当前主机的CPU负载情况,通过%Cpu(s)我们可以看到系统当前的实时负载,现在很多监控系统每隔一段时间都会采集一次%Cpu(s),然后存储起来以图形的方式展示出来,对每个节点做负载监控很重要,防止节点出现问题。