python练习——列表练习
问题描述:
编写一个函数,读取文件 words.txt ,建立一个列表,其中每个单词为一个元素。 编写两个版本,一个使用 append 方法,另一个使用 t = t + [x] 。 那个版本运行得慢?为什么?
前提知识:
1. 时间和日期,菜鸟教程
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import time; # 引入time模块
ticks = time.time()
print "当前时间戳为:", ticks
当前时间戳为: 1459994552.51
时间戳单位最适于做日期运算。但是1970年之前的日期就无法以此表示了。太遥远的日期也不行,UNIX和Windows只支持到2038年。

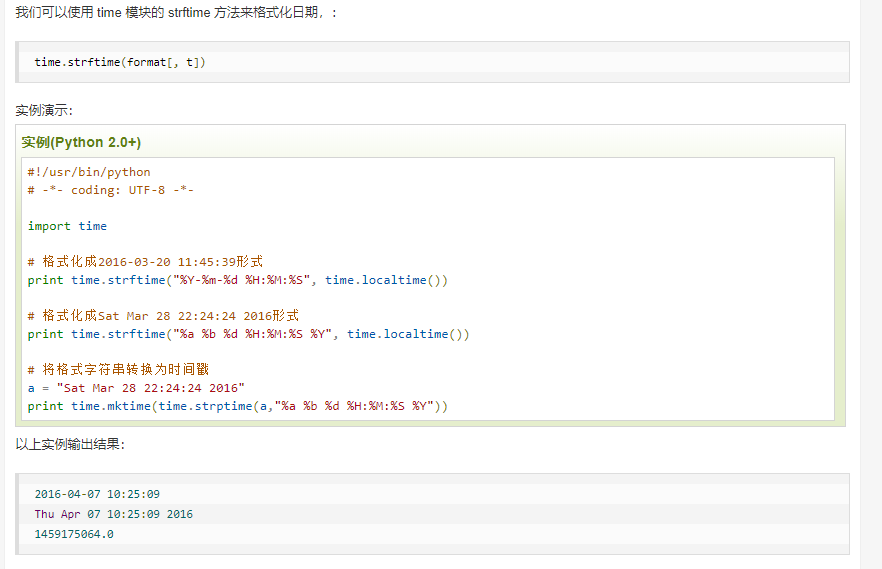
python中时间日期格式化符号:
- %y 两位数的年份表示(00-99)
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %H 24小时制小时数(0-23)
- %I 12小时制小时数(01-12)
- %M 分钟数(00=59)
- %S 秒(00-59)
- %a 本地简化星期名称
- %A 本地完整星期名称
- %b 本地简化的月份名称
- %B 本地完整的月份名称
- %c 本地相应的日期表示和时间表示
- %j 年内的一天(001-366)
- %p 本地A.M.或P.M.的等价符
- %U 一年中的星期数(00-53)星期天为星期的开始
- %w 星期(0-6),星期天为星期的开始
- %W 一年中的星期数(00-53)星期一为星期的开始
- %x 本地相应的日期表示
- %X 本地相应的时间表示
- %Z 当前时区的名称
- %% %号本身
太多了,可以点击连接查看。
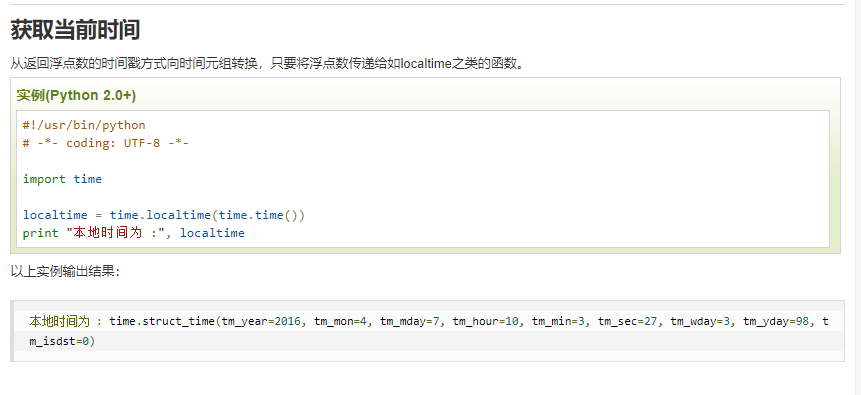
在这里只用到了
获取当前时间,是一个很长的数字,应该是从1970到现在的毫秒数。
2. Python open()函数
在这里用到了open函数,给出以下定义:
open(name[, mode[, buffering]])
- name : 一个包含了你要访问的文件名称的字符串值。
- mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
- buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。


代码:
# 编写一个函数,读取文件 words.txt ,建立一个列表,其中每个单词为一个元素。
# 编写两个版本,一个使用 append 方法,另一个使用 t = t + [x] 。
# 那个版本运行得慢?为什么?
import time
def make_word_list1():
"""
读取文件中的单词
:return:
"""
t = []
# 读取文件
fin = open('words.txt')
for line in fin:
word = line.strip()
t.append(word)
return t
def make_word_list2():
"""
使用t=t+word
:return:
"""
t = []
fin = open('words.txt')
for line in fin:
word = line.strip()
t = t + [word]
return t
if __name__ == '__main__':
start_time = time.time()
t = make_word_list1()
spend_time = time.time() - start_time
print(len(t))
print(t[:10])
print(spend_time, 'seconds')
start_time = time.time()
t = make_word_list2()
elapsed_time = time.time() - start_time
print(len(t))
print(t[:10])
print(elapsed_time, 'seconds')