fastnlp无法使用spacy,报错[E050] Can't find model 'en'. It doesn't seem to be a shortcut link, a Python package or a valid path to a data directory.
此方法只能使用与fastnlp中,不适用spacy
spacy没有办法修改,只能修改fastnlp调用spacy处的地方,将spacy调用的地方设置成为已经下载好的en_core_web_sm。怎么修改?
找到报错的位置,然后找到load=‘en’的地方,改成en_core_web_sm即可。
fastNLP版本为0.6.0,spacy为最新版2.3.5,注意:en_core_web_sm2.3.0就可以使用,百度网盘文末po出。
暂时记录下fastnlp调用处的修改:
- fastNLP->io>pipe->utils.py 83行 if lang != 'en': 改为 if lang != 'en_core_web_sm':,因为pipe有很多类,所以都要修改,可以ctrl+F,查找'en'然后修改即可
- fastNLP->io>pipe->classification.py 40行同样改成1一样的即可。
实验代码:
from fastNLP.io import SST2Pipe
pipe = SST2Pipe()
databundle = pipe.process_from_file()
vocab = databundle.get_vocab('words')
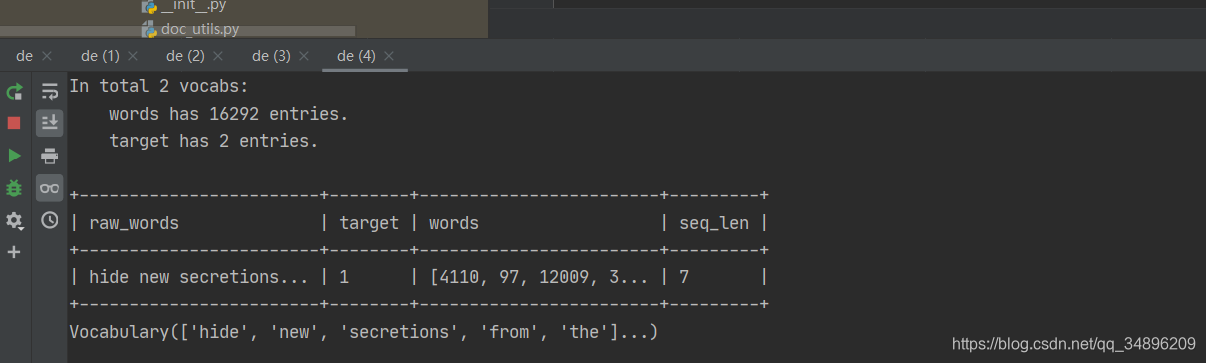
print(databundle)
print(databundle.get_dataset('train')[0])
print(databundle.get_vocab('words'))
en_core_web_sm2.3.1链接:https://pan.baidu.com/s/1U5BTLU1jO0TecESHJ0X7eA
提取码:fow9
但是有一个问题就是,使用spacy官方的代码仍然不能分句:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp('这是一个句子。')
# tokenize功能
for token in doc:
print(token)
输出:
这是一个句子
。
不知道为什么。。。