用scrapy建立一个project,名字为Spider
scrapy startproject Spider
因为之前一直用的是电脑自带的python版本,所以在安装scrapy时,有很多问题,也没有装成功,所以就重新给本机安装了一个python3.+,然后安装scrapy和其他的库。新建的Spider文件夹结构如图
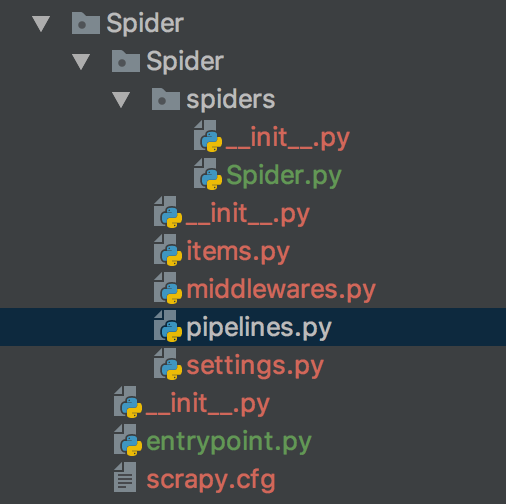
其中Spider.py 是spider程序代码
items.py 文件中定义一些字段,这些字段用来临时存储你需要保存的数据。方便后面保存数据到其他地方,比如数据库 或者 本地文本之类的。
middlewares.py 是一个下载中间件
pipelines.py 中存储自己的数据,我们需要将这些爬取到数据存储到数据库当中
settings.py 是一些设置,比如mysql、mongodb、代理ip
entrypoint.py
然后我是根据教程抓取了dingdian小说网站的所有小说的信息,初始调试的时候,遇见类似下面提示的错误
DEBUG: Crawled (403) <GET http://zipru.to/robots.txt> (referer: None) ['partial']
然后在settings.py中添加了user-Agent,然后就没有出现下面的403了,这是因为这个文件中规定了本站点允许的爬虫机器爬取的范围(比如你不想让百度爬取你的页面,就可以通过robot来限制),因为默认scrapy遵守robot协议,所以会先请求这个文件查看自己的权限,而我们现在访问这个url得到
DEBUG: Crawled (403) <GET http://zipru.to/robots.txt> (referer: None) ['partial']
然后在初始调试的时候设置了固定的一页进行数据抓取,然后就遇见了类似下图的错误
2016-01-13 15:01:39 [scrapy] DEBUG: Filtered duplicate request: - no more duplicates will be shown (see DUPEFILTER_DEBUG to show all duplicates)
然后百度得,在scrapy engine把request给scheduler后,scheduler会给request去重,所以对相同的url不能同时访问两次,所以在修改了抓取的页面的url后,就不会出现上述错误。
然后代码写的很随性,在抓取的时候顶点小说会封ip,因为我没有对数据抓取settings.py中设置dewnload_delay,所以会有封ip,想要用代理ip,但是在网上找的代理ip总是连接不上,所以就放弃了。
Spider.py
#-*-coding:utf-8-*- import re import scrapy import time from bs4 import BeautifulSoup from scrapy.http import Request from Spider.items import SpiderItem class spider(scrapy.Spider): name = 'Spider' allowed_domains = ['x23us.com'] bash_url = 'http://www.x23us.com/class/' bashurl = '.html' def start_requests(self): for i in range(1, 11): url = self.bash_url + str(i) + '_1' + self.bashurl print(url) yield Request(url, self.parse) def parse(self, response): soup = BeautifulSoup(response.text,'lxml') max_nums = soup.find_all('div',class_ = 'pagelink')[0] max_num = max_nums.find_all('a')[-1].get_text() print(max_num) bashurl = str(response.url)[:-7] for num in range(1, int(max_num) + 1): url = bashurl + '_' + str(num) + self.bashurl print(url) yield Request(url, self.get_name) def get_name(self, response): soup = BeautifulSoup(response.text,'lxml') tds = soup.find_all('tr', bgcolor='#FFFFFF') for td in tds: novelname = td.find_all('a')[1].get_text() novelurl = td.find_all('a')[1]['href'] author = td.find_all('td')[-4].get_text() serialnumber = td.find_all('td')[-3].get_text() last_update = td.find_all('td')[-2].get_text() serialstatus = td.find_all('td')[-1].get_text() print("%s %s %s %s %s %s"%(novelname,author,novelurl,serialnumber,last_update,serialstatus)) item = SpiderItem() item['name'] = novelname item['author'] = author item['novelurl'] = novelurl item['serialstatus'] = serialstatus item['serialnumber'] = serialnumber item['last_update'] = last_update yield item
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class SpiderItem(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() #小说名 author = scrapy.Field() #作者名 novelurl = scrapy.Field() #小说地址 serialstatus = scrapy.Field() #状态 serialnumber = scrapy.Field() #连载字数 last_update = scrapy.Field() #文章上次更新时间
settings.py中添加的设置,因为在存储的时候,是将数据存储在本地的mongodb的test.novel中
BOT_NAME = 'Spider' SPIDER_MODULES = ['Spider.spiders'] NEWSPIDER_MODULE = 'Spider.spiders' ITEM_PIPELINES = { 'Spider.pipelines.SpiderPipeline': 300, } MONGODB_SERVER = "localhost" MONGODB_PORT = 27017 MONGODB_DB = "test" MONGODB_COLLECTION = "novel" USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo from scrapy.conf import settings from scrapy.exceptions import DropItem from scrapy import log class SpiderPipeline(object): def __init__(self): connection=pymongo.MongoClient( settings['MONGODB_SERVER'], settings['MONGODB_PORT'] ) db=connection[settings['MONGODB_DB']] self.collection=db[settings['MONGODB_COLLECTION']] def process_item(self, item, spider): valid = True for data in item: if not data: valid = False raise DropItem('Missing{0}!'.format(data)) if valid: self.collection.insert(dict(item)) log.msg('question added to mongodb database!', level=log.DEBUG, spider=spider) return item
entrypoint.py
from scrapy.cmdline import execute execute(['scrapy', 'crawl', 'Spider'])
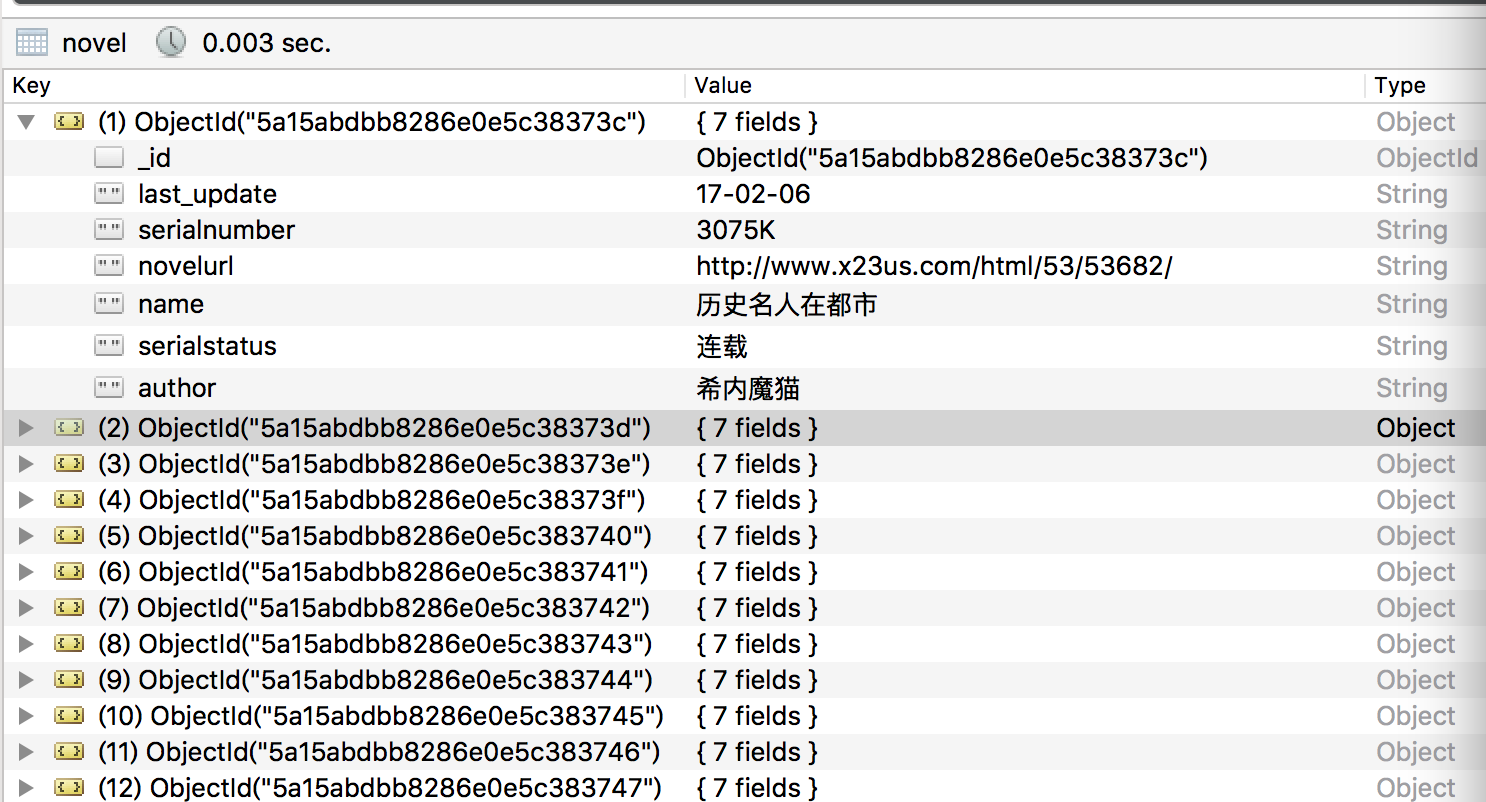
mongodb中的存储结构如图
在抓取数据的过程中,如果download将request的下载失败,那么会将request给scrapy engine,然后让scrapy engine稍后重新请求。
有当scheduler中没有任何request了,整个过程才会停止。