模块 分为3类,分别为内置模块,第三方模块,自定义模块。以下介绍几个常用的模块。
模块导入顺序及书写顺序
所有的模块导入都应该尽量往上写,
顺序为:内置模块-->第三方扩展模块-->自定义模块
模块不会重复被导入
__ name__
在模块中有一个变量__name__,
当我们直接执行这个模块的时候,__name__ =='__main__',
当我们执行其他模块时,在其他模块引用这个模块的时候,这个模块中的__name__='模块的名字'
重命名模块
提高代码的兼容性。
# import time as t
# oracle
# mysql
# if 数据库 == ‘oracle’:
# import oracle as db
# elif 数据库 == ‘mysql’:
# import mysql as db
time 模块
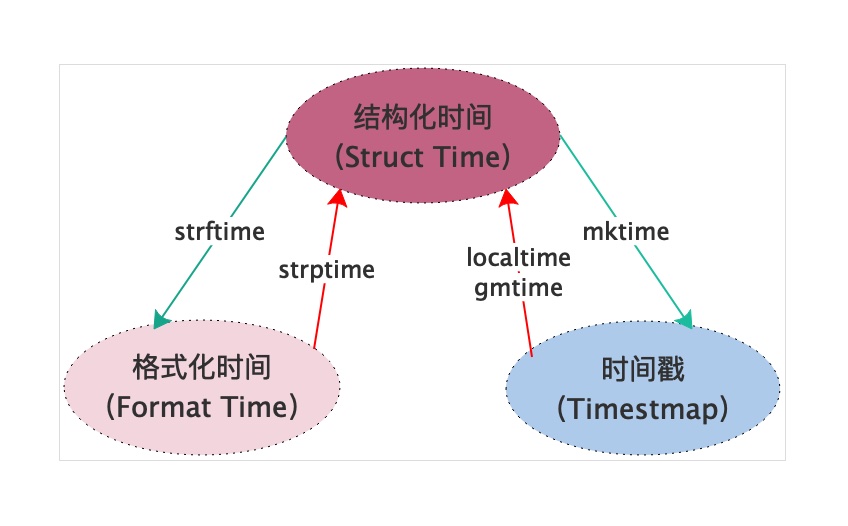
格式化时间: 给 人 看的。表示的是普通的字符串形式的时间。
时间戳: float时间 , 给计算机看的。 表示的是从1970年1月1日0:00:00开始按秒计算的偏移量。
结构化时间: 元组, 运算用的。struct_time元组共有九个元素,分别为(年、月、日、时、分、秒、一年中第几周,一年中第几天,夏令时)
# print(time.strftime("%Y-%m-%d %a %H:%M:%S"))
#year month day HOUR MINUTE SECOND
time.time() 时间戳
time.sleep() 延时
time.strftime() 格式化时间,按照规定的格式 输出时间
time.localtime() 时间戳 --> 结构化时间 。 # 本地时区的
time.localtime().tm_year 等等 取具体的年月份
time.gmtime() # UTC时区的时间
time.strptime('2000-12.31','%Y-%m.%d') 格式化时间 --> 结构化时间
time.strftime('%m/%d/%Y %H:%M:%S',time.localtime(3000000000)) 结构化时间 --> 格式化时间
不同时间格式的转换
datetime 模块
datetime模块一般用于时间的加减。
print(datetime.datetime.now()) # 返回当前时间
print(datetime.date.fromtimestamp(time.time())) # 返回 年-月-日
# 时间的加减--timedelta() 参数默认为days
print(datetime.datetime.now()+datetime.timedelta(3)) # 在当前时间上+3天
print(datetime.datetime.now()+datetime.timedelta(-3)) # 在当前时间上-3天
# 加减小时。传hours=3即+3小时,hours=-3 即减3小时
# 加减分钟 。同小时
# 时间替换
c_time = datetime.datetime.now()
print(c_time.replace(hour=2,second=3,minute=1))
random模块
这个模块 主要用于生成随机字符。
玩游戏掷骰子、随机验证码,抽奖系统都可以使用这个模块进行开发编程。
开发过程中,经常用到的知识点如下:
# 字母 = chr(数字) # 可以用此来开发一个数字和字母混杂的随机验证码
import random
print(random.random()) # 返回的是0到1之间的小数
print(random.randint(1,3)) # 返回的是 大于1且小于等于3之间的额整数
print(random.randrange(1,4)) # 返回的是 大于1且小于4之间的整数
print(random.uniform(1,3)) # 返回的是 大于1 小于3 的小数
print(random.choice([1,23,4,5,6])) # 返回的是列表中的任意一个元素
print(random.sample([1,2,4],n)) # 以列表形式返回列表中任意n个元素的组合。n不能大于列表的长度
lis = [1,3,4,5,7,8]
random.shuffle(lis) # 打乱lis内元素的顺序,相当于洗牌
print(lis)
os模块
负责程序与操作系统交互,多用于文件处理.
当前文件可以使用 内置变量 __file__
os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd
os.curdir # 返回当前目录: ('.')
os.pardir # 获取当前目录的父目录字符串名:('..')
os.makedirs('dir1/dir2') # 可生成多层递归目录
os.removedirs('dirname1') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() # 删除一个文件
os.rename("oldname","new") # 重命名文件/目录
os.stat('path/filename') # 获取文件/目录信息
os.sep # 操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep # 当前平台使用的行终止符,win下为"
",Linux下为"
"
os.pathsep # 用于分割文件路径的字符串
os.name # 字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") # 运行shell命令,直接显示
os.environ # 获取系统环境变量
os.path.abspath(path) # 返回path规范化的绝对路径
os.path.split(path) # 将path分割成目录和文件名二元组返回
os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) # 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) # 如果path是绝对路径,返回True
os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) # 返回path的大小
sys模块
用于提供对python解释器相关的操作
sys.argv # 命令行参数List,第一个元素是程序本身路径
sys.exit(n) # 退出程序,正常退出时exit(0)
sys.version # 获取Python解释程序的版本信息
sys.maxint # 最大的Int值
sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform # 返回操作系统平台名称
sys.stdin # 标准输入
sys.stdout # 标准输出
sys.stderror # 错误输出
sys.modules # 已导入的模块,以字典形式返回
sys.argv 举例:
ret = sys.argv
name = ret[1]
pwd = ret[2]
if name == 'alex' and pwd == 'alex3714':
print('登陆成功')
else:
print("错误的用户名和密码")
sys.exit()
print('你可以使用计算器了')
collections模块
namedtuple 命名元组
# from collections import namedtuple
# Point = namedtuple('point',['x','y','z'])
# p1 = Point(1,2,3)
# p2 = Point(3,2,1)
# print(p1.x)
# print(p1.y)
# print(p1,p2)
纸牌花色和数字
from collections import namedtuple
Card = namedtuple('card', ['suits', 'number'])
c1 = Card('红桃', 2)
print(c1)
print(c1.number)
print(c1.suits)
queue 队列
先进先出,里面的数据取完后,会阻塞在那里,不继续往下执行。
import queue
q = queue.Queue()
q.put([1,2])
q.put(3)
q.put(4)
print(q.get()) # [1,2]
print(q.get()) # 3
print(q.get()) # 4
print(q.get()) # 阻塞
print(q.qsize()) # 打印当前队列中剩余的元素数量
deque 双端队列
两端都可以存取
from collections import deque
dq = deque([1,2]) # deque([1, 2])
dq.append(3) # deque([1, 2, 3]) 从后面放入数据
dq.appendleft(0) # deque([0, 1, 2, 3]) 从前面放入数据
dq.insert(2,4) # deque([0, 1, 4, 2, 3]) 在指定位置插入数据
dq.pop() # deque([0, 1, 4, 2]) 从后面取数据
dq.popleft() # deque([ 1, 4, 2]) 从前面取数据
print(dq)
有序字典 OrderedDict
from collections import OrderedDict
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(od) # OrderedDict的Key是有序的
print(od['a'])
for k in od:
print(k)
默认字典 defaultdict
from collections import defaultdict
d = defaultdict(lambda : 5)
# d['k'] = 4
print(d['k'])
json模块 和 pickle 模块
把某个数据类型转化为字符串的过程称之为序列化。
序列化的优点:
- 持久保存。内存只是临时保存数据的,无法永久保存。当我们断电或者重启程序,内存中关于这个程序的之前的数据都会被清空。但是如果我们在断电或重启程序前将所需的数据都保存到文件中,下次还可以再从文件中取出之前保存的数据,然后执行,这就是序列化。
- 跨平台交互。序列化不仅可以把序列化后的数据保存到文件写入硬盘,还可以通过网络传输的方式发送给别人的程序,如果发送数据和接受数据的双方约定好使用一种序列化的格式,那么便打破了平台、语言化差异带来的限制。实现跨平台数据的交互。
json模块
其他编程语言也在用,序列化出的数据其他语言也能用。
- 只能很少一部分的数据类型可以使用json转化为字符串,如数字,字符串,列表,字典,元组。
- 通用的序列化格式
# 代码演示
# 序列化后的数据保存到内存中dumps(),取loads()
import json
struct_data = {
0:'name',
1:'age',
2:'sex'
}
# 序列化
data = json.dumps(struct_data) # 将字典序列化成字符串,保存到内存中去
print(data,type(data))# {"0": "name", "1": "age", "2": "sex"} <class 'str'>
# 注意:无论数据是怎样创建的,只要满足json格式(如果是字典,则字典内元素都是双引号),就可以json.loads出来,不一定非要dumps的数据才能loads出来
# 反序列化
data = json.loads(data)
print(data,type(data)) # {'0': 'name', '1': 'age', '2': 'sex'} <class 'dict'>
# 序列化的数据保存到文件中json.dump(data,obj)
# 取数据 json.load(obj)
import json
struct_data = {
0:'name',
1:'age',
2:'sex'
}
# 序列化
with open('json序列化.txt','w',encoding='utf8') as f:
json.dump(struct_data,f)
# 反序列化
with open('json序列化.txt','r',encoding='utf8') as f:
data = json.load(f)
print(data)
关于f-string格式化
f-string 格式化也可以将字典以字符串的形式写进文件中,但是写入的 字典 不符合 字典内元素都是用双引号的要求,所以无法将从文件中读取出的字符串形式的字典转化为字典类型。json也无法load出这个字典。
pickle模块
pickle序列化只能是python自己使用。相对于json的优点,就是可以序列化python中的所有数据类型,包括对象。
- 只能python自己使用
- 可以序列化python中的所有数据类型,包括对象
- 序列化保存到文件中的数据是二进制形式。无法读懂。
# 代码演示
# 保存到内存中
import pickle
struct_data = {
0:'name',
1:'age',
2:'sex'
}
# 序列化
data = pickle.dumps(struct_data)
print(data,type(data)) # 二进制类型
# 反序列化
data = pickle.loads(data)
print(data,type(data)) # 字典类型
# 代码演示
# 保存到文件中
import pickle
struct_data = {
0:'name',
1:'age',
2:'sex'
}
# 序列化(注意:pickle模块需要使用二进制存储,即wb 模式存储)
with open('pickle序列化.txt','wb',encoding='utf8') as f:
pickle.dump(struct_data,f)
# 反序列化
with open('pickle序列化.txt','rb',encoding='utf8') as f:
data = pickle.load(f)
print(data)
从上方的代码演示可以看出,json和pickle使用方式一样,只是pickle在dump和load的时候操作文件都是以二进制的模式进行的。
hashlib模块
这个模块主要用于明文加密
hash是什么
hash是一种算法,该算法接受传入的内容,经过运算得到一串hash值。
hash值的特点:
- 知道传入的内容一样,得到的hash值一样,可用于非明文密码传输时密码校验
- 不能由hash值反解成内容,即可以保证非明文密码的安全性。
- 只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的,可以用于对文本的hash处理。
# 代码演示
import hashlib
m = hashlib.md5()
m.update('hello'.encode('utf8'))
print(m.hexdigest())
在网络中存在以撞库形式来破解密码的,为了防止密码被撞库,我们可以使用另一个hmac模块,它内部对我们创建key和内容做过某种处理后再加密。
# 如果要保证hmac模块最终结果一致,必须保证:
# 1. hmac.new()括号内指定的初始key一样
# 2. 无论update多少次,检验的内容累加到一起是一样的内容
import hmac
h1 = hmac.new(b'hash')
print(h1,type(h1))
h1.update(b'hello')
h1.update(b'world')
print(h1.hexdigest()) # 905f549c5722b5850d602862c34a763e
h2 = hmac.new(b'hash')
h2.update(b'helloworld')
print(h2.hexdigest()) # 905f549c5722b5850d602862c34a763e
logging模块
记录日志使用的模块