Preface
从AIC回来后,做了一些Policy Gradient的工作。主要是觉得RL是一个有意思的领域,而深度网络逼近对这个问题提供了良好的可预期的解决方案。本来想找些程序先做个参考,发现都是些打游戏场景;之前看textbook的时候,对Figure 17.1(Artificial Intelligence: A Modern Approach)的例子印象深刻,觉得是个良好的案例,于是用这个场景;另外,做的过程中开始转gluon,在这个例子上试了下,发现还挺顺手的,就把之前的symbol接口全改了。
Code
程序是github上的Task1
Policy Gradient
正式的说明自有大牛阐述,这里只是为了保持结构完整。RL的两种途径分别是Value-Based和Policy-Based,Policy的好处在于其简洁性,直接将state映射到action。
Works
而Ploicy Gradient,在做的过程中,给我一种和以前的label-data learning极为相似的感觉,相当于都是通过试错法来了解数据,只不过label-data的对应结构关系不同。
所以,最开始时,对backward那部分的想法是,通过在最末接入一个SoftmaxCrossEntropyLoss,将选出来的action作为label,通过将outgrad作为reward的函数,控制优化的方向和幅度。最后的版本里面,Loss被删除,直接用sotmax作激活函数得到action的概率分布,然后用具有one_hot型编码的outgrad进行backward(这要感谢gluon的功能)。
另一个需要说明的是exploration-exploitation,之前在看一些非正式的介绍时,看到这一段,总会习惯性地认为需要采取类似于遗传算法的概率操作:设定一个阈值,确定是否放弃系统给出的action,如果放弃,再随机选一个action出来。
将这两种想法结合起来,发现最后没有收敛到理想方向(第一个commit便是)。于是,在后面debug时,Loss那部分就被砍掉了。但给我感觉,对系统影响最大的应该是exploration-exploitation那部分,后面查看Reinforcement Learning: An Introduction第13章,发现应该是进行采样(实际上,如果按照统计学习的惯性思维,也应该是使用采样的样本代替期望)。多亏16年夏天啃了会PRML(不然什么叫sample都不知道 (⊙﹏⊙)b),用了一个rejection sampling对softmax的输出进行采样:
import numpy as np
N=100
net_out = np.array([1,5,3,1])
net_out = 1.*net_out/net_out.sum()
hist=[]
for i in xrange(1000):
act_list = np.random.randint(0, 4, (N,))
prob_list = np.random.uniform(size=(N,))
idx = list(net_out[act_list] > prob_list).index(True) #np.where(net_out[act_list] > prob_list)
hist.append(act_list[idx])
h=np.histogram(hist, bins=4)[0]
print h*1./h.sum()
Jul-18,2018
最近要做一个负采样的迭代器,手写的采样太慢,扩充为多线程后问题依然严重。又查了下,发现早就有内建函数:1, 2
# method I
import numpy as np
numpy.random.choice(numpy.arange(1, 7), p=[0.1, 0.05, 0.05, 0.2, 0.4, 0.2])
# method II
from scipy.stats import rv_discrete
numbers = (1,2,3)
distribution = (1./6, 2./6, 3./6)
random_variable = rv_discrete(values=(numbers,distribution))
random_variable.rvs(size=10)
速度蹭蹭的!
Result
后面把结果打出来,发现收敛得还行,对比了一下R=-0.04时的结果,textbook上的结果是这样的:
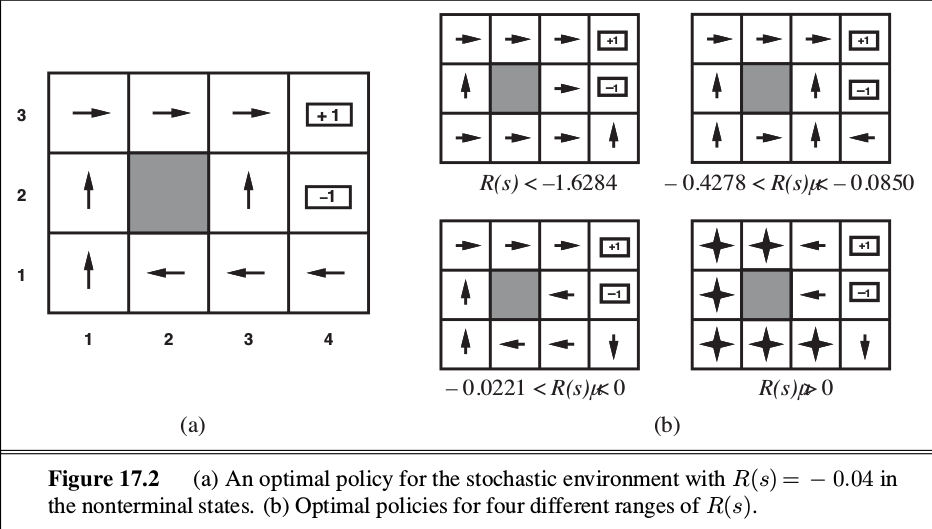 Figure 1. Ground Truth
Figure 1. Ground Truth
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| → | → | → | +1 |
| ↑ | Wall | ↑ | -1 |
| ↑ | → | ↑ | ← |
Tab 1. Net Prediction
可以看到,存在一些出入,但这个结果和-0.4278<R<-0.0850的情况下的ground truth 是相同的,这似乎就是说的Policy Gradient容易陷入local optima的情况。
2018.3.25
局部最优的情况参考 Sutton Reinforcement Learning: An Introduction中提及的蒙特卡洛方法导致的方差较大问题。