该系列博客的目的是为了学习一遍数据结构中常用的概念以及常用的算法,为笔试准备;主要学习过程参考王道的《2018年-数据结构-考研复习指导》;
已总结章节:
上篇博客《数据结构与算法》-2-线性表中介绍了线性结构中的线性表的定义、基本操作以及线性表的两种存储方式:顺序存储与链式存储;这一篇博客将主要介绍线性结构中的受限线性表:栈、队列, 线性表推广:数组。
主要包含的内容有:
- 栈的基本概念与操作、顺序存储与链式存储;
- 队列的基本概念与操作、顺序存储与链式存储;
- 栈、队列的实际应用;
- 特殊矩阵的压缩存储;
其知识框架如下图所示:
1. 栈
1.1 栈的基本概念
1.1.1 栈的定义
栈(Stack):
只能在一端执行插入或删除操作的线性表;
栈顶(Top):
线性表允许执行插入或删除操作的一端;
栈底(Botton):
线性表不允许执行插入或删除操作的一端;
注意:根据栈的定义可以得到,栈是先进后出的线性表;
1.1.2 栈的基本操作
InitStack(&S):初始化一个空栈S;
StackEmpty(S):判断S是否为空栈;
Push(&S, x):进栈操作;若未满,则将x进栈,作为栈顶;
Pop(&S, &x):出栈操作;若非空,则将栈S的栈顶元素弹出,并用x返回;
GetTop(S, &x):读取栈顶元素;若非空,用x返回栈顶元素;
ClearStack(&S):销毁栈,并释放其存储空间;
1.2 栈的顺序存储结构
1.2.1 顺序栈
栈的顺序存储称为顺序栈,它是利用一组地址连续的存储单元存放从栈底到栈顶的所有数据元素,同时附设一个指针top,指向当前栈顶位置。
栈的顺序存储类型描述:
# define MaxSize 50
typedef struct{
ElemType data[MaxSize];
int top;
}SqStack;
- 栈顶指针:
S.top,初始时S.top=-1; - 栈顶元素:
S.data[S.top]; - 进栈操作:栈不满时,栈顶指针加1,再赋值到栈顶元素;
- 出栈操作:栈非空时,先从栈顶元素取值,再将栈顶指针减1;
- 栈空条件:
S.top==-1; - 栈满条件:
S.top == MaxSize -1;
1.2.2 顺序栈的基本运算
初始化:
void InitStack(&S){
S.top = -1;
}
判栈空:
bool StackEmpty(S){
if(S.top == -1)
return true;
else
return false;
}
进栈:
bool Push(&S, x){
if(S.top == MaxSize-1) // 判满
return false;
else
s.top++;
S.data[S.top] = x; // 或 S.data[++S.top] = x;
return true;
}
出栈:
bool Pop(&S, &x){
if(S.top == -1) // 判空
return false;
x = S.data[S.top];
S.top--; // 或 x = S.data[S.top--]
return true;
}
读栈顶元素:
bool GetTop(S, &x){
if(S.top == -1) // 判空
return false;
x = S.data[S.top];
return true;
}
1.2.3 共享栈
利用栈底位置不变的特性,可以让两个顺序栈共享一个一维数组,如下图所示:
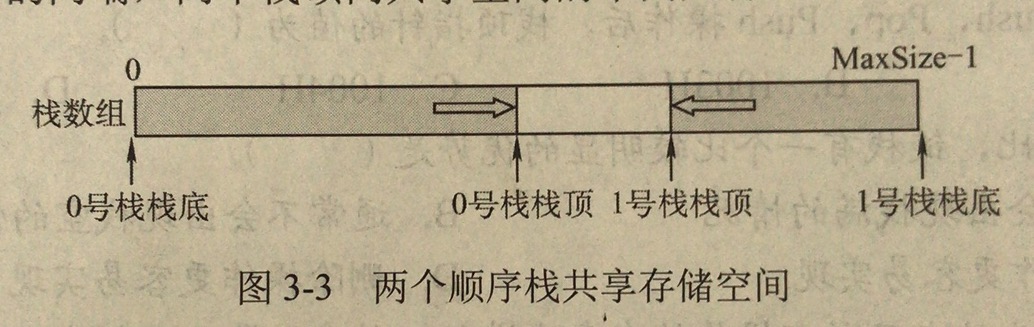
s0.top = -1表示0号栈栈空;s1.top = MaxSize -1表示1号栈栈空;s1.top - s0.top = 1表示栈满;- 0号栈,进栈时,指针先加1,再赋值;出栈时,先赋值,再减1;
- 1号栈,进栈时,指针先减1,再赋值;出栈时,先赋值,再加1;
- 共享栈的目的是为了更有效地利用存储空间;
1.3 栈的链式存储结构
栈的顺序存储称为顺序栈,那么采用链式存储的栈则称为链栈;
优点:便于多个栈共享存储空间和提高效率,不存在栈满溢出的情况;
采用单链表来实现,并规定所有操作再单链表表头进行,没有头结点;Lhead指向栈顶元素;如图所示:

栈的链式存储的类型描述:
typedef struct Linknode{
ElemType data;
struct Linknode *next;
}*LiStack;
2. 队列
2.1 队列的基本概念
2.1.1 队列的定义
队列(Queue):
只允许在表的一端插入,另一端删除;
队头(Front):
允许删除的一端;
队尾(Rear):
允许插入的一端;
空队列:
不含任何元素的空表;
注意:根据队列的定义可以得到,队列是先进先出的线性表;
2.1.2 队列的基本操作
InitQueue(&Q):初始化队列,构造一个空队列Q;
QueueEmpty(Q):判空;
EnQueue(&Q, x):入队操作;先判满,再入队;
DeQueue(&Q, &x):出队操作;先判空,再出队,并用x返回;
GetHead(Q, &x):读队头元素,并用x返回;
2.2 队列的顺序存储结构
2.2.1 队列的顺序存储
队列的顺序实现是指:分配一块连续的存储单元存放队列中的元素;
- 队头指针(front)指向队头元素,队尾指针(rear)指向队尾元素的下一个位置;
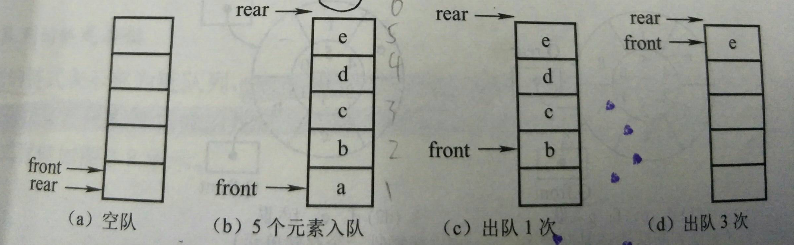
队列的顺序存储类型描述:
#define MaxSize 50
typedef struct{
ElemType data[MaxSize];
int front, rear;
}SqQueue;
- 队空条件:
Q.front == Q.rear == 0; - 进队操作:队不满时,先赋值给队尾元素,再将队尾指针加1;
- 出队操作:队不空时,先取队头元素,再将队头指针加1;
2.2.2 循环队列
上面讲述了队列顺序存储时的判空条件,即Q.front == Q.rear == 0;那么判满条件呢?是Q.rear == MaxSize -1吗?显然不是,假如队头已经有出队的元素,这时候是一种“假溢出”;
为解决上述队列顺序存储的缺点,这里有了一种循环队列,即当队头指针Q.front == MaxSize -1,或队尾指针Q.rear == MaxSize -1时,再前进一个位置时,会自动到0;
- 初始时:
Q.front = Q.rear = 0; - 队头指针进1:
Q.front = (Q.front + 1) % MaxSize; - 队尾指针进1:
Q.rear = (Q.rear + 1) % MaxSize; - 队列长度:
Q.rear + MaxSize - Q.front) % MaxSize;
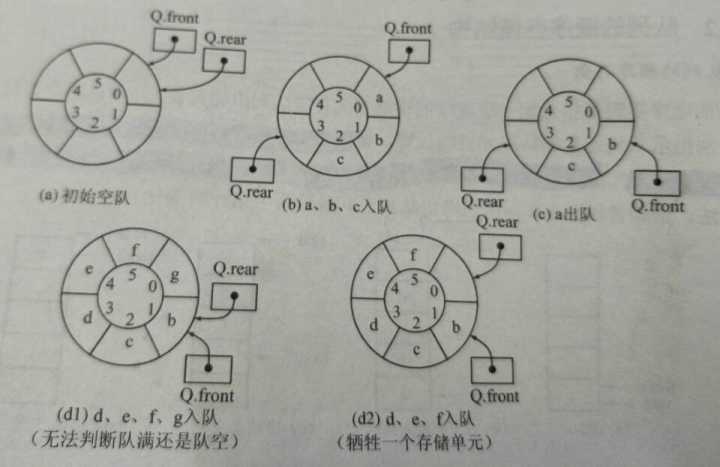
从上图可以看出,初始化时Q.front = Q.rear;当入队操作多于出队操作时,队尾指针很快就能赶上队头指针,当Q.front = Q.rear时(图d1),也代表队满;
那么Q.front = Q.rear即可以表示队空,也可以表示队满?那怎么来区分呢?这里有三种处理方式:
- 牺牲一个单元来区分队空和队满,即“以队头指针在队尾指针的下一个位置为队满的标志”;
- 队满条件:
(Q.rear + 1) % MaxSize = Q.front; - 队空条件:
Q.front == Q.rear; - 队列中元素个数:
Q.rear + MaxSize - Q.front) % MaxSize;
- 队满条件:
- 类型中增设表示元素个数的数据成员
Q.size;- 队满:
Q.size = MaxSize -1; - 队空:
Q.size = 0;
- 队满:
- 类型中增设tag数据成员;
- 若
tag=0,因删除导致Q.front = Q.rear,则表示队空; - 若
tag=1,因插入导致Q.front = Q.rear,则表示队满;
- 若
2.2.3 循环队列的操作
初始化:
void InitQueue(&Q){
Q.rear = Q.front = 0;
}
判队空:
bool IsEmpty(Q){
if(Q.rear == Q.front)
return true;
else
return false;
}
入队:
bool EnQueue(SqQueue &Q, ElemType x){
if((Q.rear + 1) % MaxSize == Q.front) // 判队满
return false;
Q.data[Q.rear] = x; // 队尾元素赋值
Q.rear = (Q.rear + 1) % MaxSize; // 队尾元素加1
return true;
}
出队:
bool DeQueue(SqQueue &Q, ElemType &x){
if (Q.rear == Q.front) // 判队空
return false;
x = Q.data[Q.front]; // 取出队头元素
Q.front = (Q.front + 1) % MaxSize; // 队头指针加1
return true;
}
2.3 队列的链式存储结构
2.3.1 队列的链式存储
队列的链式存储称为链队列;它实际上是一个同时带有队头指针和队尾指针的单链表;
- 头指针指向队头元素;
- 尾指针指向队尾元素(即队列的最后一个结点,注意:和顺序队指向的不一样);
队列的链式存储类型描述:
typedef struct{
ElemType data;
struct LinkNode *next;
}LinkNode;
typedef struct{
LinkNode *front, *rear;
}LinkQueue;
不带头结点的链式队列:
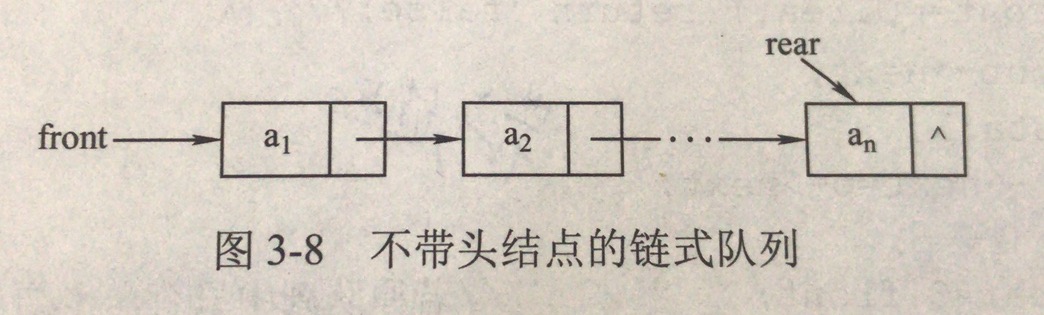
- 当
Q.front == NULL, Q.rear == NULL时,链式队列为空; - 入队,在链表尾部插入结点;
- 出队,取出队头元素,将其从链表中删除;
带头结点的链式队列:
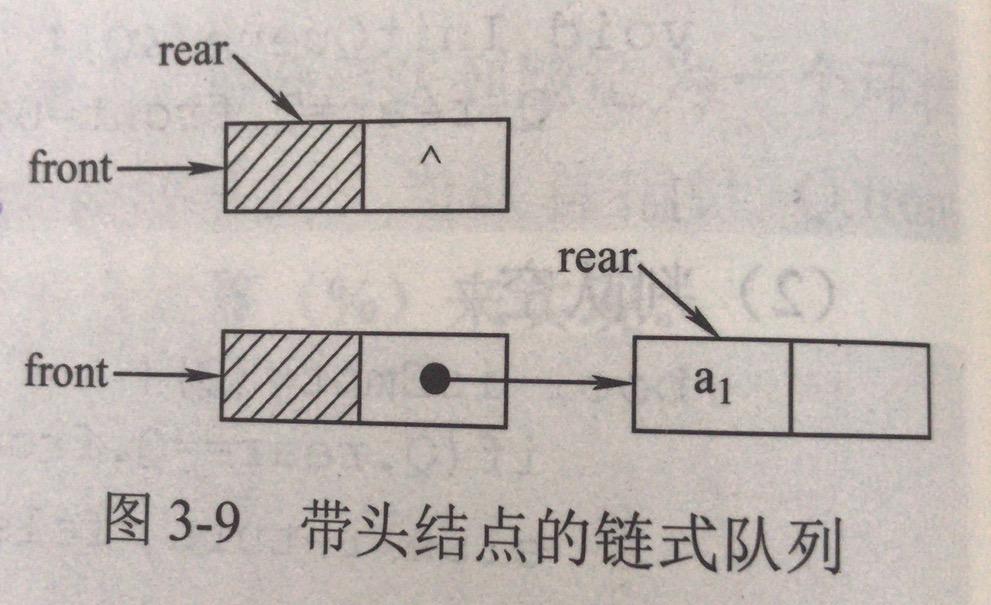
2.3.2 链式队的基本操作
初始化:
void InitQueue(LinkQueue &Q){
Q.front = Q.rear = (LinkNode*)malloc(sizeof(LinkNode)); // 建立头结点
Q.front -> next = NULL; // 初始为空
}
判队空:
bool isEmpty(LinkQueue Q){
if(Q.front == Q.rear)
return true;
else
return false;
}
入队:
void EnQueue(LinkQueue &Q, ElemType x){
s = (LinkNode *)malloc(sizeof(LinkNode)); // 新建结点
s -> data = x; // 对新结点数据域赋值
s -> next = NULL; // 将新结点指针域设空
Q.rear -> next = s; // 链表尾插入
Q.rear = s; // 对尾指针指向队尾元素
}
出队:
void DeQueue(LinkQueue &Q, ElemType &x){
if(Q.front == Q.rear) // 判空
return false;
p = Q.front -> next; // 需要出队的结点
x = p -> data; // 赋值
Q.front -> next = p -> next; // 断开p结点
if(Q.rear == p) // 判断原队列是否只有一个元素
Q.rear = Q.front;
free(p);
return true;
}
2.4 双端队列
双端队列指的是两端都可以执行入队、出队操作;

入队:
- 前端进的元素排列在后端进的元素的前面;
- 后端进的元素排列在前端进的元素的后面;
出队:
- 先出的元素排在后出的元素前面;
2.4.1 输出受限的双端队列
即有一端只允许入队;
2.4.2 输入受限的双端队列
即有一端只允许出队;
3. 栈和队列的应用
3.1 栈在括号匹配中的应用
算法流程:
Step 1:初始化一个空栈,顺序读入括号;
Step 2:若是左括号,则进栈;
Step 3:若是右括号,则取出栈顶元素,判定是否匹配;
- 若匹配,则弹出栈顶元素,继续读取;
- 若不匹配,则退出程序,括号不匹配;
3.2 栈在表达式求值中的应用
在后缀表达式中,已经考虑了运算的优先级,没有括号;可以使用栈来计算;
Step 1:依次读取后缀表达式;
Step 2:若遇到操作数,则将操作进栈;
Step 3:若遇到运算符,则先后弹出两个栈内操作数,进行计算,计算结果,重新进栈;
Step 4:重复上述步骤
将中缀表达式转换称后缀表达式,可以使用栈来转换,需要根据运算符在栈内外的优先级来判断出/入栈操作;
| 操作符 | # | ( | *, / | +, - | ) |
|---|---|---|---|---|---|
| isp(栈内优先级) | 0 | 1 | 5 | 3 | 6 |
| icp(栈外优先级) | 0 | 6 | 4 | 2 | 1 |
Step 1:首先,依次读取中缀表达式;
Step 2:若遇到操作数,则直接输出;
Step 3:若遇到操作符;
- 若该操作符的栈外优先级大于此时栈顶元素的栈内优先级,则将该操作符进栈;
- 若该操作符的栈外优先级小于此时栈顶元素的栈内优先级,则将栈顶元素弹出栈;再继续比较该操作符的栈外优先级与栈顶元素的栈内优先级;
3.3 栈对递归中的应用
在递归的调用过程中,系统为每一层的返回点、局部变量、传入实参等开辟了递归工作栈进行数据存储,递归次数过多,容易造成栈溢出。其效率不高的原因是递归调用的过程中,包含了需要重复的计算;
3.4 队列在层次遍历中的应用
举例如下图:
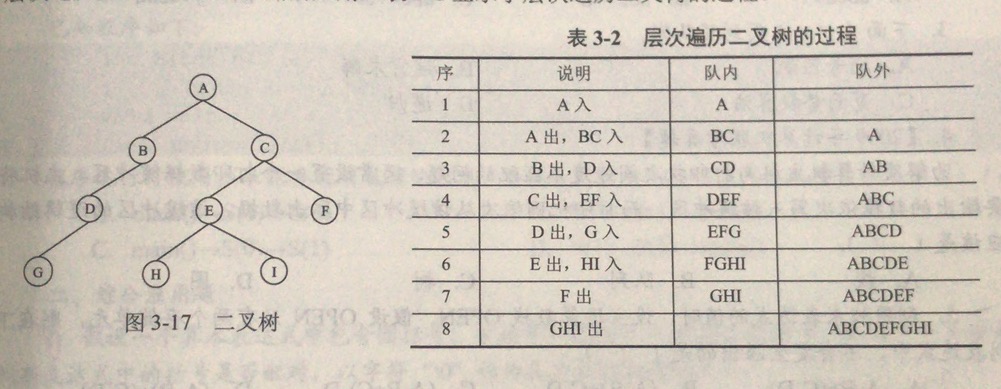
Step 1:根节点入队;
Step 2:若队空,则结束遍历;否则执行Step 3;
Step 3:队列中第一个结点出队,并访问。
- 若其有左孩子,则将左孩子入队;
- 若其有右孩子,则将右孩子入队;
- 返回执行Step 2;
3.5 队列在计算机系统中的应用
- 解决主机与外部设备之间速度不匹配的问题;
- 解决由多用户引起的资源竞争问题;
4. 特殊矩阵的压缩存储
数据结构中考虑矩阵是:如何用最小的内存空间来存储同样的一组数据;
4.1 数组的定义
定义:数组是由n个相同类型的数据元素构成的有序序列,其中每一个数据元素称为一个数组元素;
数组与线性表的关系:
- 数组是线性表的推广;
- 一维数组可以看作是一个线性表;
- 二维数组可以看作是数据元素是线性表的线性表;
注意:数组一旦定义,维数不再改变,只有初始化、销毁、存取元素、修改元素的操作;
4.2 数组的存储结构
一个数组的所有元素在内存中占用一段连续的存储空间;
- 一维数组:顺序存储;
- 多维数组:两种方式:按行优先、按列优先;
4.3 矩阵的压缩存储
压缩存储:
压缩存储是指多个值相同的元素只分配一个存储空间,对零元素不分配存储空间;
特殊矩阵:
指具有许多相同元素或零元素,并且分布有一定规律的矩阵;对称矩阵、上(下)三角矩阵、对角矩阵;
特殊矩阵的压缩存储:
找出特殊矩阵中相同值的分布规律,然后存入到一个存储空间内;
注意:下面几种特殊矩阵的压缩存储,均采用按行优先存储;
4.3.1 对称矩阵
将对称矩阵(A[1cdots n][1cdots n])存储到一维数组(B[n(n+1)/2])中;
上三角矩阵与主对角线上元素(a_{i,j}(i geq j))对应数组的下标位置为:
下三角矩阵与上三角矩阵相反,因此有:
注意:数组下标从0开始;
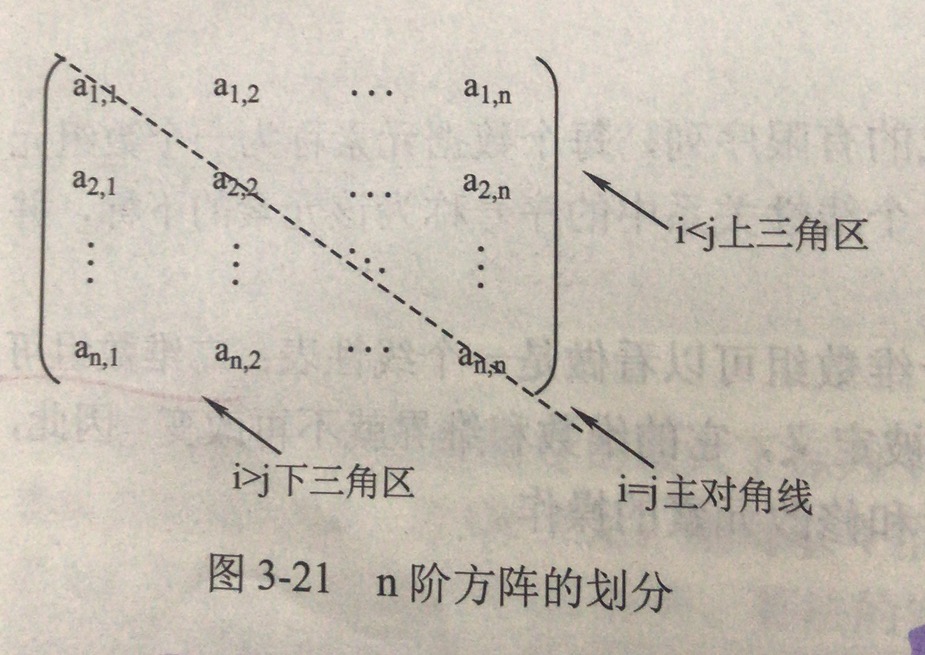
4.3.2 三角矩阵
将上/下三角矩阵(A[1cdots n][1cdots n])存储到一维数组(B[n(n+1)/2+1])中;
下三角矩阵:
- 下三角与主对角线元素(a_{i,j}(i geq j))与对称矩阵的下三角与主对角线元素的下标一致;
- 上三角元素用一个位置,数组下标(dfrac{n(n+1)}{2});
上三角矩阵:
- 上三角矩阵与主对角线上元素(a_{i,j}(i leq j))对应数组的下标:
- 下三角元素占用一个位置,数组下标(dfrac{n(n+1)}{2});
注意:数组下标从0开始;

4.3.3 三对角矩阵
矩阵A中3条对角线元素(a_{i,j}(1 leq i, j leq n, |i-j|leq 1))对应数组中的下标为:

4.4 稀疏矩阵
存储方式,如下图所示,仅仅只记录其非零元素的位置与值;

总结:
该篇博客主要栈、队列、数组矩阵三部分内容;
有关栈,主要介绍了栈的基本概念、栈的基本操作;并根据其两种存储方式,一种是顺序存储,包括顺序栈、顺序栈的基本操作、共享栈;另一种是链式存储,包括链式栈;
有关队列,主要介绍了队列的基本概念、队列的基本操作;并根据其两种存储方式,一种是顺序存储,包括队列的顺序存储、循环队列;另一种是链式存储,包括链队列、链队列的基本操作、双端队列;
第三部分介绍了栈和队列的一些应用,包括:括号匹配、表达式求值、递归、层次遍历、计算机系统;
最后介绍了几种特殊矩阵,以及对应的压缩存储方式;