个人项目报告
源码地址: https://github.com/chenzhik/homework1/tree/master/PB16051320
功能要求
1. 实现要求:
对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2. 代码要求:
风格规范,使用性能测试工具进行分析,找到性能的瓶颈并改进,对代码进行质量分析,消除所有警告。
3. 过程要求:
按照《构建之法》个人软件开发流程(PSP),记录开发日志
需求分析
1. 统计文件的字符数(只需要统计Ascii码,汉字不用考虑,换行符不用考虑,'�'不用考虑)(ascii码大小在[32,126]之间);统计文件的单词总数; 统计文件的总行数(任何字符构成的行,都需要统计)(不要只看换行符的数量,要小心最后一行没有换行符的情形)(空行算一行)。
2. 统计文件中各单词的出现次数,输出频率最高的10个;统计两个单词(词组)在一起的频率,输出频率最高的前10个。
3. 对给定文件夹及其递归子文件夹下的所有文件进行统计。
4. 在Linux系统下,进行代码移植与性能分析 。
设计实现
1. 设计思路
(1) 模块设计(设计文档戳这里)
a. Part 1 — 统计字符、单词、行数可使用全局变量,文件遍历过程中逐个字符读取并判断,再对变量进行自加操作。
b. Part 2 — 单词频数统计,使用HashTable或者map、Hashmap,本鱼比较适应c语言风格所以考虑用哈希表,每个结点内设置计数域和关键字。
c. Part 3 — 词组频数统计与单词同理,哈希表结点内的关键字需要两个,存储相邻两个单词;或者存取单词哈希表两个结点的哈希地址,可能更加高效。
d. Part 4 — 前十频数的单词和词组排序输出,对哈希表进行十次遍历,每次选出频数最大的单词和词组,再对此结点打上已访问标志,总共重复十次。
c. Part 5 — 遍历所有路径文件夹内所有文件,采用_finddata_结构体以及相关函数,先将文件夹内所有文件的路径存入vector<string>内。
(2) 变量类型设计
a. 全局变量累计:使用long int型变量来作为累加器
b. 单词:使用两个string类,分别存储单词缩写和单词尾数,可以使用c++封装好的各种方法,并且节省空间;
2. 代码结构
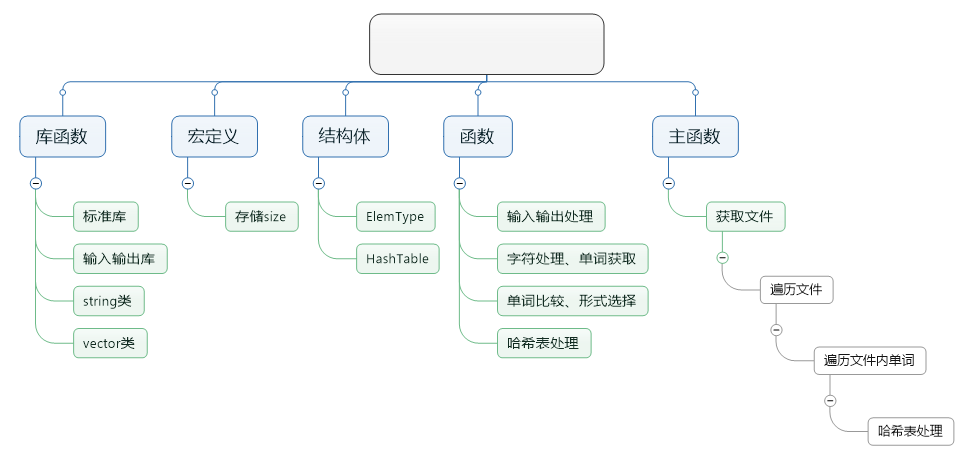
运行测试
1. 空文件,单个词的文件以及单行文件



2. 典型测试集
包括了1323个文件,*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等各种类型

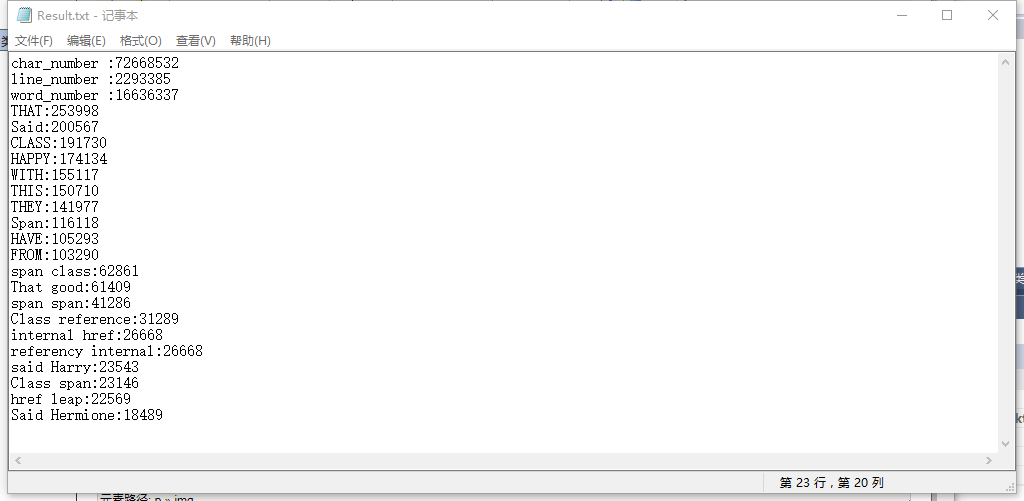
3. 性能分析
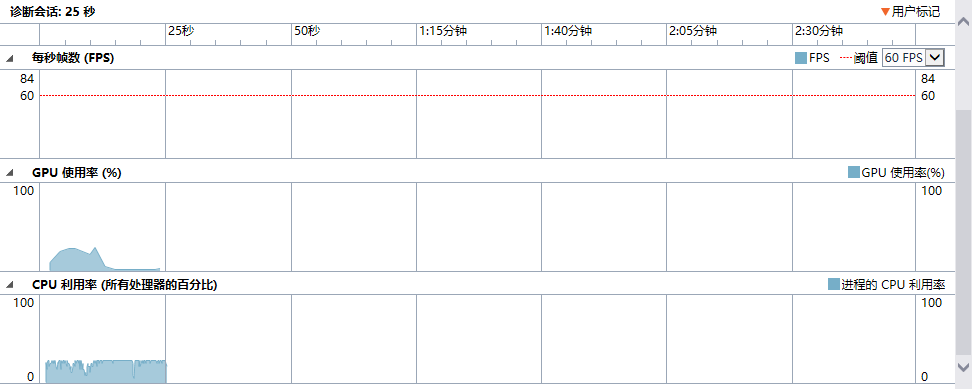
a. 图一:CPU与GPU利用率
可见GPU使用率有一段大幅下降,追踪到测试集中的长篇小说文件中大量出现三个字母组成的单词,可能由于seek1word读取单词算法中对小于四个字母的“单词”处理不高效导致。
b. 图二:性能分析——CPU采样
可见Seek1Word读取一个单词的函数独占百分比最高,热行集中在这个函数模块

c. 图三:内存占有率
可见当文件遍历至1300至1309号文件时内存消耗急剧上升,原因在于这几个文件是长篇英语小说,词组与单词数非常多。

d. 改进方法:
针对这种情况,我对存储单词的数据结构进行了调整,将原本的200个字节大小的字符数组缩短为150个,因效果不明显于是最后改用string存储单词,大大节省了内存空间;针对Seek1Word函数,精简了一些if-else判断语句,并将temp字符串的初始化放在了此函数外。
核心代码
1. 读取一个单词


1 int Seek1Word(FILE* stream, string &temp) 2 { 3 // variables: 4 // 'ch' recieve the character from the file 5 // 'prelength' return the lengh of the word 6 // 'temp' store the word 7 char ch; 8 int prelength; 9 10 // initialize the variables 11 prelength = 0; 12 ch = '�'; 13 InitTemp(temp);//unnecessary for this program 14 15 // find a word from a start of separator 16 ch = ReadNextChar(stream); 17 if (!feof(stream)) 18 { 19 // Judge a word: the first four alphas 20 for (prelength = 0; prelength < 4 && ch != EOF; prelength++) 21 { 22 if (JudgeCharType(ch) == alpha) 23 { 24 temp.push_back(ch); 25 ch = ReadNextChar(stream); 26 } 27 28 //the present ch is not an alpha 29 else 30 { 31 InitTemp(temp); 32 prelength = -1; 33 //return to loop 'for' then 'prelength' will be added 1 34 ch = ReadNextChar(stream); 35 } 36 //end else if 37 } 38 //end 'for' 39 if (prelength == 4) 40 { 41 // seek the next separator to give out the length of this word 42 while (JudgeCharType(ch) == number || isalpha(ch) > 0) 43 { 44 temp.push_back(ch); 45 prelength++; 46 ch = ReadNextChar(stream); 47 } 48 } 49 else if (ch == EOF) 50 { 51 return FileEnd; 52 } 53 WORDS++; 54 return prelength; 55 } 56 else 57 { 58 return FileEnd; 59 } 60 }
2. 哈希散列函数
1 int HashForWord(ElemType e) 2 { 3 // chosen by experience and math axiom 4 int i; 5 int sum; 6 int adder; 7 8 // hashresult and adding factor 9 sum = 0; 10 adder = 0; 11 12 for (i = 0; e.word_prefix[i] != '�'; i++) 13 { 14 // alpha is capital or lower 15 if (e.word_prefix[i] >= 'a' && e.word_prefix[i] <= 'z') 16 { 17 adder = e.word_prefix[i] + 'A' - 'a'; 18 sum = (sum * 31 + adder) % max_hashsize; 19 } 20 else 21 { 22 sum = (sum * 31 + e.word_prefix[i]) % max_hashsize; 23 } 24 } 25 sum = sum % max_hashsize; 26 return sum; 27 }
3. 插入一个单词到哈希表
1 bool InsertHashWord(HashTable &H, ElemType e, Hashptr &p) 2 { 3 // 'H' is hashtable to store word 4 // 'e' is the word to store 5 // 'p' return the the word's location if it exists 6 Hashptr s; 7 8 if (SearchHashWord(H, e, p) == true) 9 { 10 if (Select1WordForm(p->data, e) == former) 11 { 12 // choose the word's form as the dictionary order 13 CopyWord(p->data, e); 14 } 15 p->data_count = p->data_count + 1; 16 return false; 17 } 18 else 19 { 20 s = new HashNode; 21 CopyWord(s->data, e); 22 p->next = s; 23 s->data_count = 1; 24 s->next = NULL; 25 } 26 return true; 27 }
4. 移植前后的文件夹遍历函数
1 void GetAllFiles(string path, vector<string>& files) 2 { 3 long handle = 0; // File Handle 4 struct _finddata_t fileinfo; // File Information 5 string p; 6 char * location; // location converts char * into string 7 8 if ((handle = _findfirst(p.assign(path).append("\*").c_str(), &fileinfo)) != -1) 9 { 10 do 11 { 12 if ((fileinfo.attrib & _A_SUBDIR)) // to check whether it is a folder or a file 13 { 14 if (strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0) 15 { 16 GetAllFiles(p.assign(path).append("\").append(fileinfo.name), files); 17 } 18 } 19 else 20 { 21 files.push_back(p.assign(path).append("\").append(fileinfo.name)); 22 location = (char *)p.data(); 23 } 24 } while (_findnext(handle, &fileinfo) == 0); 25 _findclose(handle); 26 } 27 }
1 void listDir(char *path, vector<string>& files) //main's argv[1] char * 2 { 3 DIR *pDir; 4 struct dirent *ent; 5 int i=0; 6 pDir = opendir(path); //opendir the path 7 while ((ent = readdir(pDir)) != NULL) 8 { 9 10 if (ent->d_type & DT_DIR) 11 { 12 13 if (strcmp(ent->d_name, ".") == 0 || strcmp(ent->d_name, "..") == 0) 14 continue; 15 sprintf(childpath, "%s/%s", path, ent->d_name); 16 listDir(childpath); // recursion in the subfolder 17 } 18 else 19 {//d_type is DT_DIR then it is a path, else store the d_name 20 files.push_back(ent->d_name); 21 } 22 } 23 }
项目展示
1. Teambition管理
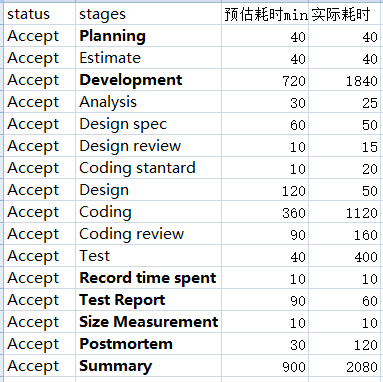
2. PSP表格
项目总结
1. 不足:
a. 开发环境的准备:对Visual Studio的性能分析工具使用不充分,未提前准备好Ubuntu 16.04 g++环境导致未能及时做好代码移植优化。
b. 代码设计:对代码消耗的内存预估不明确,一开始使用字符数组存储单词消耗了大量内存,测试时才只好更改数据类型采用string类。
2. 需要补足:
a. 代码注释:总体代码注释比较好,但随着进程的严重滞后,注释上开始有点草率,最后重新修正又花了大量时间。以后应注意编码时小步快走。
b. 代码优化与代码移植:这一点由于一开始对开发环境准备不充分,没来得及完成,归因于自己平时代码量太少,急需加强。
c. 开发过程遇到问题时的应对:连续高强度开发中遇到突发情况没有及时调整设计与时间安排,导致代码重复更改,效率底下。
3. 继续保持:
a. 代码风格:代码风格比较简明易读,严格遵循了起初设计的代码规范(代码规范文档)。
——此次作业虽然非常不完善,但确实是自己认真做成的(T^T)。在个人的内存消耗上花费了大量的时间,如此严重问题本不应该在一个软件工程中出现,幸亏没有拖延到deadline之前才开始,中途由于PC更新故障还停工一段时间。平时在读软工书时接受到的建议在实际过程中真的非常有价值,果然实践出真知!