MySQL 高可用方案-PXC环境部署记录
之前梳理了Mysql+Keepalived双主热备高可用操作记录,对于mysql高可用方案,经常用到的的主要有下面三种:
一、基于主从复制的高可用方案:双节点主从 + keepalived
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
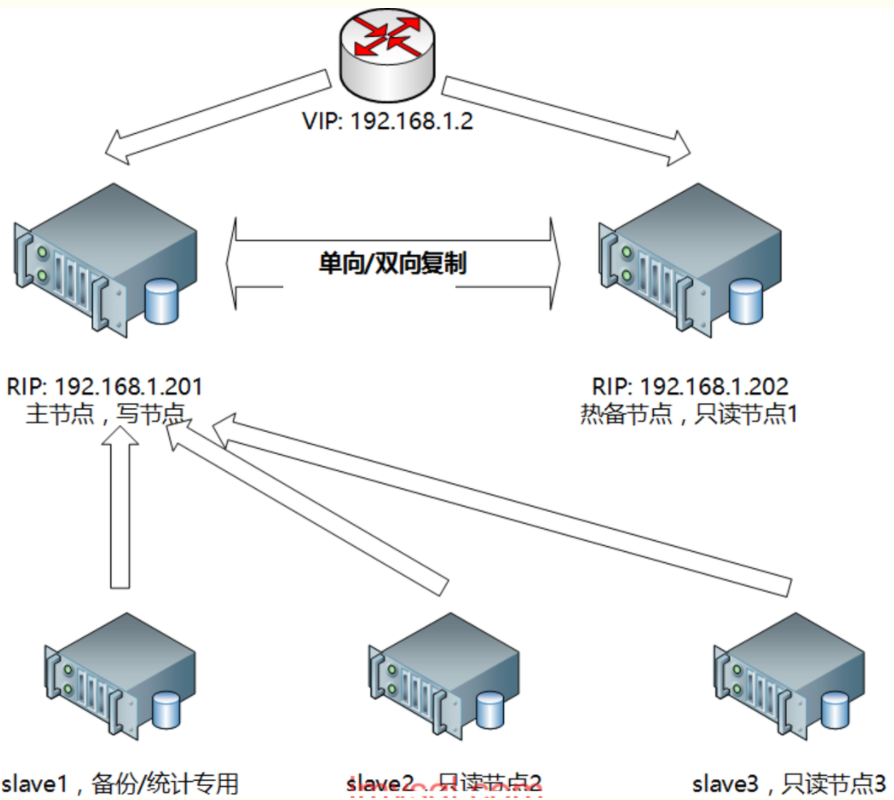
一般来说,中小型规模的时候,采用这种架构是最省事的。两个节点可以采用简单的一主一从模式,或者双主模式,并且放置于同一个VLAN中,在master节点发生故障后,利用keepalived/heartbeat的高可用机制实现快速切换到slave节点。 在这个方案里,有几个需要注意的地方:采用keepalived作为高可用方案时,两个节点最好都设置成BACKUP模式,避免因为意外情况下(比如脑裂)相互抢占导致往两个节点写入相同数据而引发冲突;1)把两个节点的auto_increment_increment(自增步长)和auto_increment_offset(自增起始值)设成不同值。其目的是为了避免master节点意外宕机时,可能会有部分binlog未能及时复制到slave上被应用,从而会导致slave新写入数据的自增值和原先master上冲突了,因此一开始就使其错开;当然了,如果有合适的容错机制能解决主从自增ID冲突的话,也可以不这么做;2)slave节点服务器配置不要太差,否则更容易导致复制延迟。作为热备节点的slave服务器,硬件配置不能低于master节点;3)如果对延迟问题很敏感的话,可考虑使用MariaDB分支版本,或者直接上线MySQL 5.7最新版本,利用多线程复制的方式可以很大程度降低复制延迟;4)对复制延迟特别敏感的另一个备选方案,是采用semi sync replication(就是所谓的半同步复制)或者后面会提到的PXC方案,基本上无延迟,不过事务并发性能会有不小程度的损失,需要综合评估再决定;5)keepalived的检测机制需要适当完善,不能仅仅只是检查mysqld进程是否存活,或者MySQL服务端口是否可通,还应该进一步做数据写入或者运算的探测,判断响应时间,如果超过设定的阈值,就可以启动切换机制;6)keepalived最终确定进行切换时,还需要判断slave的延迟程度。需要事先定好规则,以便决定在延迟情况下,采取直接切换或等待何种策略。直接切换可能因为复制延迟有些数据无法查询到而重复写入;7)keepalived或heartbeat自身都无法解决脑裂的问题,因此在进行服务异常判断时,可以调整判断脚本,通过对第三方节点补充检测来决定是否进行切换,可降低脑裂问题产生的风险。 |
双节点主从+keepalived/heartbeat方案架构示意图见下:
二、基于主从复制的高可用方案:多节点主从+MHA/MMM
|
1
2
3
4
5
6
7
8
9
10
11
12
|
多节点主从,可以采用一主多从,或者双主多从的模式。这种模式下,可以采用MHA或MMM来管理整个集群,目前MHA应用的最多,优先推荐MHA,最新的MHA也已支持MySQL 5.6的GTID模式了,是个好消息。MHA的优势很明显:1)开源,用Perl开发,代码结构清晰,二次开发容易;2)方案成熟,故障切换时,MHA会做到较严格的判断,尽量减少数据丢失,保证数据一致性;3)提供一个通用框架,可根据自己的情况做自定义开发,尤其是判断和切换操作步骤;4)支持binlog server,可提高binlog传送效率,进一步减少数据丢失风险。不过MHA也有些限制:1)需要在各个节点间打通ssh信任,这对某些公司安全制度来说是个挑战,因为如果某个节点被黑客攻破的话,其他节点也会跟着遭殃;2)自带提供的脚本还需要进一步补充完善,当然了,一般的使用还是够用的。 |
三、基于Galera协议的高可用方案:PXC
|
1
2
3
|
Galera是Codership提供的多主数据同步复制机制,可以实现多个节点间的数据同步复制以及读写,并且可保障数据库的服务高可用及数据一致性。基于Galera的高可用方案主要有MariaDB Galera Cluster和Percona XtraDB Cluster(简称PXC),目前PXC用的会比较多一些。mariadb的集群原理跟PXC一样,maridb-cluster其实就是PXC,两者原理是一样的。 |
下面重点介绍下基于PXC的mysql高可用环境部署记录。
1、PXC介绍
|
1
2
3
4
5
6
|
Percona XtraDB Cluster(简称PXC集群)提供了MySQL高可用的一种实现方法。1)集群是有节点组成的,推荐配置至少3个节点,但是也可以运行在2个节点上。2)每个节点都是普通的mysql/percona服务器,可以将现有的数据库服务器组成集群,反之,也可以将集群拆分成单独的服务器。3)每个节点都包含完整的数据副本。PXC集群主要由两部分组成:Percona Server with XtraDB和Write Set Replication patches(使用了Galera library,一个通用的用于事务型应用的同步、多主复制插件)。 |
2、PXC特性
|
1
2
3
4
5
6
|
1)同步复制,事务要么在所有节点提交或不提交。2)多主复制,可以在任意节点进行写操作。3)在从服务器上并行应用事件,真正意义上的并行复制。4)节点自动配置,数据一致性,不再是异步复制。PXC最大的优势:强一致性、无同步延迟 |
3、PXC优缺点
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
PXC的优点1)服务高可用;2)数据同步复制(并发复制),几乎无延迟;3)多个可同时读写节点,可实现写扩展,不过最好事先进行分库分表,让各个节点分别写不同的表或者库,避免让galera解决数据冲突;4)新节点可以自动部署,部署操作简单;5)数据严格一致性,尤其适合电商类应用;6)完全兼容MySQL;虽然PXC有这么多好处,但也有些局限性:1)只支持InnoDB引擎;当前版本(5.6.20)的复制只支持InnoDB引擎,其他存储引擎的更改不复制。然而,DDL(Data Definition Language) 语句在statement级别被复制,并且,对mysql.*表的更改会基于此被复制。例如CREATE USER...语句会被复制,但是 INSERT INTO mysql.user...语句则不会。(也可以通过wsrep_replicate_myisam参数开启myisam引擎的复制,但这是一个实验性的参数)。2)PXC集群一致性控制机制,事有可能被终止,原因如下:集群允许在两个节点上同时执行操作同一行的两个事务,但是只有一个能执行成功,另一个会被终止,集群会给被终止的客户端返回死锁错误(Error: 1213 SQLSTATE: 40001 (ER_LOCK_DEADLOCK)).3)写入效率取决于节点中最弱的一台,因为PXC集群采用的是强一致性原则,一个更改操作在所有节点都成功才算执行成功。4)所有表都要有主键;5)不支持LOCK TABLE等显式锁操作;6)锁冲突、死锁问题相对更多;7)不支持XA;8)集群吞吐量/性能取决于短板;9)新加入节点采用SST时代价高;10)存在写扩大问题;11)如果并发事务量很大的话,建议采用InfiniBand网络,降低网络延迟;事实上,采用PXC的主要目的是解决数据的一致性问题,高可用是顺带实现的。因为PXC存在写扩大以及短板效应,并发效率会有较大损失,类似semi sync replication机制。 |
4、PXC原理描述
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
分布式系统的CAP理论:C:一致性,所有的节点数据一致A:可用性,一个或者多个节点失效,不影响服务请求P:分区容忍性,节点间的连接失效,仍然可以处理请求其实,任何一个分布式系统,需要满足这三个中的两个。PXC会使用大概是4个端口号3306:数据库对外服务的端口号4444:请求SST SST: 指数据一个镜象传输 xtrabackup , rsync ,mysqldump4567: 组成员之间进行沟通的一个端口号4568: 传输IST用的。相对于SST来说的一个增量。一些名词介绍:WS:write set 写数据集IST: Incremental State Transfer 增量同步SST:State Snapshot Transfer 全量同步PXC环境所涉及的端口:#mysql实例端口10Regular MySQL port, default 3306. #pxc cluster相互通讯的端口2)Port for group communication, default 4567. It can be changed by the option: wsrep_provider_options ="gmcast.listen_addr=tcp://0.0.0.0:4010; "#用于SST传送的端口3)Port for State Transfer, default 4444. It can be changed by the option: wsrep_sst_receive_address=10.11.12.205:5555#用于IST传送的端口4)Port for Incremental State Transfer, default port for group communication + 1 (4568). It can be changed by the option: wsrep_provider_options = "ist.recv_addr=10.11.12.206:7777; " |
PXC的架构示意图:
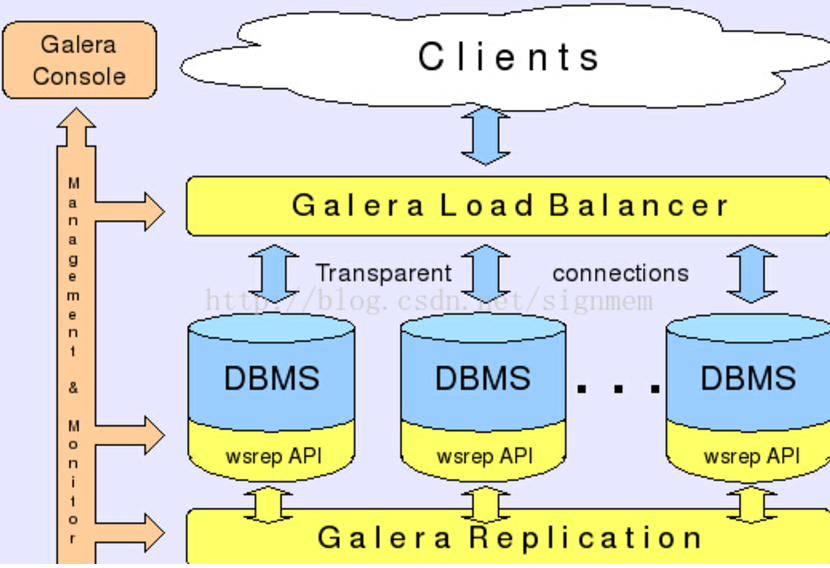
数据读写示意图

---------------------------------------下面看下传统复制流程----------------------------------
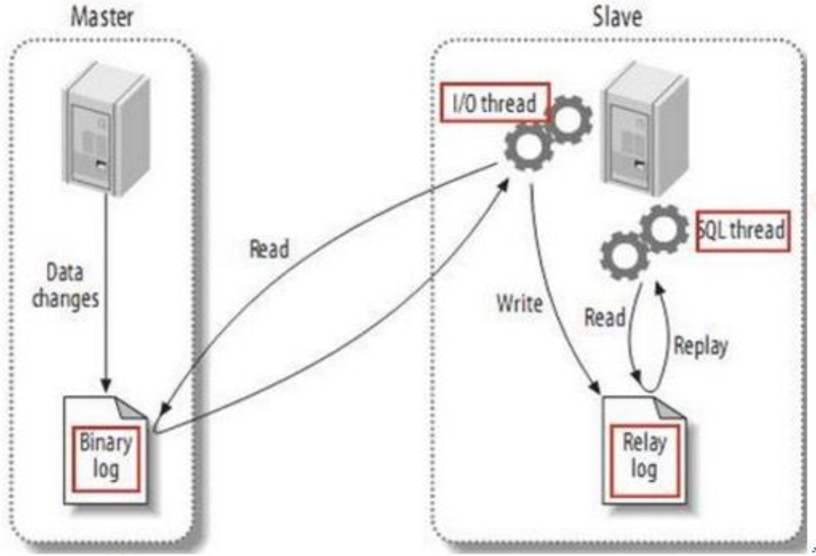
异步复制
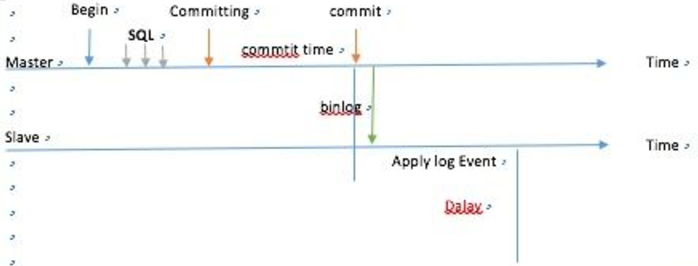
半同步 超过10秒的阀值会退化为异步
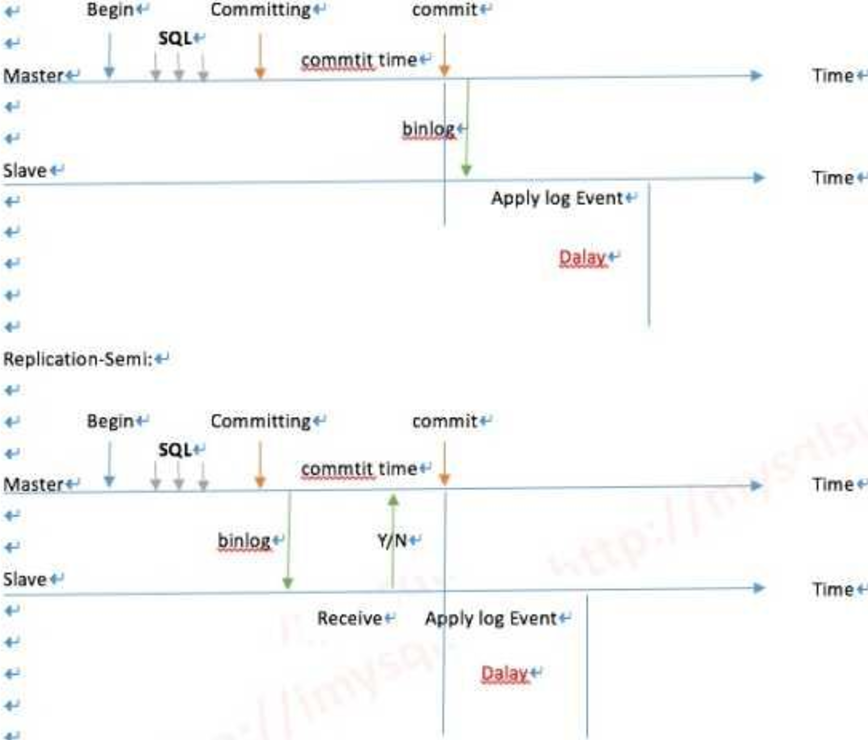
不管同步或是半同步,都存在一定的延迟,那么PXC怎么做到不延迟呢?
PXC最大的优势:强一致性、无同步延迟
每一个节点都可以读写,WriteSet写的集合,用箱子推给Group里所有的成员, data page 相当于物理复制,而不是发日志,就是一个写的结果了。
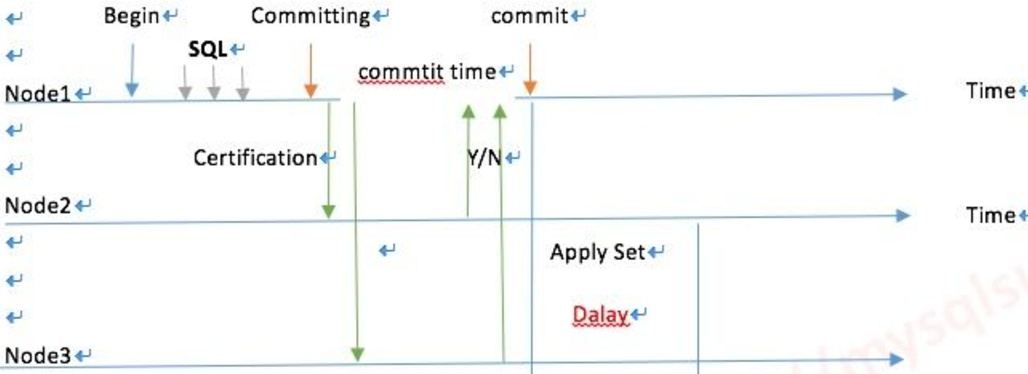

PXC原理图
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
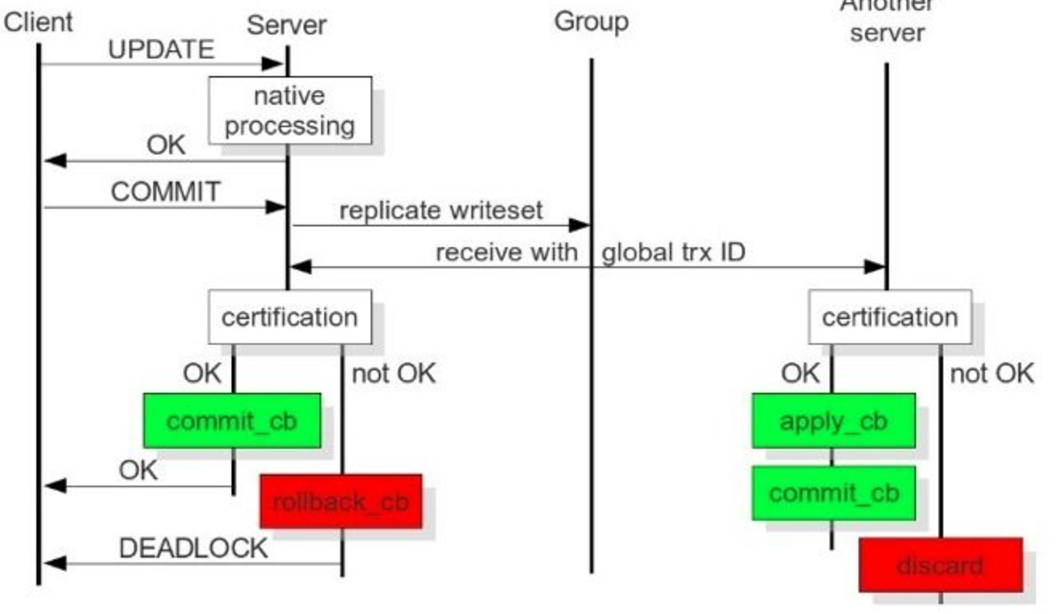
从上图可以看出:当client端执行dml操作时,将操作发给server,server的native进程处理请求,client端执行commit,server将复制写数据集发给group(cluster),cluster中每个动作对应一个GTID,其它server接收到并通过验证(合并数据)后,执行appyl_cb动作和commit_cb动作,若验证没通过,则会退出处理;当前server节点验证通过后,执行commit_cb,并返回,若没通过,执行rollback_cb。只要当前节点执行了commit_cb和其它节点验证通过后就可返回。3306:数据库对外服务的端口号4444:请求SST,在新节点加入时起作用4567:组成员之间沟通的端口4568:传输IST,节点下线,重启加入时起作用SST:全量同步IST:增量同步问题:如果主节点写入过大,apply_cb时间跟不上,怎么处理?Wsrep_slave_threads参数配置成cpu的个数相等或是1.5倍。 |
用户发起Commit,在收到Ok之前,集群每次发起一个动作,都会有一个唯一的编号 ,也就是PXC独有的Global Trx Id。
动作发起者是commit_cb,其它节点多了一个动作: apply_cb
上面的这些动作,是通过那个端号交互的?
4567,4568端口,IST只是在节点下线,重启加入那一个时间有用
4444端口,只会在新节点加入进来时起作用
PXC结构里面,如果主节点写入过大,apply_cb 时间会不会跟不上,那么wsrep_slave_threads参数 解决apply_cb跟不上问题 配置成和CPU的个数相等或是1.5倍
当前节点commit_cb 后就可以返回了,推过去之后,验证通过就行了可以返回客户端了,cb也就是commit block 提交数据块.
5、PXC启动和关闭过程
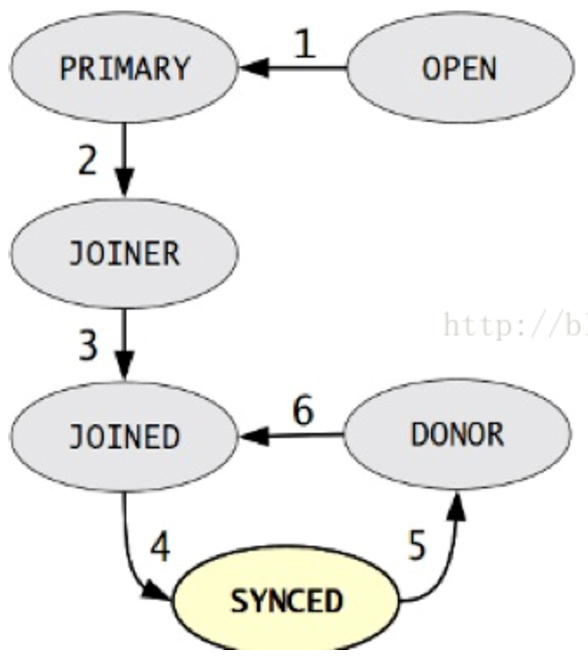
State Snapshot Transfer(SST),每个节点都有一份独立的数据,当用mysql bootstrap-pxc启动第一个节点,在第一个节点上把帐号初始化,其它节点启动后加入进来。集群中有哪些节点是由wsrep_cluster_address = gcomm://xxxx,,xxxx,xxx参数决定。第一个节点把自己备份一下(snapshot)传给加入的新节点,第三个节点的死活是由前两个节点投票决定。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
状态机变化阶段:1)OPEN: 节点启动成功,尝试连接到集群,如果失败则根据配置退出或创建新的集群2)PRIMARY: 节点处于集群PC中,尝试从集群中选取donor进行数据同步3)JOINER: 节点处于等待接收/接收数据文件状态,数据传输完成后在本地加载数据4)JOINED: 节点完成数据同步工作,尝试保持和集群进度一致5)SYNCED:节点正常提供服务:数据的读写,集群数据的同步,新加入节点的sst请求6)DONOR(贡献数据者):节点处于为新节点准备或传输集群全量数据状态,对客户端不可用。状态机变化因素:1)新节点加入集群2)节点故障恢复3)节点同步失效传输SST有几种方法:1)mysqldump2)xtrabackup3)rsync比如有三个节点:node1、node2、node3当node3停机重启后,通过IST来同步增量数据,来完成保证与node1和node2的数据一致,IST的实现是由wsrep_provider_options="gcache.size=1G"参数决定,一般设置为1G大,参数大小是由什么决定的,根据停机时间,若停机一小时,需要确认1小时内产生多大的binlog来算出参数大小。假设这三个节点都关闭了,会发生什么呢?全部传SST,因为gcache数据没了全部关闭需要采用滚动关闭方式:1)关闭node1,修复完后,启动加回来;2)关闭node2,修复完后,启动加回来;3)......,直到最后一个节点4)原则要保持Group里最少一个成员活着 数据库关闭之后,最会保存一个last Txid,所以启动时,先要启动最后一个关闭的节点,启动顺序和关闭顺序刚好相反。wsrep_recover=on参数在启动时加入,用于从log中分析gtid。怎样避免关闭和启动时数据丢失?1)所有的节点中最少有一个在线,进行滚动重启;2)利用主从的概念,把一个从节点转化成PXC里的节点。 |
6、PXC注意的问题
|
1
2
3
4
5
6
7
8
9
10
11
|
1)脑裂:任何命令执行出现unkown command ,表示出现脑裂,集群两节点间4567端口连不通,无法提供对外服务。 SET GLOBAL wsrep_provider_options="pc.ignore_sb=true";2)并发写:三个节点的自增起始值为1、2、3,步长都为3,解决了insert问题,但update同时对一行操作就会有问题,出现: Error: 1213 SQLSTATE: 40001,所以更新和写入在一个节点上操作。3)DDL:引起全局锁,采用:pt-online-schema-change4)MyISAM引擎不能被复制,只支持innodb5)pxc结构里面必须有主键,如果没有主建,有可能会造成集中每个节点的Data page里的数据不一样6)不支持表级锁,不支持lock /unlock tables7)pxc里只能把slow log ,query log 放到File里8)不支持XA事务9)性能由集群中性能最差的节点决定 |
------------------------------------------------------------------------------------------------------------
下面记录在Centos下部署基于PXC的Mysql高可用方案操作过程
官方配置说明:https://www.percona.com/doc/percona-xtradb-cluster/5.5/howtos/centos_howto.html
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
|
1)环境描述(centos6.8版本)node1 10.171.60.171 percona1node2 10.44.183.73 percona2node3 10.51.58.169 percona3 三个节点上的iptables最好关闭(否则就要开放3306、4444、4567、4568端口的访问)、关闭selinux 2)三个node节点都要执行以下操作。可以选择源码或者yum,在此使用yum安装。基础安装[root@percona1 ~]# yum -y groupinstall Base Compatibility libraries Debugging Tools Dial-up Networking suppport Hardware monitoring utilities Performance Tools Development tools 组件安装[root@percona1 ~]# yum install http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm -y[root@percona1 ~]# yum install Percona-XtraDB-Cluster-55 -y 3)数据库配置选择一个node作为名义上的master,下面就以node1为master,只需要修改mysql的配置文件--/etc/my.cnf ----------------以下是在node1节点上的配置----------------------[root@percona1 ~]# cat /etc/my.cnf[mysqld] datadir=/var/lib/mysqluser=mysql # Path to Galera librarywsrep_provider=/usr/lib64/libgalera_smm.so # Cluster connection URL contains the IPs of node#1, node#2 and node#3wsrep_cluster_address=gcomm://10.171.60.171,10.44.183.73,10.51.58.169 # In order for Galera to work correctly binlog format should be ROWbinlog_format=ROW # MyISAM storage engine has only experimental supportdefault_storage_engine=InnoDB # This changes how InnoDB autoincrement locks are managed and is a requirement for Galerainnodb_autoinc_lock_mode=2 # Node #1 addresswsrep_node_address=10.171.60.171 # SST methodwsrep_sst_method=xtrabackup-v2 # Cluster namewsrep_cluster_name=my_centos_cluster # Authentication for SST methodwsrep_sst_auth="sstuser:s3cret" 启动数据库(三个节点都要操作):node1的启动方式:[root@percona1 ~]# /etc/init.d/mysql bootstrap-pxc.....................................................................如果是centos7,则启动命令如下:[root@percona1 ~]# systemctl start mysql@bootstrap.service.....................................................................若是重启的话,就先kill,然后删除pid文件后再执行上面的启动命令。 配置数据库(三个节点都要操作)mysql> show status like 'wsrep%';+----------------------------+--------------------------------------+| Variable_name | Value |+----------------------------+--------------------------------------+.........| wsrep_local_state | 4 || wsrep_local_state_comment | Synced || wsrep_cert_index_size | 0 || wsrep_causal_reads | 0 || wsrep_incoming_addresses | 10.171.60.171:3306 | //集群中目前只有一个成员的ip| wsrep_cluster_conf_id | 1 || wsrep_cluster_size | 1 | //主要看这里,目前node2和node3还没有加入集群,所以集群成员目前只有一个| wsrep_cluster_state_uuid | 5dee8d6d-455f-11e7-afd8-ca25b704d994 || wsrep_cluster_status | Primary || wsrep_connected | ON || wsrep_local_bf_aborts | 0 || wsrep_local_index | 0 || wsrep_provider_name | Galera || wsrep_provider_vendor | Codership Oy <info@codership.com> || wsrep_provider_version | 2.12(r318911d) || wsrep_ready | ON || wsrep_thread_count | 2 |+----------------------------+--------------------------------------+ 数据库用户名密码的设置mysql> UPDATE mysql.user SET password=PASSWORD("Passw0rd") where user='root'; 创建、授权、同步账号mysql> CREATE USER 'sstuser'@'localhost' IDENTIFIED BY 's3cret';mysql> GRANT RELOAD, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'sstuser'@'localhost';mysql> FLUSH PRIVILEGES; ................注意下面几个察看命令...............mysql> SHOW VARIABLES LIKE 'wsrep_cluster_address';#如果配置了指向集群地址,上面那个参数值,应该是你指定集群的IP地址 # 此参数查看是否开启mysql> show status like 'wsrep_ready'; # 查看集群的成员数mysql> show status like 'wsrep_cluster_size'; # 这个查看wsrep的相关参数mysql> show status like 'wsrep%'; 4)那么node2和node3只需要配置my.cnf文件中的wsrep_node_address这个参数,将其修改为自己的ip地址即可。------------------------------------node2节点的/etc/my.cnf配置[root@percona2 ~]# cat /etc/my.cnf[mysqld] datadir=/var/lib/mysqluser=mysql # Path to Galera librarywsrep_provider=/usr/lib64/libgalera_smm.so # Cluster connection URL contains the IPs of node#1, node#2 and node#3wsrep_cluster_address=gcomm://10.171.60.171,10.44.183.73,10.51.58.169 # In order for Galera to work correctly binlog format should be ROWbinlog_format=ROW # MyISAM storage engine has only experimental supportdefault_storage_engine=InnoDB # This changes how InnoDB autoincrement locks are managed and is a requirement for Galerainnodb_autoinc_lock_mode=2 # Node #1 addresswsrep_node_address=10.44.183.73 # SST methodwsrep_sst_method=xtrabackup-v2 # Cluster namewsrep_cluster_name=my_centos_cluster # Authentication for SST methodwsrep_sst_auth="sstuser:s3cret" ----------------------------------node3节点的/etc/my.cnf配置[root@percona3 ~]# cat /etc/my.cnf[mysqld] datadir=/var/lib/mysqluser=mysql # Path to Galera librarywsrep_provider=/usr/lib64/libgalera_smm.so # Cluster connection URL contains the IPs of node#1, node#2 and node#3wsrep_cluster_address=gcomm://10.171.60.171,10.44.183.73,10.51.58.169 # In order for Galera to work correctly binlog format should be ROWbinlog_format=ROW # MyISAM storage engine has only experimental supportdefault_storage_engine=InnoDB # This changes how InnoDB autoincrement locks are managed and is a requirement for Galerainnodb_autoinc_lock_mode=2 # Node #1 addresswsrep_node_address=10.51.58.169 # SST methodwsrep_sst_method=xtrabackup-v2 # Cluster namewsrep_cluster_name=my_centos_cluster # Authentication for SST methodwsrep_sst_auth="sstuser:s3cret" node2和node3的启动方式:[root@percona2 ~]# /etc/init.d/mysql start..................................注意................................-> 除了名义上的master之外,其它的node节点只需要启动mysql即可。-> 节点的数据库的登陆和master节点的用户名密码一致,自动同步。所以其它的节点数据库用户名密码无须重新设置。 也就是说,如上设置,只需要在名义上的master节点(如上的node1)上设置权限,其它的节点配置好/etc/my.cnf后,只需要启动mysql就行,权限会自动同步过来。 如上的node2,node3节点,登陆mysql的权限是和node1一样的(即是用node1设置的权限登陆).....................................................................如果上面的node2、node3启动mysql失败,比如/var/lib/mysql下的err日志报错如下:[ERROR] WSREP: gcs/src/gcs_group.cpp:long int gcs_group_handle_join_msg(gcs_解决办法:-> 查看节点上的iptables防火墙是否关闭;检查到名义上的master节点上的4567端口是否连通(telnet)-> selinux是否关闭-> 删除名义上的master节点上的grastate.dat后,重启名义上的master节点的数据库;当然当前节点上的grastate.dat也删除并重启数据库..................................................................... 5)最后进行测试在任意一个node上,进行添加,删除,修改操作,都会同步到其他的服务器,是现在主主的模式,当然前提是表引擎必须是innodb,因为galera目前只支持innodb的表。mysql> show status like 'wsrep%';........ wsrep_local_state | 4 || wsrep_local_state_comment | Synced || wsrep_cert_index_size | 2 || wsrep_causal_reads | 0 || wsrep_incoming_addresses | 10.44.183.73:3306,10.51.58.169:3306,10.171.60.171:3306 | | wsrep_cluster_conf_id | 9 || wsrep_cluster_size | 3 | //集群成员是3个| wsrep_cluster_state_uuid | 92e43358-456d-11e7-af61-733b6b73c72c || wsrep_cluster_status | Primary || wsrep_connected | ON || wsrep_local_bf_aborts | 0 || wsrep_local_index | 2 || wsrep_provider_name | Galera || wsrep_provider_vendor | Codership Oy <info@codership.com> || wsrep_provider_version | 2.12(r318911d) || wsrep_ready | ON || wsrep_thread_count | 2 在node3上创建一个库mysql> create database wangshibo;Query OK, 1 row affected (0.02 sec)然后在node1和node2上查看,自动同步过来mysql> show databases;+--------------------+| Database |+--------------------+| information_schema || mysql || performance_schema || test || wangshibo |+--------------------+5 rows in set (0.00 sec)在node1上的wangshibo库下创建表,插入数据mysql> use wangshibo;Database changedmysql> create table test( -> id int(5));Query OK, 0 rows affected (0.11 sec)mysql> insert into test values(1);Query OK, 1 row affected (0.01 sec)mysql> insert into test values(2);Query OK, 1 row affected (0.02 sec)同样,在其它的节点上查看,也是能自动同步过来mysql> select * from wangshibo.test;+------+| id |+------+| 1 || 2 |+------+2 rows in set (0.00 sec) |