虽然分区有很多好处(一)SQL Server分区详解Partition,却不能随意使用;且不说分区管理的繁琐,只是跨分区带来的负面影响就需要我们好好分析是否有必要使用分区。一般分区创建的业务特点:用于统计、历史数据少使用、数据自增长、可能数据冗余大、数据量庞大插入量大。在确定是否合适使用分区前,需了解分区是如何创建的,分区的创建包括:
1、新建分区函数:确定分区的方式和界点。
2、新建文件和文件组:用于存放不同分区数据
3、新建分区架构:将分区行数制定的分区映射到文件组。
4、新建分区表或者分区索引
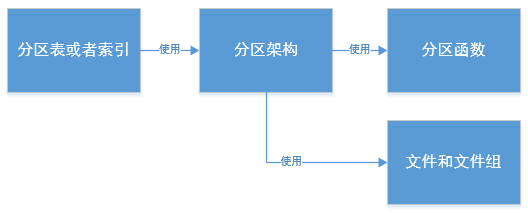
如下图所示:分区函数定义了分区的具体方式,分区架构使用分区函数和文件组,确定分区方案,表或索引就使用分区架构来实现分区。他们之间是使用关系,一对多的关系。
一、创建分区函数
分区函数定义如何根据某些列的值将表或索引的行映射到指定分区。分区函数制定了分区的方式。用作索引列时有效的所有数据类型都可以用作分区依据列,timestamp 除外。无法指定 ntext、text、image、xml、varchar(max)、nvarchar(max) 或 varbinary(max) 数据类型为分区依据列。基本语法如下所示:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type ) AS RANGE [ LEFT | RIGHT ] FOR VALUES ( [ boundary_value [ ,...n ] ] ) [ ; ]
左/右界限RANGE [ LEFT | RIGHT ]
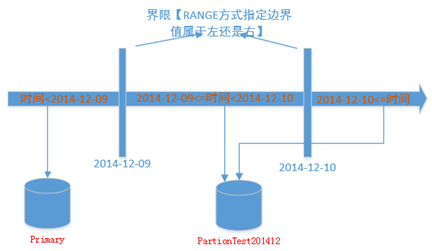
指定左右既是为了确定边界值处于左侧还是右侧。如下图所示RANGE RIGHT,则界限值属于右边。

/*新建分区函数*/
USE [PartionTest];
CREATE PARTITION FUNCTION [pf_PartionTest01] (datetime) AS RANGE right FOR VALUES ('2014-12-09', '2014-12-10'
/*分区函数查询*/
SELECT
pf.name 分区函数名称
,CASE WHEN boundary_value_on_right=1 THEN 'RIGHT' ELSE 'LEFT' END 分区界限方式
,value 分区界限值
FROM sys.partition_functions pf
LEFT JOIN sys.partition_range_values prv ON prv.function_id = pf.function_id
ORDER BY boundary_id
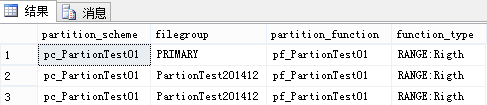
查询结果如下:

注意:
1、业务上多数为使用Range Right ,将边界保留在最新分区,毕竟右为后期增长的数据;比如按每天分区的逻辑是将当天的数据存在当天的分区内,假如当天分区为2014-12-08 00:00.000, Range Right 将2014-12-08 00:00.000的数据归于2014-12-08当天,RANGE LEFT则只能将此界限时间归于2014-12-07。与逻辑存在一定差异。
2、既然有分区界限问题,在合并分区的时候,指定分区是向左还是向右合并?
二、创建分区架构
分区架构把分区函数指定的分区映射到文件组;
CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )[ ; ]
分区指定文件组要比分区划分边界多一个,分区架构指定了具体分区数据存放在哪个文件组上。如下图所示:
在创建分区架构之前若有必要需要创建特定的文件和文件组:
1、新建不同文件组若存放在不同逻辑磁盘可以提高io并发能力;
2、同时不同文件可以提高容灾的能力,在某个文件发生顺坏,其他文件可以继续使用。
3、分开文件存储,也可实现不同分区独立备份,提高了数据恢复速率。
依据已经新建分区函数【pf_PartionTest01】和默认已有文件组,新建以下分区架构:
/*新建分区架构*/
USE [PartionTest];
CREATE PARTITION SCHEME [pc_PartionTest01] AS PARTITION [pf_PartionTest01] TO ('Primary', 'PartionTest201412', 'PartionTest201412')
/*分区架构查询*/
SELECT
ps.name partition_scheme,
ds.name filegroup,
pf.name partition_function,
pf.type_desc+':'+case when pf.boundary_value_on_right=0 then 'Left' else 'Rigth' end function_type
FROM sys.partition_schemes ps
JOIN sys.destination_data_spaces dds ON ps.data_space_id=dds.partition_scheme_id
JOIN sys.data_spaces ds ON dds.data_space_id=ds.data_space_id
JOIN sys.partition_functions pf ON ps.function_id=pf.function_id
结果如下图所示:
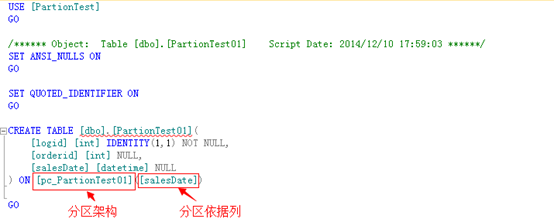
三、创建分区表
如下图所示,只要制定分区架构和分区依据列即可.