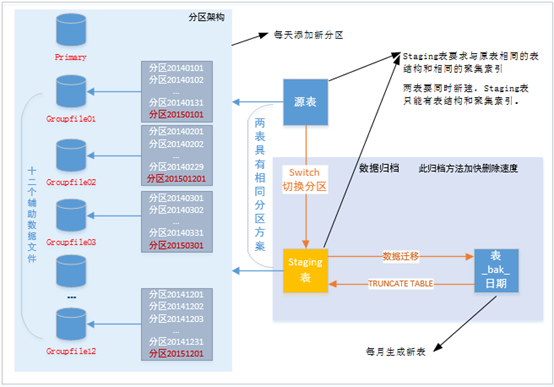
需求定义
统计表可能达到每天1000万数据。只查询当天的数据用于统计,可归档三月前的数据。得出分区方案如下:
- 每天生成一个分区
- 归档三个月前的分区
基本架构
- 固定生成12个辅助数据库文件,将每年当月的分区数据存放到当月的数据文件中。
- 每个源表拥有一个独立的分区方案。且Staging表与源表拥有相同的分区方案。
- 提前自动按天生成新分区。
- 每天迁移历史的分区数据到当月备份表中(备份表按月新建)
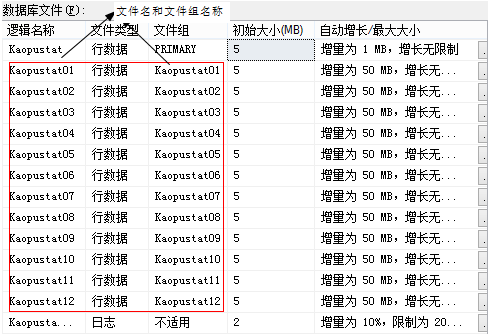
一、添加文件和文件组(固定12个月文件)
该脚本添加12个月的文件和文件组;此步骤在新建数据库的时候同时完成。生成结果如下图所示,文件和文件组名称相同,命名方式按数据库+月份。
USE PartionTest GO SET NOCOUNT ON DECLARE @CMD VARCHAR(MAX) DECLARE @DBName SYSNAME='PartionTest'--数据库名称 DECLARE @FilePath VARCHAR(2000)='E:SqldataSQL2012CHS'--文件存放路径 DECLARE @ERRORMSG VARCHAR(MAX) SET @ERRORMSG='' /*生成文件和文件组脚本*/ DECLARE @i INT=1 SET @CMD='' DECLARE @GROUPNAME SYSNAME WHILE @i< =12 BEGIN SET @GROUPNAME=@DBName+CASE WHEN @i<10 THEN '0'+CAST(@i AS varchar(10)) ELSE CAST(@i AS varchar(10)) END IF NOT EXISTS (SELECT TOP 1 1 FROM sys.filegroups WHERE name =@GROUPNAME) BEGIN SET @CMD=@CMD +CHAR(10)+'ALTER DATABASE ['+@DBName+'] ADD FILEGROUP ['+@GROUPNAME+']' +CHAR(10)+'ALTER DATABASE ['+@DBName+'] ADD FILE ( NAME = N'''+@GROUPNAME+''', FILENAME = N'''+@FilePath+@GROUPNAME+'.ndf'' , SIZE = 5120KB , FILEGROWTH = 51200KB ) TO FILEGROUP ['+@GROUPNAME+']' END ELSE BEGIN SET @ERRORMSG=@ERRORMSG+@GROUPNAME+'已经存在'+CHAR(10) END SET @i=@i+1 END SET @CMD='/*新建文件组和文件*/'+CHAR(10)+'USE [master]'+@CMD PRINT (@CMD)
二、初始化分区(新增表时执行一次)
此脚本生成近30个分区,需要输入数据库名称和表名称,由于归档过程需要切换和合并分区,因此要求每个表拥有独立的分区方案。


--新建分区datetime USE Kaopustat GO SET NOCOUNT ON DECLARE @CMD VARCHAR(MAX) DECLARE @DBName SYSNAME='Kaopustat'--数据库名称 DECLARE @TableName SYSNAME='PartionTest031'--表名称 DECLARE @DATE_CYL INT=1 --间隔天数 DECLARE @ERRORMSG VARCHAR(MAX) SET @ERRORMSG='' /*生成文件和文件组脚本*/ DECLARE @Date_i datetime DECLARE @DatePartitionFunction varchar(max) DECLARE @DatePartitionScheme varchar(max) SET @DatePartitionFunction='' SET @DatePartitionScheme='' SET @Date_i=CONVERT(VARCHAR(24),GETDATE(),23)--从当天开始分区 WHILE @Date_i < DATEADD(D,30*@DATE_CYL,CONVERT(VARCHAR(24),GETDATE(),23)) BEGIN SET @DatePartitionFunction += N', ''' + CONVERT(VARCHAR(10),@Date_i,23) + '''' ;--循环获取日期 SET @DatePartitionScheme += N'''' + @DBName+CASE WHEN CONVERT(VARCHAR(6),DATEPART(MM,DATEADD(D, -@DATE_CYL, @Date_i)))<10 THEN '0'+CAST( CONVERT(VARCHAR(6),DATEPART(MM,DATEADD(D, -@DATE_CYL, @Date_i))) AS varchar(10)) ELSE CAST( CONVERT(VARCHAR(6),DATEPART(MM,DATEADD(D, -@DATE_CYL, @Date_i))) AS varchar(10)) END+ ''', ' SET @Date_i = DATEADD(D, @DATE_CYL, @Date_i); END SET @DatePartitionFunction=STUFF(@DatePartitionFunction,1,2,'') SET @DatePartitionScheme=@DatePartitionScheme+''''+ @DBName+CASE WHEN CONVERT(VARCHAR(6),DATEPART(MM,DATEADD(D, -@DATE_CYL, @Date_i)))<10 THEN '0'+CAST( CONVERT(VARCHAR(6),DATEPART(MM,DATEADD(D, -@DATE_CYL, @Date_i))) AS varchar(10)) ELSE CAST( CONVERT(VARCHAR(6),DATEPART(MM,DATEADD(D, -@DATE_CYL, @Date_i))) AS varchar(10)) END+'''' IF NOT EXISTS(SELECT TOP 1 1 FROM sys.partition_functions WHERE name='pf_'+@TableName) BEGIN SET @CMD='/*新建分区函数*/' +CHAR(10)+'USE ['+@DBName+'];' +CHAR(10)+'CREATE PARTITION FUNCTION [pf_'+@TableName+'] (datetime) AS RANGE RIGHT FOR VALUES ('+@DatePartitionFunction+')'--新建分区函数 PRINT (@CMD) IF NOT EXISTS(SELECT TOP 1 1 FROM sys.partition_schemes WHERE name='pc_'+@TableName) BEGIN SET @CMD='/*新建分区架构*/' +CHAR(10)+'USE ['+@DBName+'];' +CHAR(10)+'CREATE PARTITION SCHEME [pc_'+@TableName+'] AS PARTITION [pf_'+@TableName+'] TO ('+@DatePartitionScheme+')'--新建分区架构 PRINT (@CMD) END ELSE BEGIN SET @ERRORMSG=@ERRORMSG+'pc_'+@TableName+'分区架构已经存在'+CHAR(10) END END ELSE BEGIN SET @ERRORMSG=@ERRORMSG+'pf_'+@TableName+'分区函数已经存在'+CHAR(10) END IF @ERRORMSG<>'' BEGIN ;THROW 50000,@ERRORMSG,1 END
脚本内主要执行:
- 生成分区函数,按天生成,天数可以根据参数调整;分区函数命名:pf_表名
- 生成分区架构,将当月分区指定到当月的文件组内。文件组的指定比分区方式多一个;分区架构命名:pc_表名
三、新建分区表
- 新建分区业务源表,所有索引必须与源表分区对齐。
- 新建分区Staging表,用于存放分区临时数据。此表命名方式:Stagiing_ + 源表名 + _bak。
由于是通过源表切分区到Staging表,切换分区有以下要求:
- 两表必须同时拥有一个分区架构
- 若源表拥有聚集索引,Staging表也需要拥有相同的聚集索引
- Staging表只能拥有表结构和聚集索引。不能拥有如自增长,Check约束,外键,非聚集索引等。
新建完成可通过脚本查询分区新建情况:
SELECT Object_name(p.object_id) AS [object_name], id.name AS index_name, id.type_desc AS index_type, id.is_primary_key, id.is_unique, id.is_disabled, ps.name partition_scheme, ds.name filegroup, pf.name partition_function, pf.type_desc+':'+case when pf.boundary_value_on_right=0 then 'Left' else 'Rigth' end function_type, pf.create_date, pf.modify_date, p.partition_number , Isnull(prv.VALUE,'') AS boundy_value, p.rows FROM sys.indexes id JOIN sys.partition_schemes ps ON ps.data_space_id = id.data_space_id JOIN sys.destination_data_spaces dds ON ps.data_space_id = dds.partition_scheme_id JOIN sys.data_spaces ds ON ds.data_space_id = dds.data_space_id JOIN sys.partitions p ON p.object_id = id.object_id AND p.index_id = id.index_id AND dds.destination_id = p.partition_number JOIN sys.partition_functions pf ON ps.function_id = pf.function_id LEFT JOIN sys.partition_range_values prv ON prv.function_id = pf.function_id AND prv.boundary_id = p.partition_number - pf.boundary_value_on_right WHERE Object_name(id.object_id) = 'staging_PartionTest01_bak' order by id.index_id,p.partition_number
四、每天添加分区(作业)
初始化时已经提前生成30个分区,若分区拆分的时候该分区存在大量数据,将造成4倍的io消耗,因此需要在分区不存在数据的时候及时拆分掉。新建作业调用此存储过程每天执行。
该脚本为存储过程spb_add_date_partition。主要步骤:1、指定下个分区使用的文件组;2、拆分最后一个分区。
/* 每天执行一次,针对数据库 针对datetime类型分区 提前生成后30个分区 EXEC spb_add_date_partition @dbname='PartionTest',@partition_functions='pf_PartionTest01',@partition_schemes='pc_PartionTest01',@DATE_CYL=1 */ CREATE PROC spb_add_date_partition @dbname sysname--数据库名称 ,@partition_functions sysname--分区函数名称 ,@partition_schemes sysname--分区架构名称 ,@DATE_CYL int=1 --分区间隔,默认为1 as DECLARE @CMD VARCHAR(MAX) DECLARE @Date_i datetime --数据库是否存在 IF NOT EXISTS(SELECT TOP 1 1 FROM sys.databases WHERE name=@dbname) BEGIN ;THROW 50000,'数据库不存在',1 END --分区函数不存在 IF NOT EXISTS(SELECT TOP 1 1 FROM sys.partition_functions WHERE name=@partition_functions) BEGIN ;THROW 50000,'分区函数不存在',1 END --分区架构不存在 IF NOT EXISTS(SELECT TOP 1 1 FROM sys.partition_schemes WHERE name=@partition_schemes) BEGIN ;THROW 50000,'分区架构不存在',1 END SELECT @Date_i=DATEADD(D, @DATE_CYL,CONVERT(VARCHAR(24),convert(DATETIME,v.VALUE),23))--从已有最大分区开始分区 FROM sys.partition_functions pf LEFT JOIN sys.partition_range_values v ON pf.function_id = v.function_id WHERE boundary_id IN (SELECT MAX(boundary_id) FROM sys.partition_functions pf LEFT JOIN sys.partition_range_values v ON pf.function_id = v.function_id) AND pf.name=@partition_functions WHILE @Date_i <= DATEADD(D,30*@DATE_CYL,CONVERT(VARCHAR(24),GETDATE(),23))--循环获取日期 BEGIN --确认文件组是否存在 SET @CMD='USE ['+@DBName+']' +CHAR(10)+'ALTER PARTITION SCHEME ['+@partition_schemes+'] NEXT USED ['+@DBName+CASE WHEN CONVERT(VARCHAR(6),DATEPART(MM,@Date_i))<10 THEN '0'+CAST( CONVERT(VARCHAR(6),DATEPART(MM,@Date_i)) AS varchar(10)) ELSE CAST( CONVERT(VARCHAR(6),DATEPART(MM,@Date_i)) AS varchar(10)) END+']' EXEC (@CMD) SET @CMD='USE ['+@DBName+'];' +CHAR(10)+'ALTER PARTITION FUNCTION ['+@partition_functions+']() SPLIT RANGE('''+CONVERT(VARCHAR(10),@Date_i,23)+''')'--一个个添加,直到下月的当天 EXEC (@CMD) SET @Date_i = DATEADD(D, @DATE_CYL, @Date_i); END
五、每天归档三个月前的分区(作业)
由于表数据庞大,需要对源表历史数据做归档处理。数据过大,归档对io的消耗很大,建立高效的归档方案,需要有以下前提是Staging表按要求新建:新建分区表
作业调用归档存储过程spb_witch_partition,每天执行一次。
主要步骤:
- 取需要切出的分区信息
- 循环切出分区到Staging表
- 循环迁移临时表数据到备份表:调用存储过程spb_del_staging_partition
- 合并分区
alter PROC spb_witch_partition @dbname sysname --数据库名称 ,@tablename VARCHAR(128) ,@staging_tablename_bak VARCHAR(128)--要求改表拥有与原表相同架构和聚集索引。 ,@partition_function sysname ,@partition_schemes sysname ,@MTH_I INT=3 as DECLARE @MAXPartition_number INT--分区循环处理 DECLARE @MINPartition_number INT--分区循环处理 DECLARE @CMD VARCHAR(MAX) SET @CMD='' DECLARE @CMD_MERGE VARCHAR(MAX)--合并要单独处理 SET @CMD_MERGE='' /*begin获取所有相关分区信息*/ DECLARE @P_table table(partition_number int,filegroup varchar(128),range_boundary datetime,rows int) ;WITH CTE AS( SELECT DISTINCT p.partition_number, ds2.name as filegroup, convert(datetime,isnull(v.value,'1900-01-01 00:00:00.000')) range_boundary, p.rows as rows FROM sys.indexes i JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id JOIN sys.destination_data_spaces dds ON ps.data_space_id = dds.partition_scheme_id JOIN sys.data_spaces ds2 ON dds.data_space_id = ds2.data_space_id JOIN sys.partitions p ON dds.destination_id = p.partition_number AND p.object_id = i.object_id and p.index_id = i.index_id JOIN sys.partition_functions pf ON ps.function_id = pf.function_id LEFT JOIN sys.Partition_Range_values v ON pf.function_id = v.function_id AND v.boundary_id = p.partition_number - pf.boundary_value_on_right WHERE i.object_id = object_id(@TableName)--当前表 AND pf.name=@partition_function--当前分区函数 AND ps.name=@partition_schemes--当前分区架构 AND pf.boundary_value_on_right=1--RANGE RIGHT ) INSERT INTO @P_table SELECT partition_number ,filegroup ,case when Partition_number=1 then (SELECT top 1 DATEADD(D,-1,range_boundary) FROM CTE where Partition_number=2) else range_boundary end range_boundary ,rows FROM CTE B WHERE NOT EXISTS (SELECT TOP 1 1 FROM CTE WHERE rows=0 AND Partition_number=1 AND Partition_number=B.partition_number)--若第一个分区的数据为0则删除该分区不再处理 /*end获取所有相关分区信息*/ SELECT @MAXPartition_number=MAX(Partition_number),@MINPartition_number=MIN(Partition_number) FROM @P_table WHERE range_boundary<='2015-02-07 00:00:00.000' --CONVERT(VARCHAR(24),DATEADD(MM,-@MTH_I,GETDATE()),23)--筛选当前所需要迁移的分区号 DECLARE @ErrorMsg VARCHAR(MAX) DECLARE @range_boundary DATETIME--分区界限点 DECLARE @filegroup SYSNAME--文件组名称 DECLARE @rows BIGINT --当前行数 --获取当前最大分区和最小分区 WHILE @MINPartition_number<= @MAXPartition_number BEGIN --存在当前分区 IF EXISTS(SELECT TOP 1 1 FROM @P_table WHERE Partition_number=@MINPartition_number) BEGIN --获取分区时间和文件组 SELECT @range_boundary=range_boundary,@filegroup=filegroup,@rows=rows FROM @P_table WHERE Partition_number=@MINPartition_number IF @rows<>0--只有在没有数据情况下,才需要切出 BEGIN --拼写备份表名称 BEGIN TRY --切出分区 SET @CMD='ALTER TABLE ['+@DBName+'].[dbo].['+@TableName+'] SWITCH PARTITION '+CONVERT(VARCHAR(30),@MINPartition_number)+' TO ['+@DBName+'].[dbo].['+@staging_tablename_bak+'] PARTITION '+CONVERT(VARCHAR(30),@MINPartition_number) exec (@CMD) END TRY BEGIN CATCH SET @ErrorMsg='切出分区'+CAST(@MINPartition_number AS varchar(20))+'失败:'+ERROR_MESSAGE() ;THROW 50000,@ErrorMsg,1 END CATCH --迁移备份表数据 EXECUTE [dbo].[spb_del_staging_partition] @dbname=@dbname ,@tablename=@tablename ,@staging_tablename_bak=@staging_tablename_bak ,@range_boundary=@range_boundary ,@rows=@rows END --合并分区脚本收集,若直接合并将影响后续迁移。 IF @MINPartition_number>1 --RANGE RIGHT 第一个分区不能合并 BEGIN SET @CMD_MERGE=@CMD_MERGE+CHAR(10)+'ALTER PARTITION FUNCTION '+@partition_function+'() MERGE RANGE ('''+CONVERT(VARCHAR(30),@range_boundary,120)+''')' END END SET @MINPartition_number=@MINPartition_number+1 END BEGIN TRY exec (@CMD_MERGE) END TRY BEGIN CATCH SET @ErrorMsg='合并分区失败:'+ERROR_MESSAGE() ;THROW 50000,@ErrorMsg,1 END CATCH
/* 1、要求将备份数据库设置为最大容量恢复模式 2、要求备份表与原表有相同的分区 3、每月生成一个备份表 EXEC spb_del_staging_partition @dbname ='PartionTest' --数据库名称 ,@tablename ='PartionTest01'--原表名称 ,@staging_tablename ='staging_PartionTest01_20141211'--切出的分区表名称 ,@rows =2000--切出的分区行数 */ alter PROC spb_del_staging_partition @dbname VARCHAR(128) --数据库名称 ,@tablename VARCHAR(128) ,@staging_tablename_bak VARCHAR(128) ,@range_boundary datetime ,@rows BIGINT as DECLARE @tablenameBAK VARCHAR(128) DECLARE @dbnameBAK VARCHAR(128) DECLARE @ERRORMSG VARCHAR(MAX) DECLARE @CMD VARCHAR(MAX) DECLARE @ROWcount BIGINT SET @tablenameBAK=@tablename+'_'+CONVERT(varchar(6),@range_boundary,112) SET @dbnameBAK=@dbname+'bak' DECLARE @CREATETABLE TABLE (Columnid INT ,Columnname VARCHAR(128),ColumnType VARCHAR(128),is_nullable BIT) --若备份表不存在,则新建备份表(只获取表结构) IF OBJECT_ID(''+@dbnameBAK+'.dbo.'+@tablenameBAK+'') IS NULL BEGIN SET @CMD=' use ['+@dbname+'] SELECT ''Columnid'' = c.column_id , ''Columnname'' = c.name COLLATE Chinese_PRC_CI_AS, ''ColumnType'' = CASE WHEN t.system_type_id IN (175,167) THEN t.name + ''('' + CASE WHEN c.max_length = -1 THEN ''max'' ELSE CAST(c.max_length AS VARCHAR(10)) END + '')'' COLLATE Chinese_PRC_CI_AS WHEN t.system_type_id IN (231,239) THEN t.name + ''('' + CASE WHEN c.max_length = -1 THEN ''max'' ELSE CAST(c.max_length / 2 AS VARCHAR(10)) END + '')'' COLLATE Chinese_PRC_CI_AS WHEN t.system_type_id IN (106,108) THEN t.name + ''('' + CAST(Columnproperty(o.object_id,c.name,''PRECISION'') AS VARCHAR(10)) + '','' + CAST(Columnproperty(o.object_id,c.name,''Scale'') AS VARCHAR(10)) + '')'' COLLATE Chinese_PRC_CI_AS ELSE t.name COLLATE Chinese_PRC_CI_AS END, ''is_nullable'' = c.is_nullable FROM ['+@dbname+'].sys.objects o JOIN ['+@dbname+'].sys.columns c ON o.object_id = c.object_id JOIN ['+@dbname+'].sys.types t ON c.user_type_id = t.user_type_id WHERE o.TYPE = ''U'' And o.name = '''+@tablename+'''' INSERT INTO @CREATETABLE EXEC (@CMD) IF NOT EXISTS(SELECT TOP 1 1 FROM @CREATETABLE) BEGIN ;THROW 50000,'该表不存在',1 END SET @CMD='' SELECT @CMD=@CMD+',['+Columnname+'] ['+ColumnType+'] '+CASE WHEN is_nullable=1 THEN 'NULL' WHEN is_nullable=0 THEN 'NOT NULL' ELSE '' END+CHAR(10) FROM @CREATETABLE ORDER BY Columnid SET @CMD='CREATE TABLE ['+@dbnameBAK+'].[dbo].['+@tablenameBAK+']('+CHAR(10)+stuff(@CMD,1,1,'')+')' EXEC (@CMD) END --导入备份数据 SET @CMD='INSERT INTO '+@dbnameBAK+'.dbo.'+@tablenameBAK +CHAR(10)+'SELECT * FROM '+@dbname+'.dbo.'+@staging_tablename_bak BEGIN TRY --执行导入 EXEC (@CMD) --记录导入行数 SET @ROWcount=@@ROWCOUNT END TRY BEGIN CATCH SET @ERRORMSG=@dbname+'.dbo.'+@staging_tablename_bak+'导入备份表失败:'+ERROR_MESSAGE() IF @@TRANCOUNT >0 BEGIN ROLLBACK END ;THROW 50000,@ERRORMSG,1 END CATCH --删除切出的备份表 IF @ROWcount<>@rows BEGIN SET @ERRORMSG=@dbname+'.dbo.'+@staging_tablename_bak+'导入备份表的数据行:'+cast(@ROWcount as varchar(20)) +';实际要求行数:'+cast(@rows as varchar(20)) ;THROW 50000,@ERRORMSG,1 END ELSE BEGIN SET @CMD='TRUNCATE TABLE '+@dbname+'.dbo.'+@staging_tablename_bak EXEC(@CMD) END RETURN 0 GO
六、每天归档三个月前的分区(作业)
- 固定12个月的文件和文件组。将每年当月的数据存放到当月文件内。
- 提前添加30分区,避免拆分分区造成大量io消耗。
- Staging表要求与源表相同分区方式。Staging表只能有表结构和聚集索引。
- 备份库建议调整为大容量日志恢复模式。备份表按月重新生成。
- 由于RANGE RIGHT 的日期模式,01分区不用合并。
- 此架构只适合RANGE RIGHT 的日期模式增长模式。