一、爬虫介绍
1、概念:爬虫就是模拟客户端发送网络请求,获取请求响应数据,一种按照一定的规则,自动地抓取互联网信息的程序。只要是浏览器能做的事情,原则上爬虫都能够做。
2、使用场景:主要用途是数据采集,爬虫是一种获取数据的重要手段。获取到数据后的用途主要有两个方面:进行数据分析或直接展示(比如百度新闻,就是从其他网站采集数据,然后展示)。
二、爬虫的分类
按照爬取范围分为两类:
- 通用爬虫:它将爬取对象从一些种子URL扩充到整个Web上的网站,主要用途是为门户站点搜索引擎和大型Web服务提供商采集数据。这类爬虫爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,但需要较长时间才能刷新一次页面。
- 聚焦爬虫:选择性地爬取那些与预先定义好的主题相关的页面。与通用爬虫不同的是,聚焦爬虫只需要爬行与主题相关的页面,从而极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好的满足一些特定人群对特定领域信息的需求。
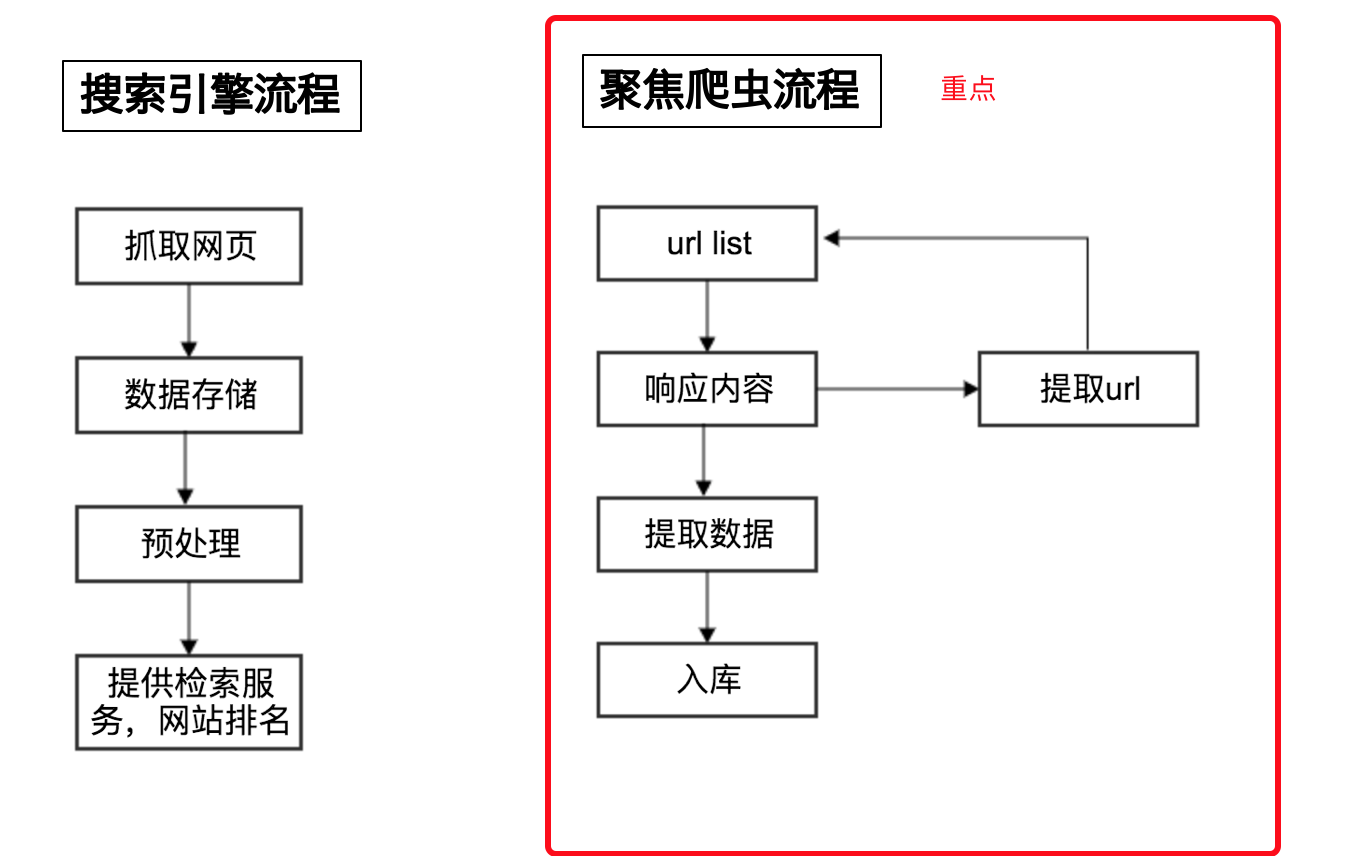
三、爬虫的工作流程
1、搜索引擎流程(通用爬虫):
- 爬取范围:整个网络,见到URL就爬
- 保存数据:保存的是原始的HTML
- 预处理:主要是分词,排名
2、聚焦爬虫流程:
- 爬取范围:特定的URL,只有有需要的数据的URL才爬取。
- 保存的数据:保存的是需要的数据。
3、Robots协议
全称是网络爬虫排除标准,网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,是一个道德层面的约定,爬虫开发者尊不遵守完全看自己意愿。
通常该协议文件会放置在网站的根目录下,比如淘宝网站的Robots文件在:https://www.taobao.com/robots.txt