重来重来,刚刚就当什么都没发生
今天的题属实有些迷惑,各种意义上…总之都很有难度吧。不满归不满,这套题的确不是什么没有意义的题目。
为了考验自己的学习能力记忆力,决定不写题解,扔个代码完事了
其实是懒得写一大堆式子的推理以及想表示一下对出题人的敬意
你就不怕你到时候回来看一脸懵逼吗
T1:


#include<iostream> #include<cstdio> using namespace std; int t,mod=998244353,mod1=998244351; long long n; int main() { scanf("%d",&t); long long num=1,x=9; while(mod1){ if(mod1&1)num=num*x%mod; x=x*x%mod; mod1>>=1; } while(t--){ scanf("%lld",&n); n%=mod; printf("%lld ",(n*n%mod-1)*num%mod); } return 0; }
T2:
这题考场上出70分思路挺快的,大概20min或者更少,连带读完三道题的时间…这个思路本质上也是推导正解的中间过程
#include<iostream> #include<cstdio> #include<cstring> using namespace std; const int N=1e5+10; int n,len,nxt[4*N],lons; long long ans,num1[4*N],num2[4*N]; char s[2*N],c[2*N],a[4*N],ss[4*N]; void kmp1(int lon){ strcpy(a+lon+2,s+1); a[lon+1]='.'; int lens=strlen(a+1); for(int i=2;i<=lens;i++)nxt[i]=0; for(int i=2;i<=lens;i++){ int j=nxt[i-1]; while(j&&a[j+1]!=a[i])j=nxt[j]; if(a[j+1]==a[i])nxt[i]=j+1; if(nxt[i]==lon)num1[i-2*lon]++; } } void kmp2(int lon){ strcpy(a+lon+2,s+1); a[lon+1]='.'; int lens=strlen(a+1); for(int i=2;i<=lens;i++)nxt[i]=0; for(int i=2;i<=lens;i++){ int j=nxt[i-1]; while(j&&a[j+1]!=a[i])j=nxt[j]; if(a[j+1]==a[i])nxt[i]=j+1; if(nxt[i]==lon)num2[i-lon-1]++; } } int main() { scanf("%s",s+1); lons=strlen(s+1); scanf("%d",&n); for(int i=1;i<=n;i++){ scanf("%s",c+1); len=strlen(c+1); for(int j=1;j<=len;j++){ strcpy(a+1,c+1); strcpy(a+j+1,ss+1); kmp1(j); strcpy(a+1,c+j); strcpy(a+len-j+2,ss+1); kmp2(len-j+1); } } for(int i=2;i<=lons;i++){ ans+=num1[i]*num2[i-1]; } printf("%lld ",ans); return 0; }
这个70分的做法是,读入一个字符串以后,暴力地扫出它的所有前后缀,对每一个前后缀在s串上跑一下kmp。如果是后缀,就在s串匹配成功的位置让计数器cnt2++。如果是前缀,就在s串匹配成功的子串的开始位置让计数器cnt1++。
最后扫一遍计数器数组(到s串的长度),ans+=cnt2i*cnt1i+1。
应该是正解里最基础的那部分吧。
能想到正解的一部分对于一个菜鸡来说太不容易了赶紧详细写一下【?】
#include<iostream> #include<cstdio> #include<cstring> using namespace std; const int N=1e5+10,p=1500007,mod=998244353; int n,len,cnt1=1,cnt2=1,lens; char s[2*N],c[2*N]; int tree1[2*N][27],tree2[2*N][27]; unsigned long long hash1[2*N],hash2[2*N],ks[2*N]; long long ans; struct node{ int m; #define m 1500007 int head[2][m+10],Next[2][2*N],tot[2]; long long siz[2][2*N]; unsigned long long ver[2][2*N]; void ins(unsigned long long has,int opt,long long sum){ unsigned long long x=has%m; for(int i=head[opt][x];i;i=Next[opt][i]){ if(has==ver[opt][i]){ siz[opt][i]+=sum; return; } } ver[opt][++tot[opt]]=has,siz[opt][tot[opt]]=sum,Next[opt][tot[opt]]=head[opt][x],head[opt][x]=tot[opt]; return; } long long get(unsigned long long has,int opt){ unsigned long long x=has%m; for(int i=head[opt][x];i;i=Next[opt][i]){ if(has==ver[opt][i]){ return siz[opt][i]; } } return 0; } }h; void insert(){ int now=1; unsigned long long has=0; for(int i=1;i<=len;i++){//前缀 has=has*p+c[i]; if(!tree1[now][c[i]-'a'])tree1[now][c[i]-'a']=++cnt1; h.ins(has,0,1); now=tree1[now][c[i]-'a']; } now=1,has=0; for(int i=len;i>=1;i--){//后缀 has=has*p+c[i]; if(!tree2[now][c[i]-'a'])tree2[now][c[i]-'a']=++cnt2; h.ins(has,1,1); now=tree2[now][c[i]-'a']; } } void dfs1(int now,unsigned long long has){ for(int i=0;i<26;i++){ if(tree1[now][i]){ long long val=has*p+i+'a'; long long sum=h.get(has,0); h.ins(val,0,sum); dfs1(tree1[now][i],val); } } } void dfs2(int now,unsigned long long has){ for(int i=0;i<26;i++){ if(tree2[now][i]){ long long val=has*p+i+'a'; long long sum=h.get(has,1); h.ins(val,1,sum); dfs2(tree2[now][i],val); } } } long long work(int x){ int l=1,r=x,ans1=0,ans2=0; while(l<=r){//后缀 int mid=(l+r)/2; unsigned long long val=hash2[mid]-hash2[x+1]*ks[x-mid+1]; long long sum=h.get(val,1); if(sum){ ans2=sum; r=mid-1; } else l=mid+1; } l=x+1,r=lens; while(l<=r){//后缀 int mid=(l+r)/2; unsigned long long val=hash1[mid]-hash1[x]*ks[mid-x]; long long sum=h.get(val,0); if(sum){ ans1=sum; l=mid+1; } else r=mid-1; } return 1ll*ans1*ans2; } int main() { scanf("%s",s+1); lens=strlen(s+1); ks[0]=1; for(int i=1;i<=lens;i++){ hash1[i]=hash1[i-1]*p+s[i]; ks[i]=ks[i-1]*p; } for(int i=lens;i>=1;i--){ hash2[i]=hash2[i+1]*p+s[i]; } scanf("%d",&n); for(int i=1;i<=n;i++){ scanf("%s",c+1); len=strlen(c+1); insert(); } dfs1(1,0); dfs2(1,0); for(int i=1;i<lens;i++){ ans+=work(i); } printf("%lld ",ans); return 0; }
很神奇的思路转化:让一个中间点前面衔接的最长后缀代表所有更靠近中间点的后缀,记录一个前缀和。因为不用考虑每个前后缀具体的位置,只要存在包含它的更长前后缀就一定能同时对答案产生贡献,所以可以利用trie树来统计一下前缀和。就trie树的操作过程来说,的确非常适合统计数量的前缀和信息。用hash映射所有存在的前后缀,在每个中间点记录答案的时候二分这个最长前后缀。相当于用hash和trie树替代掉了原本一次次跑kmp匹配的过程,非常优秀。
关于我为什么这么生气的原因,这题在hash上搞幺蛾子?嗯?
大概率是我菜吧
记一下要点:巩固一下ull自然溢出,以及哈希表
哈希表本质是利用关键字的分类(散列函数映射)来加速查询
T3:
#include<iostream> #include<cstdio> #define ll long long using namespace std; const int mod=3e5+7; int t; ll n,m,k,ans,rec[mod+10],inv[mod+10],minn; ll ksm(ll x,int k){ ll num=1; while(k){ if(k&1)num=num*x%mod; x=x*x%mod; k>>=1; } return num; } void work(){ inv[0]=rec[0]=rec[1]=1; for(int i=2;i<=mod-1;i++)rec[i]=rec[i-1]*i%mod; inv[mod-1]=ksm(rec[mod-1],mod-2); for(int i=mod-2;i>=1;i--)inv[i]=inv[i+1]*(i+1)%mod; } ll cal(ll x,ll y){ if(x<y)return 0; if(!y||!x)return 1; return rec[x]*inv[y]%mod*inv[x-y]%mod; } ll C(ll x,ll y){ if(x<y)return 0; if(!y)return 1; return C(x/mod,y/mod)*cal(x%mod,y%mod)%mod; } int main() { scanf("%d",&t); work(); while(t--){ scanf("%lld%lld%lld",&n,&m,&k); if(k==1){ n%=mod,m%=mod; printf("%lld ",n*m%mod); continue; } minn=min(n,m); ans=0; if(n>m)swap(n,m); ans=(ans+n%mod*C(m,k)%mod+m%mod*C(n,k))%mod; ans=(ans+2*(2*C(n,k+1)%mod+(m-n+1)%mod*C(n,k))%mod)%mod; if(k==5){ minn%=mod; long long n1=n,m1=m; n%=mod,m%=mod; minn=((min(n1,m1)-1)/2)%mod; ans=(ans+2*(minn*n%mod*m%mod-2*(1+minn)%mod*minn%mod*inv[2]%mod*(m+n)%mod+4*minn%mod*(minn+1)%mod*(2*minn+1)%mod*ksm(6,mod-2)%mod+mod)%mod)%mod; } else if(k==4){ minn%=mod; long long n1=n,m1=m; n%=mod,m%=mod; ans=(ans+(minn*n%mod*m%mod-(1+minn)*minn%mod*inv[2]%mod*(m+n)%mod+minn*(minn+1)%mod*(2*minn+1)%mod*ksm(6,mod-2)%mod+mod)%mod)%mod; minn=min(m1/2,n1)%mod; ans=(ans+2*(minn*n%mod*m%mod-(1+minn)*minn%mod*inv[2]%mod*(m+2*n)%mod+2*minn%mod*(minn+1)%mod*(2*minn+1)%mod*ksm(6,mod-2)%mod+mod)%mod)%mod; swap(n1,m1); swap(n,m); minn=min(m1/2,n1)%mod; ans=(ans+2*(minn*n%mod*m%mod-(1+minn)*minn%mod*inv[2]%mod*(m+2*n)%mod+2*minn%mod*(minn+1)%mod*(2*minn+1)%mod*ksm(6,mod-2)%mod+mod)%mod)%mod; minn=((min(n1,m1)-1)/2)%mod; ans=(ans+5*(minn*n%mod*m%mod-2*(1+minn)%mod*minn%mod*inv[2]%mod*(m+n)%mod+4*minn%mod*(minn+1)%mod*(2*minn+1)%mod*ksm(6,mod-2)%mod+mod)%mod)%mod; } else if(k==3){ minn%=mod; long long n1=n,m1=m; n%=mod,m%=mod; ans=(ans+4*(minn*n%mod*m%mod-(1+minn)*minn%mod*inv[2]%mod*(m+n)%mod+minn*(minn+1)%mod*(2*minn+1)%mod*ksm(6,mod-2)%mod+mod)%mod)%mod; minn=min(m1/2,n1)%mod; ans=(ans+2*(minn*n%mod*m%mod-(1+minn)*minn%mod*inv[2]%mod*(m+2*n)%mod+2*minn%mod*(minn+1)%mod*(2*minn+1)%mod*ksm(6,mod-2)%mod+mod)%mod)%mod; swap(n1,m1); swap(n,m); minn=min(m1/2,n1)%mod; ans=(ans+2*(minn*n%mod*m%mod-(1+minn)*minn%mod*inv[2]%mod*(m+2*n)%mod+2*minn%mod*(minn+1)%mod*(2*minn+1)%mod*ksm(6,mod-2)%mod+mod)%mod)%mod; } printf("%lld ",ans); } return 0; } /* 3 7 7 3 7 6 3 8 9 3 1 5 5 1 */
记一下平方和公式:

差点忘了这个:
朱世杰恒等式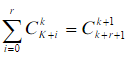
其实它和平方和公式也有点联系