1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
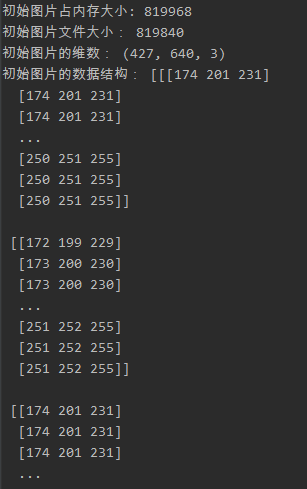
(1)读取一张图片并查看图片的数据结构与大小
from sklearn.datasets import load_sample_image from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np import sys import matplotlib.image as img from pylab import mpl # 读取load_sample_image库的图片 image = load_sample_image("china.jpg") # 读取图片 # image = img.imread("D:/flower.jpg") # 观察图片文件大小,数据结构 print("初始图片占内存大小:",sys.getsizeof(image)) print('初始图片文件大小:', image.size) print("初始图片的维数:",image.shape) print("初始图片的数据结构:",image) # 二维三通道
(2)用kmeans对图片像素颜色进行聚类
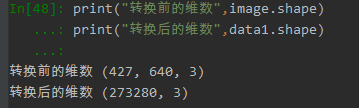
# 将数据线性化 data1 = image.reshape(-1,3) # 重新整理数组转换一维数组,特殊形式,三个值代表一个像素点 print("转换前的维数",image.shape) print("转换后的维数",data1.shape) # 使用用kmeans对图片像素颜色进行聚类压缩 K_colors = 64 # 定义像素的种类数 Km_model = KMeans(K_colors) # k #聚合结果(一维数组) y = Km_model.fit_predict(data1) #找寻类别所对应的颜色(二维数组) colors = Km_model.cluster_centers_ # 压缩结束,将聚类结果还原到画上(一维变二维) print(y.shape,colors.shape) new_image = colors[y].reshape(image.shape) # 还原维数以及像素点
new_image
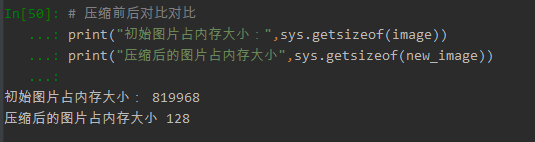
(3)比较压缩前后的大小
# 压缩前后对比对比 print("初始图片占内存大小:",sys.getsizeof(image)) print("压缩后的图片占内存大小",sys.getsizeof(new_image))
(4)比较压缩前后的图片
# 绘图 from pylab import mpl # 解决中文显示问题 mpl.rcParams["font.sans-serif"]=["SimHei"] mpl.rcParams["axes.unicode_minus"]=False plt.figure(figsize=(15,15)) # 定制大小画布 plt.subplot(3,1,1) # 分为三行一列,放在位置1 plt.title("初始的图片") plt.imshow(image) plt.subplot(3,1,2) # 分为三行一列,放在位置2 plt.title("压缩后的图片") plt.imshow(new_image.astype(np.uint8)) # 类型转换,小数点转化为整形 plt.subplot(3,1,3) # 分为三行一列,放在位置3 plt.title("再次压缩图片") plt.imshow(new_image.astype(np.uint8)[::3, ::3]) # 压缩图片进一步压缩,每隔三个像素点选一个像素点出来,::从开始到结束 plt.suptitle("压缩前后对比图") plt.show()

(5)保存图片
# 输出新图片到指定位置 img.imsave('D:/image.jpg', new_image.astype(np.uint8)) # 转换类型后保存

所有代码:
from sklearn.datasets import load_sample_image from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np import sys import matplotlib.image as img from pylab import mpl # 读取load_sample_image库的图片 image = load_sample_image("china.jpg") # 读取图片 # image = img.imread("D:/flower.jpg") # 观察图片文件大小,数据结构 print("初始图片占内存大小:",sys.getsizeof(image)) print('初始图片文件大小:', image.size) print("初始图片的维数:",image.shape) print("初始图片的数据结构:",image) # 二维三通道 # 查看图片 plt.imshow(image) plt.show() # 将数据线性化 data1 = image.reshape(-1,3) # 重新整理数组转换一维数组,特殊形式,三个值代表一个像素点 print("转换前的维数",image.shape) print("转换后的维数",data1.shape) # 使用用kmeans对图片像素颜色进行聚类压缩 K_colors = 64 # 定义像素的种类数 Km_model = KMeans(K_colors) # k #聚合结果(一维数组) y = Km_model.fit_predict(data1) #找寻类别所对应的颜色(二维数组) colors = Km_model.cluster_centers_ # 压缩结束,将聚类结果还原到画上(一维变二维) print(y.shape,colors.shape) new_image = colors[y].reshape(image.shape) # 还原维数以及像素点 new_image = new_image.astype(np.uint8) # 类型转换,小数点转化为整形# 压缩前后对比对比 print("初始图片占内存大小:",sys.getsizeof(image)) print("压缩后的图片占内存大小",sys.getsizeof(new_image)) # 绘图 from pylab import mpl # 解决中文显示问题 mpl.rcParams["font.sans-serif"]=["SimHei"] mpl.rcParams["axes.unicode_minus"]=False plt.figure(figsize=(15,15)) # 定制大小画布 plt.subplot(3,1,1) # 分为三行一列,放在位置1 plt.title("初始的图片") plt.imshow(image) plt.subplot(3,1,2) # 分为三行一列,放在位置2 plt.title("压缩后的图片") plt.imshow(new_image.astype(np.uint8)) # 类型转换,小数点转化为整形 plt.subplot(3,1,3) # 分为三行一列,放在位置3 plt.title("再次压缩图片") plt.imshow(new_image.astype(np.uint8)[::3, ::3]) # 压缩图片进一步压缩,每隔三个像素点选一个像素点出来,::从开始到结束 plt.suptitle("压缩前后对比图") plt.show()
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
(1)用K均值算法对广东省各城市的人口,面积,GDP,GDP的增长速度等数据聚合,给这些城市分成五档
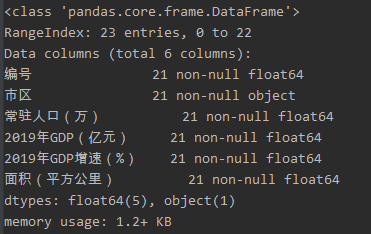
(2)导入数据查看数据类型,并对数据预处理之后调取自己想的数据
import pandas as pd import numpy as np from sklearn.cluster import KMeans import matplotlib.pyplot as plt from pylab import mpl # 解决中文显示问题 mpl.rcParams["font.sans-serif"]=["SimHei"] mpl.rcParams["axes.unicode_minus"]=False # 导入数据 df=pd.read_csv('./venv/data/2019年广东省GDP.csv',encoding='gbk') df.info() len(df) #返回df中各元素是否为空的同df大小的数据框 df.isnull().sum() #删除行中含NaN的值并将其赋值给df1 data=df.dropna(axis=0,how='any') # 转换类型 # data['常驻人口(万)'] = data['常驻人口(万)'].astype(int) # data['2019年GDP(亿元)'] = data['2019年GDP(亿元)'].astype(int) # data['2019年GDP增速(%)'] = data['2019年GDP增速(%)'].astype(int) # data['面积(平方公里)'] = data['面积(平方公里)'].astype(int) # 查看数据类型 data.info() # gdp=np.array(df.iloc[:,2:6].fillna(value=0).astype(int)) #取出df的第三列到第六列转换为数组,并将里面的空值赋值为0去掉,并转换为int类型 # 查看数据长度 len(data) # 取出data数据中的第三到第六列
数据类型:
处理好的数据
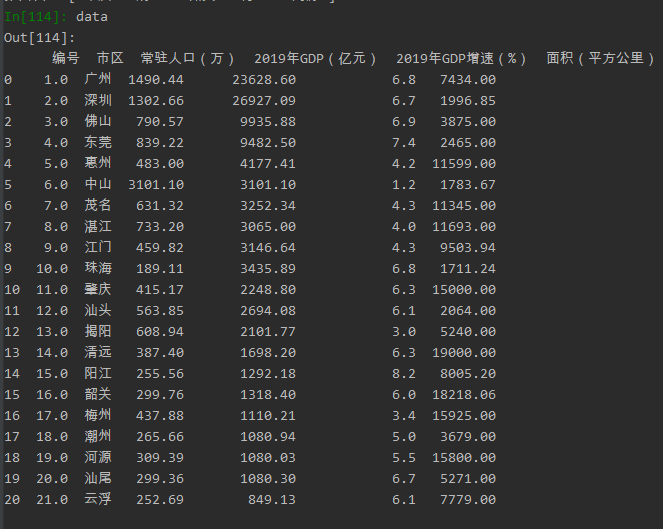
(3)调用kmeans算法训练模型,预测模型:
# 取出data数据中的第三到第六列 gdp=data.iloc[:,2:6] # 直接调用sklearn库的KMeans实现对数据进行聚类分析 km_model = KMeans(n_clusters=5) # 构建模型 分成五个簇 km_model.fit(gdp) # 训练模型 y = km_model.predict(gdp) # 预测模型,预测每个样本的聚类索引 print("聚类中心:", km_model.cluster_centers_ ) print("预测结果:", y) a = np.zeros([5]) # 生成长度为5的全零矩阵 # 从聚类中心中找出类别的gdp for i in range(5): a[i]=km_model.cluster_centers_[i][1] # 查看分组情况 arr = np.array(a) # 给a排序 arr1 = np.argsort(-arr) # 逆序输出索引,从大到小 g0=np.array(data[y== arr1[0]]['市区']) g1=np.array(data[y==arr1[1]]['市区']) g2=np.array(data[y== arr1[2]]['市区']) g3=np.array(data[y== arr1[3]]['市区']) g4=np.array(data[y== arr1[4]]['市区']) print("第一档:",g0) print("第二档:",g1) print("第三档:",g2) print("第四档:",g3) print("第四档:",g4)
预测结果:

(4)画图
# 画图 plt.figure(figsize=(8, 8)) plt.scatter(data.iloc[:,1], data.iloc[:,3], c=y, s=50,cmap='rainbow') plt.xlabel("城市") plt.ylabel("2019年GDP(亿元)") plt.show()

所有代码
import pandas as pd import numpy as np from sklearn.cluster import KMeans import matplotlib.pyplot as plt from pylab import mpl # 解决中文显示问题 mpl.rcParams["font.sans-serif"]=["SimHei"] mpl.rcParams["axes.unicode_minus"]=False # 导入数据 df=pd.read_csv('./venv/data/2019年广东省GDP.csv',encoding='gbk') df.info() len(df) #返回df中各元素是否为空的同df大小的数据框 df.isnull().sum() #删除行中含NaN的值并将其赋值给df1 data=df.dropna(axis=0,how='any') # 转换类型 # data['常驻人口(万)'] = data['常驻人口(万)'].astype(int) # data['2019年GDP(亿元)'] = data['2019年GDP(亿元)'].astype(int) # data['2019年GDP增速(%)'] = data['2019年GDP增速(%)'].astype(int) # data['面积(平方公里)'] = data['面积(平方公里)'].astype(int) # 查看数据类型 data.info() # gdp=np.array(df.iloc[:,2:6].fillna(value=0).astype(int)) #取出df的第三列到第六列转换为数组,并将里面的空值赋值为0去掉,并转换为int类型 # 查看数据长度 len(data) # 取出data数据中的第三到第六列 gdp=data.iloc[:,2:6] # 直接调用sklearn库的KMeans实现对数据进行聚类分析 km_model = KMeans(n_clusters=5) # 构建模型 分成五个簇 km_model.fit(gdp) # 训练模型 y = km_model.predict(gdp) # 预测模型,预测每个样本的聚类索引 print("聚类中心:", km_model.cluster_centers_ ) print("预测结果:", y) a = np.zeros([5]) # 生成长度为5的全零矩阵 # 从聚类中心中找出类别的gdp for i in range(5): a[i]=km_model.cluster_centers_[i][1] # 查看分组情况 arr = np.array(a) # 给a排序 arr1 = np.argsort(-arr) # 逆序输出索引,从大到小 g0=np.array(data[y== arr1[0]]['市区']) g1=np.array(data[y==arr1[1]]['市区']) g2=np.array(data[y== arr1[2]]['市区']) g3=np.array(data[y== arr1[3]]['市区']) g4=np.array(data[y== arr1[4]]['市区']) print("第一档:",g0) print("第二档:",g1) print("第三档:",g2) print("第四档:",g3) print("第四档:",g4) # 画图 plt.figure(figsize=(8, 8)) plt.scatter(data.iloc[:,1], data.iloc[:,3], c=y, s=50,cmap='rainbow') plt.xlabel("城市") plt.ylabel("2019年GDP(亿元)") plt.show()