执法文书打印的实现(二)
基于freemaker技术生成可打印的word文档:
基于FreeMarker生成word.doc文档是一项比较成熟的技术。前承上篇博客(),这个方案只能在windows下部署,不支持linux。这方面的示例网上已经很多了,我也简单上下代码好了(深入的话,我也不了解(汗)。
略过样例测试,首先需要确定word模板。比如: 现场检查笔录.doc ,打开文件,把需要替换的内容加上标记 格式:${插值},并设置好页眉等样式:


其次:将word模板另存为xml 2003,并用xml编辑器打开,这里推荐使用XMLSPY ,这个工具打开xml的显示易于查找和编辑。打开xml,编辑word另存为后插值分开的部分,重新合并(这个在上篇博客已经详细描述,这里就不赘述了)。
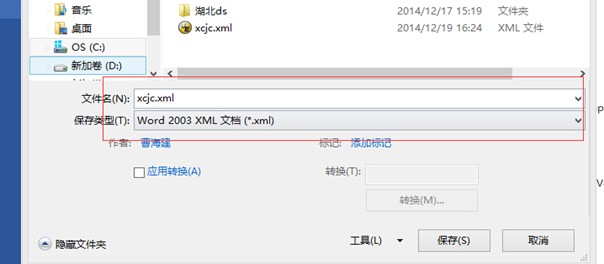
最后把xcjc.xml修改为xcjc.ftl,模板文件也就准备好了,下面就需要添加具体的java代码。
在项目中导入对应的jar包,书写生成word.docx文档的方法:


public String createWord(Map dataMap,String templateName){ String fileName=UUID.randomUUID().toString()+".docx"; try { //创建配置实例 Configuration configuration = new Configuration(Configuration.VERSION_2_3_21); //设置编码 configuration.setDefaultEncoding("UTF-8"); //ftl模板文件统一放至com.sinosoft.zhifa.common.commonPrint.ftlFile.包下面 //configuration.setClassForTemplateLoading(PrintUtil.class,"/com/sinosoft/zhifa/common/commonPrint/ftlFile/"); //这种方法取不到已修改的模板 //设置从文件系统中加载模板 ftlFilePath文件在系统的路径 configuration.setDirectoryForTemplateLoading(new File(ftlFilePath)); //获取模板 Template template = configuration.getTemplate(templateName); //输出文件 File.separator分隔符unix为/ window为\ File outFile = new File(wordFilePath+File.separator+fileName); //如果输出目标文件夹不存在,则创建 if (!outFile.getParentFile().exists()){ outFile.getParentFile().mkdirs(); } //将模板和数据模型合并生成文件 Writer out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile),"UTF-8")); //生成文件 template.process(dataMap, out); //关闭流 out.flush(); out.close(); } catch (Exception e) { e.printStackTrace(); } return fileName; }
其中,dataMap是要替换的数据map,这个map的key是模板的插值,value是具体的数据,而且value不能为null,下面是示例:
Map dataMap=new HashMap(); dataMap.put("被检查单位",(String)scenMap.get("ENT_NAME")==null?" ":(String)scenMap.get("ENT_NAME"));//ENT_NAME 北京恩彼凯化肥厂 dataMap.put("营业执照",(String)scenMap.get("BUSINESS_LICENSE")==null?" ":(String)scenMap.get("BUSINESS_LICENSE"));//BUSINESS_LICENSE 这是我们的营业执照BUSINESS_LICENSE 这是我们的营业执照 dataMap.put("编号",(String)scenMap.get("BUSINESS_LICENSE_ID")==null?" ":(String)scenMap.get("BUSINESS_LICENSE_ID"));//BUSINESS_LICENSE_ID xxxxxxx dataMap.put("组织机构代码",(String)scenMap.get("ORGANIZATION_CODE")==null?" ":(String)scenMap.get("ORGANIZATION_CODE"));//ORGANIZATION_CODE 123123412384组织机构代码 dataMap.put("地址",(String)scenMap.get("ILLEGALACT_ADDRESS")==null?" ":(String)scenMap.get("ILLEGALACT_ADDRESS"));//ILLEGALACT_ADDRESS 北京市朝阳区霄云路 dataMap.put("电话",(String)scenMap.get("ILLEGALACT_PHONE")==null?" ":(String)scenMap.get("ILLEGALACT_PHONE"));//ILLEGALACT_PHONE 13366009185 dataMap.put("法定代表人",(String)scenMap.get("LEGAL_REPRESENTATIVE")==null?" ":(String)scenMap.get("LEGAL_REPRESENTATIVE"));//LEGAL_REPRESENTATIVE 法定负责人 dataMap.put("性别",(String)scenMap.get("GENDER")==null?" ":(String)scenMap.get("GENDER"));//GENDER 男 dataMap.put("职务",(String)scenMap.get("DUTY")==null?" ":(String)scenMap.get("DUTY"));//DUTY 总经理
由于插值{现场检查}是一个富文本,需要图文混排,我在这里是解析数据库的html的标签,根据需要向xcjc.ftl添加插值,并向dataMap中写入对应的key、value:
解析html中的图片并调用修改ftl的方法:
//用图片分割后的富文本
String [] imgs=inspection.split("<img\s+[^>]*/>|<img\s+[^>]*>[^<]*</img>");
//如果有图片,则重新生成ftl文件
XmlUtils xmlutils=new XmlUtils(getRequest());
Map newMap=xmlutils.xmlHandle("xcjc_copy.xml",imgs,pictList);
修改ftl的具体实现:
public Map xmlHandle(String xmlfilepath, String[] imgs, List<String> pictList) { Map<String, String> pictMap = new HashMap<String, String>(); DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); try { DocumentBuilder db = dbf.newDocumentBuilder(); File file = new File(ftlFilePath + fileS + xmlfilepath); document = db.parse(file); NodeList nodelist = document.getElementsByTagName("w:p"); Node baseNode = null;// 基于此节点添加节点信息 Node parentNode = null;// 在此节点下添加节点信息 for (int i = 0; i < nodelist.getLength(); i++) { baseNode = nodelist.item(i); Short eNode = Node.ELEMENT_NODE; // 节点类型是节点,并且节点id:basewp if (eNode.equals(baseNode.getNodeType()) && "basewp".equalsIgnoreCase(((Element) baseNode) .getAttribute("id"))) { parentNode = baseNode.getParentNode(); break; } if (i == nodelist.getLength() - 1) { System.out.println("没有找到指定类型的节点"); return null; } } Map dataMap = new HashMap<String, String>(); int pictNum = 0; // 拼装要插入的xml节点:富文本是图文并排,需要多次插入:解析这个富文本的工作要做,数据库存储的是html,需要的是纯文本+图片 for (int i = 0; i < imgs.length; i++) { if (imgs[i] != null) { String xcjqText = imgs[i].replaceAll("<[^<>]*>|<|>", ""); // 添加文本标签 // 给文本标签模板赋值 Node node = null; node = XmlUtils.getextNode("检查情况文本"+i); parentNode.insertBefore(node, baseNode); pictMap.put("检查情况文本"+i,xcjqText); } if (pictList.size() > pictNum) { // 解析图片:图片宽高 String pictId = null; String pictWidth = null; String pictHeight = null; Pattern pt = Pattern.compile("http:[^"']*");// 图片链接 // http:/i/eg_mouse.jpg?id=xxxxx Matcher m = pt.matcher(pictList.get(pictNum)); while (m.find()) { pictId = m.group().split("=")[1];// 图片UUID } Pattern ptw = Pattern.compile("width(:|=)"?\d*"); Matcher mw = ptw.matcher(pictList.get(pictNum)); while (mw.find()) { pictWidth = mw.group().split("="?|:")[1];// 图片宽度数字部分 } Pattern pth = Pattern.compile("height(:|=)"?\d*"); Matcher mh = pth.matcher(pictList.get(pictNum)); while (mh.find()) { pictHeight = mh.group().split("="?|:")[1];// 图片高度数字部分 } // 请求图片数据转String(数据库或文件系统),请求失败则不添加图片标签,go on // 要返回图片的备用宽度,高度,如果从img标签中取到,则不用这个宽高,否则使用 String pictD[] = this.getBase64PictStr(pictId); if (pictWidth == null) { pictWidth = pictD[0]; pictHeight = pictD[1]; } // 给图片模板赋值 // pt=px乘以3/4。 String pictW = Integer.parseInt(pictWidth) * 3 / 4 + ""; String pictH = Integer.parseInt(pictHeight) * 3 / 4 + ""; String puuid = "现场检查"+pictNum;//UUID.randomUUID().toString() 不能使用uuid其中的字符会被ftl模板错误解析 pictMap.put(puuid, pictD[2]); // 添加图片标签 Node node = null; node = XmlUtils.getPicNode(puuid, pictW, pictH,(pictNum+1+"")); parentNode.insertBefore(node, baseNode); pictNum++; if (i == imgs.length - 1 && pictNum < pictList.size() - 1) { // 继续添加图片 } } } // 利用transformer对象将修改后的文档重新输出 TransformerFactory tFactory = TransformerFactory.newInstance(); Transformer transformer = tFactory.newTransformer(); DOMSource source = new DOMSource(document); // 将xml文档保存为ftl StreamResult result = new StreamResult(new java.io.File(ftlFilePath + File.separator + "xcjc_copy.ftl")); transformer.transform(source, result); } catch (ParserConfigurationException e) { // TODO 自动生成的 catch 块 // e.printStackTrace(); System.out.println("xml配置有错误:ParserConfigurationException"); } catch (SAXException e) { // TODO 自动生成的 catch 块 // e.printStackTrace(); System.out.println("解析文件xml内容失败"); } catch (IOException e) { // TODO 自动生成的 catch 块 // e.printStackTrace(); System.out.println(e + "读取文件失败"); } catch (TransformerConfigurationException e) { // TODO 自动生成的 catch 块 // e.printStackTrace(); System.out.println("转换对象创建失败"); } catch (TransformerException e) { // TODO 自动生成的 catch 块 // e.printStackTrace(); System.out.println("输出文件失败"); } return pictMap; }
在这个实现中,调用了2个私有方法,分别是添加文本节点:getextNode和添加图片节点:getPicNode,其中图片数据必须是base64码的:getBase64PictStr
static Node getPicNode(String PictWordID, String picWidth, String picHeight,String picID) { // 一级节点 // wp 节点及属性 Element wpe = document.createElement("w:p"); wpe.setAttribute("wsp:rsidR", "00172C3B"); wpe.setAttribute("wsp:rsidRDefault", "00B7682D"); wpe.setAttribute("wsp:rsidP", "00172C3B"); // 二级节点 Element wppre = document.createElement("w:pPr"); Element wre = document.createElement("w:r"); wre.setAttribute("wsp:rsidRPr", "00974FA3"); wpe.appendChild(wppre); wpe.appendChild(wre); // 三级节点 Element wwindowcontrole = document.createElement("w:widowControl"); Element wjce = document.createElement("w:jc"); wjce.setAttribute("w:val", "left"); Element wrpre = document.createElement("w:rPr"); Element wrpre2 = document.createElement("w:rPr"); Element wpicte = document.createElement("w:pict"); wppre.appendChild(wwindowcontrole); wppre.appendChild(wjce); wppre.appendChild(wrpre); wre.appendChild(wrpre2); wre.appendChild(wpicte); // 四级节点:处理方式改为顺序 Element wrFontse = document.createElement("w:rFonts"); wrFontse.setAttribute("w:ascii", "宋体"); wrFontse.setAttribute("w:h-ansi", "宋体"); wrFontse.setAttribute("w:cs", "宋体"); wrpre.appendChild(wrFontse); Element wxfonte = document.createElement("wx:font"); wxfonte.setAttribute("wx:val", "宋体"); wrpre.appendChild(wxfonte); Element wkerne = document.createElement("w:kern"); wkerne.setAttribute("w:val", "0"); wrpre.appendChild(wkerne); Element wsze = document.createElement("w:sz"); wsze.setAttribute("w:val", "24"); wrpre.appendChild(wsze); Element wszcse = document.createElement("w:sz-cs"); wszcse.setAttribute("w:val", "24"); wrpre.appendChild(wszcse); Element wnoProof = document.createElement("w:noProof"); wrpre2.appendChild(wnoProof); Element vshapetype = document.createElement("v:shapetype"); vshapetype.setAttribute("id", "_x0000_t75");// //////////////////////v:stroke vshapetype.setAttribute("coordsize", "21600,21600"); vshapetype.setAttribute("o:spt", "75"); vshapetype.setAttribute("o:preferrelative", "t"); vshapetype.setAttribute("path", "m@4@5l@4@11@9@11@9@5xe"); vshapetype.setAttribute("filled", "f"); vshapetype.setAttribute("stroked", "f"); wpicte.appendChild(vshapetype); Element vstroke = document.createElement("v:stroke"); vstroke.setAttribute("joinstyle", "miter"); vshapetype.appendChild(vstroke); Element vformulas = document.createElement("v:formulas"); vshapetype.appendChild(vformulas); Element vf = document.createElement("v:f"); vf.setAttribute("eqn", "if lineDrawn pixelLineWidth 0"); vformulas.appendChild(vf); Element vf2 = document.createElement("v:f"); vf2.setAttribute("eqn", "sum @0 1 0"); vformulas.appendChild(vf2); Element vf3 = document.createElement("v:f"); vf3.setAttribute("eqn", "sum 0 0 @1"); vformulas.appendChild(vf3); Element vf4 = document.createElement("v:f"); vf4.setAttribute("eqn", "prod @2 1 2"); vformulas.appendChild(vf4); Element vf5 = document.createElement("v:f"); vf5.setAttribute("eqn", "prod @3 21600 pixelWidth"); vformulas.appendChild(vf5); Element vf6 = document.createElement("v:f"); vf6.setAttribute("eqn", "prod @3 21600 pixelHeight"); vformulas.appendChild(vf6); Element vf7 = document.createElement("v:f"); vf7.setAttribute("eqn", "sum @0 0 1"); vformulas.appendChild(vf7); Element vf8 = document.createElement("v:f"); vf8.setAttribute("eqn", "prod @6 1 2"); vformulas.appendChild(vf8); Element vf9 = document.createElement("v:f"); vf9.setAttribute("eqn", "prod @7 21600 pixelWidth"); vformulas.appendChild(vf9); Element vf10 = document.createElement("v:f"); vf10.setAttribute("eqn", "sum @8 21600 0"); vformulas.appendChild(vf10); Element vf11 = document.createElement("v:f"); vf11.setAttribute("eqn", "prod @7 21600 pixelHeight"); vformulas.appendChild(vf11); Element vf12 = document.createElement("v:f"); vf12.setAttribute("eqn", "sum @10 21600 0"); vformulas.appendChild(vf12); Element vpath = document.createElement("v:path"); vpath.setAttribute("o:extrusionok", "f"); vpath.setAttribute("gradientshapeok", "t"); vpath.setAttribute("o:connecttype", "rect"); vshapetype.appendChild(vpath); Element olock = document.createElement("o:lock"); olock.setAttribute("v:ext", "edit"); olock.setAttribute("aspectratio", "t"); vshapetype.appendChild(olock); Element wbinData = document.createElement("w:binData"); wbinData.setAttribute("w:name", "wordml://0300000"+picID+".png");//修改图片的src和w:name解决只加载第一张图片的问题 wbinData.setAttribute("xml:space", "preserve"); wpicte.appendChild(wbinData); Text pictText = document.createTextNode("${" + PictWordID + "}");// 这儿可以添加图片定位参数 wbinData.appendChild(pictText); Element vshape = document.createElement("v:shape");// 指定图片id和宽高 vshape.setAttribute("id", PictWordID);//图片id需要动态传值,多个图片现在只加载同一个 vshape.setAttribute("o:spid", "_x0000_i1028"); vshape.setAttribute("type", "#_x0000_t75");// picWidth // vshape.setAttribute("style","358.4pt;height:535.7pt;visibility:visible;mso-wrap-style:square"); vshape.setAttribute("style", "" + picWidth + "pt;height:" + picHeight + "pt;visibility:visible;mso-wrap-style:square"); Element vimagedata = document.createElement("v:imagedata"); vimagedata.setAttribute("src", "wordml://0300000"+picID+".png"); vimagedata.setAttribute("o:title", ""); vshape.appendChild(vimagedata); wpicte.appendChild(vshape); return wpe; }
static Node getextNode(String wordtext1) { // 一级节点 // wp 节点及属性 Element wpe = document.createElement("w:p"); wpe.setAttribute("wsp:rsidP", "008027B0"); wpe.setAttribute("wsp:rsidR", "008027B0"); wpe.setAttribute("wsp:rsidRDefault", "008027B0"); wpe.setAttribute("wsp:rsidRPr", "006B689C"); // 二级节点及属性 Element wpPr = document.createElement("w:pPr"); Element wr = document.createElement("w:r"); wr.setAttribute("wsp:rsidRPr", "006B689C"); wpe.appendChild(wpPr); wpe.appendChild(wr); // 三级节点 顺序添加 //wppr节点及子节点 Element wspacing = document.createElement("w:spacing"); wspacing.setAttribute("w:line", "500"); wspacing.setAttribute("w:line-rule", "exact"); wpPr.appendChild(wspacing); Element wrPr = document.createElement("w:rPr"); wpPr.appendChild(wrPr); Element wrFonts = document.createElement("w:rFonts"); wrFonts.setAttribute("w:ascii", "仿宋_GB2312"); wrFonts.setAttribute("w:cs", "仿宋_GB2312"); wrPr.appendChild(wrFonts); Element wxfont = document.createElement("wx:font"); wxfont.setAttribute("wx:val", "仿宋_GB2312"); wrPr.appendChild(wxfont); Element wu = document.createElement("w:u");//和下面的代码一起控制文字下面是否有下划线 wu.setAttribute("w:val", "single");//这里设置下划线为单线 wrPr.appendChild(wu); //wr节点及子节点 Element wrPr1 = document.createElement("w:rPr"); wr.appendChild(wrPr1); Element wrFonts1 = document.createElement("w:rFonts"); wrFonts1.setAttribute("w:ascii", "仿宋_GB2312"); wrFonts1.setAttribute("w:cs", "仿宋_GB2312"); wrPr1.appendChild(wrFonts1); Element wxfont1 = document.createElement("wx:font"); wxfont1.setAttribute("wx:val", "仿宋_GB2312"); wrPr1.appendChild(wxfont1); Element wu1 = document.createElement("w:u");//和下面的代码一起控制文字下面是否有下划线 wu1.setAttribute("w:val", "single");//这里设置下划线为单线 wrPr1.appendChild(wu1); Element wt = document.createElement("w:t");//创建要插入文本的节点 Text wordtext=document.createTextNode("${" + wordtext1 + "}");//要插入文本的标记 wt.appendChild(wordtext); wr.appendChild(wt); return wpe; }
public String[] getBase64PictStr(String pictID) { byte[] data = null; String[] wh = new String[3]; Connection conn; Statement stmt = null; PreparedStatement ps = null; ResultSet rs = null; // 这个sql应该是动态获取的 String sql = "select image from picc where id='"+pictID+"'";//2e30826eba714a909758c2bfff8f4875 DataSource dataSource = DataSourceFactory.defaultFactory .getDataSource("dataSource"); try { conn = dataSource.getConnection(); stmt = conn.createStatement(); rs = stmt.executeQuery(sql); if (rs.next()) { Blob blob = rs.getBlob("image");// IMAGE data = blob.getBytes(1, (int) blob.length()); BufferedImage bis = ImageIO .read(new ByteArrayInputStream(data)); int wid = bis.getWidth(); wh[0] = wid + ""; int hei = bis.getHeight(); wh[1] = hei + ""; BASE64Encoder encoder = new BASE64Encoder(); String str = encoder.encode(data); wh[2] = str;// 编码后的图片字符串 // System.out.println(str); } } catch (SQLException e1) { e1.printStackTrace(); System.out.println("创建数据库连接失败"); } catch (IOException e) { System.out.println("转换图片失败"); // e.printStackTrace(); } return wh; }
下一篇博客要写下word转pdf/png的方法,jodconver这个jar包用过2个版本,3.0的很不成熟,不推荐。这个方法生成word现在没有在项目中使用,有问题互相探讨。