引言
之前我读了ResNet的论文Deep Residual Learning for Image Recognition,也做了论文笔记,笔记里记录了ResNet的理论基础(核心思想、基本Block结构、Bottleneck结构、ResNet多个版本的大致结构等等),看本文之间可以先看看打打理论基础。
一个下午的时间,我用PPT纯手工做了一张图片详细说明ResNet50的具体结构,本文将结合该图片详细介绍ResNet50。
这张图和这篇文章估计全网最详细了(狗头)。
废话不多说,先放图片(文末有图片和PPT源文件的下载链接)。
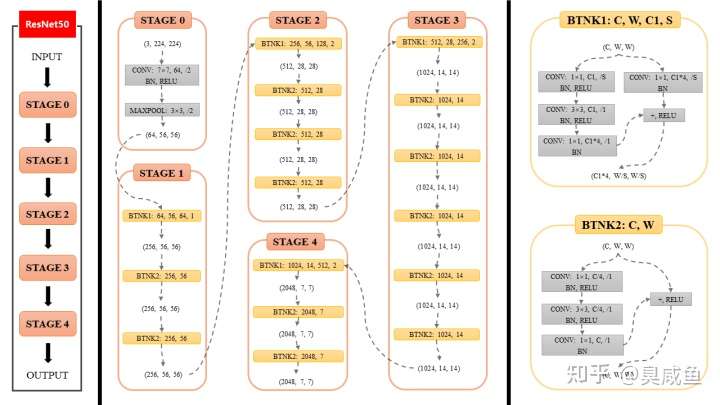
上图(称为本图)可划分为左、中、右3个部分,三者内容分别如下
- ResNet50整体结构
- ResNet50各个Stage具体结构
- Bottleneck具体结构
接下来为正文内容,本文先后介绍了本图从左到右的3个部分,并对Bottleneck进行了简要分析。
ResNet50整体结构
首先需要声明,这张图的内容是ResNet的Backbone部分(即图中没有ResNet中的全局平均池化层和全连接层)。
如本图所示,输入INPUT经过ResNet50的5个阶段(Stage 0、Stage 1、……)得到输出OUTPUT。
下面附上ResNet原文展示的ResNet结构,大家可以结合着看,看不懂也没关系,只看本文也可以无痛理解的。
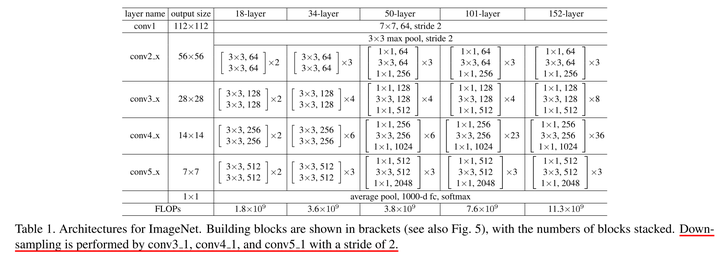
上图描述了ResNet多个版本的具体结构,本文描述的“ResNet50”中的50指有50个层。和上图一样,本图描述的ResNet也分为5个阶段。
ResNet各个Stage具体结构
如本图所示,ResNet分为5个stage(阶段),其中Stage 0的结构比较简单,可以视其为对INPUT的预处理,后4个Stage都由Bottleneck组成,结构较为相似。Stage 1包含3个Bottleneck,剩下的3个stage分别包括4、6、3个Bottleneck。
现在对Stage 0和Stage 1进行详细描述,同理就可以理解后3个Stage。
Stage 0
-
(3,224,224)指输入INPUT的通道数(channel)、高(height)和宽(width),即(C,H,W)。现假设输入的高度和宽度相等,所以用(C,W,W)表示。 -
该stage中第1层包括3个先后操作
-
CONVCONV是卷积(Convolution)的缩写,7×7指卷积核大小,64指卷积核的数量(即该卷积层输出的通道数),/2指卷积核的步长为2。 -
BNBN是Batch Normalization的缩写,即常说的BN层。 -
RELURELU指ReLU激活函数。
-
-
该stage中第2层为
MAXPOOL,即最大池化层,其kernel大小为3×3、步长为2。 -
(64,56,56)是该stage输出的通道数(channel)、高(height)和宽(width),其中64等于该stage第1层卷积层中卷积核的数量,56等于224/2/2(步长为2会使输入尺寸减半)。
总体来讲,在Stage 0中,形状为(3,224,224)的输入先后经过卷积层、BN层、ReLU激活函数、MaxPooling层得到了形状为(64,56,56)的输出。
Stage 1
在理解了Stage 0以及熟悉图中各种符号的含义之后,可以很容易地理解Stage 1。理解了Stage 1之后,剩下的3个stage就不用我讲啦,你自己就能看懂。
Stage 1的输入的形状为(64,56,56),输出的形状为(64,56,56)。
下面介绍Bottleneck的具体结构(难点),把Bottleneck搞懂后,你就懂Stage 1了。
Bottleneck具体结构
现在让我们把目光放在本图最右侧,最右侧介绍了2种Bottleneck的结构。
“BTNK”是BottleNeck的缩写(本文自创,请谨慎使用)。
2种Bottleneck分别对应了2种情况:输入与输出通道数相同(BTNK2)、输入与输出通道数不同(BTNK1),这一点可以结合ResNet原文去看喔。
BTNK2
我们首先来讲BTNK2。
BTNK2有2个可变的参数C和W,即输入的形状(C,W,W)中的c和W。
令形状为(C,W,W)的输入为(x),令BTNK2左侧的3个卷积块(以及相关BN和RELU)为函数(F(x)),两者相加((F(x)+x))后再经过1个ReLU激活函数,就得到了BTNK2的输出,该输出的形状仍为(C,W,W),即上文所说的BTNK2对应输入(x)与输出(F(x))通道数相同的情况。
BTNK1
BTNK1有4个可变的参数C、W、C1和S。
与BTNK2相比,BTNK1多了1个右侧的卷积层,令其为函数(G(x))。BTNK1对应了输入(x)与输出(F(x))通道数不同的情况,也正是这个添加的卷积层将(x)变为(G(x)),起到匹配输入与输出维度差异的作用(使得(G(x))和(F(x))通道数相同),进而可以进行求和(F(x)+G(x))。
简要分析
可知,ResNet后4个stage中都有BTNK1和BTNK2。
-
4个stage中
BTNK2参数规律相同4个stage中
BTNK2的参数全都是1个模式和规律,只是输入的形状(C,W,W)不同。 -
Stage 1中
BTNK1参数的规律与后3个stage不同然而,4个stage中
BTNK1的参数的模式并非全都一样。具体来讲,后3个stage中BTNK1的参数模式一致,Stage 1中BTNK1的模式与后3个stage的不一样,这表现在以下2个方面:-
参数
S:BTNK1左右两个1×1卷积层是否下采样Stage 1中的
BTNK1:步长S为1,没有进行下采样,输入尺寸和输出尺寸相等。后3个stage的
BTNK1:步长S为2,进行了下采样,输入尺寸是输出尺寸的2倍。 -
参数
C和C1:BTNK1左侧第一个1×1卷积层是否减少通道数Stage 1中的
BTNK1:输入通道数C和左侧1×1卷积层通道数C1相等(C=C1=64),即左侧1×1卷积层没有减少通道数。后3个stage的
BTNK1:输入通道数C和左侧1×1卷积层通道数C1不相等(C=2*C1),左侧1×1卷积层有减少通道数。
-
-
为什么Stage 1中
BTNK1参数的规律与后3个stage不同?(个人观点)-
关于
BTNK1左右两个1×1卷积层是否下采样因为Stage 0中刚刚对网络输入进行了卷积和最大池化,还没有进行残差学习,此时直接下采样会损失大量信息;而后3个stage直接进行下采样时,前面的网络已经进行过残差学习了,所以可以直接进行下采样。
-
关于
BTNK1左侧第一个1×1卷积层是否减少通道数根据ResNet原文可知,Bottleneck左侧两个1×1卷积层的主要作用分别是减少通道数和恢复通道数,这样就可以使它们中间的3×3卷积层的输入和输出的通道数都较小,因此效率更高。
Stage 1中
BTNK1的输入通道数C为64,它本来就比较小,因此没有必要通过左侧第一个1×1卷积层减少通道数。
-
福利

扫码关注微信公众号后回复resnet即可直接获取图片和PPT源文件的下载链接。
参考链接
https://www.bilibili.com/read/cv2051292
https://arxiv.org/abs/1512.03385
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!