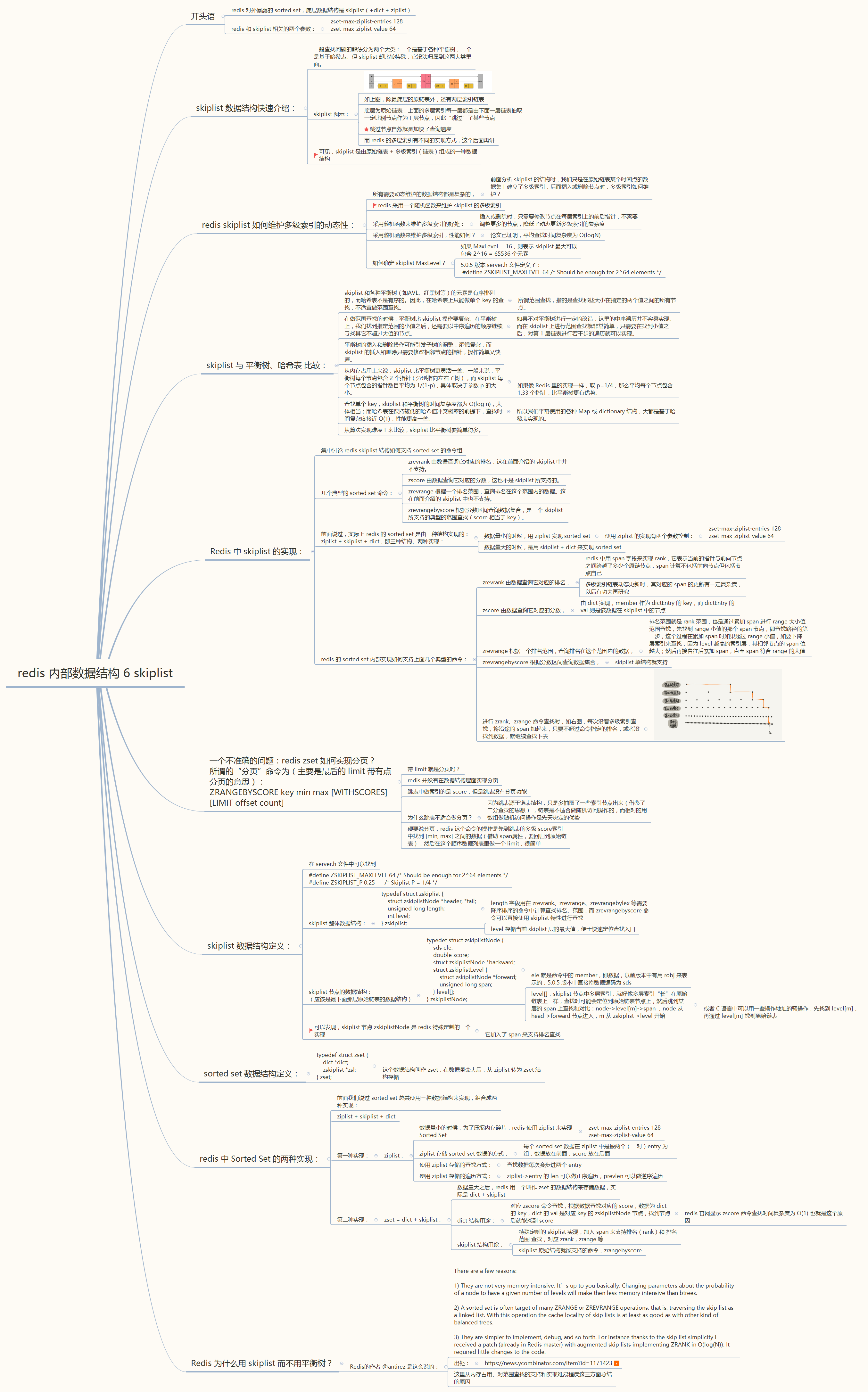
这是《redis 七种内部数据结构》:https://www.cnblogs.com/christmad/p/11364372.html 的第六篇
20200810更新:跳表与B+树的一些联系
对于“按区间查找数据”操作,跳表可以做到 O(logN) 时间复杂度定位到范围的起点,然后继续往后遍历就可以了。
这种实现“区间查询”的方式很像另外一个数据结构——B+树。
B+树的数据是按照主键值升序排列的,当我们需要按照 N<PrimaryKey<M 这样的区间查找某些数据时,B+树算法会先去找到最符合上述区间的 N`<PrimaryKey<M`,并且拿着 N` 和 M` 所指的地址到原始链表(B+树也有这样一条链表)取出数据,此时取数据就是磁盘 IO 操作了(可能有缓存过),不过因为这些数据都是紧挨在一起(连续)的,所以 IO 操作是连续读,比较快。
2019-11-27 更新,已加到图中:
Q:一个不准确的问题:redis zset 如何实现分页?
所谓的“分页”命令为(主要是最后的 limit 带有点分页的意思):
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
A:
a) 命令带 limit 底层数据结构就要按可分页的数据结构来给你实现吗?
——redis 并没有在数据结构层面实现分页
b) 跳表中做索引的是 score,但是跳表没有分页功能
c) 为什么跳表不适合做分页?
——因为跳表源于链表结构,只是多抽取了一些索引节点出来(借鉴了二分查找的思想),但链表还是不适合做随机访问操作,而相对的用数组做随机访问操作是先天决定的优势
d) 硬要说分页,redis 这个命令的操作是先到跳表的多级 score索引中找到 [min, max] 之间的数据(借助 span属性,要回归到原始链表),然后在这个顺序数据列表里做一个 limit,很简单
--------------------------------------------
redis sorted set 笔记 end