如何安装
由于是在MAC OS 下面,所以跟着官网的教程,直接copy5行代码搞定
$ cd /usr/local/lib
$ sudo curl -O http://www.antlr.org/download/antlr-4.7-complete.jar
$ export CLASSPATH=".:/usr/local/lib/antlr-4.7-complete.jar:$CLASSPATH"
$ alias antlr4='java -jar /usr/local/lib/antlr-4.7-complete.jar'
$ alias grun='java org.antlr.v4.gui.TestRig'
但是经历多了,就会发现
vi ~/.bash_profile
把与环境相关的内容都copy进来,这样的话重启计算机后仍能生效
[esc]
:wq
保存退出
source ~/.bash_profile
更新环境变量。
好了,现在就可以进行初步的操作了。
grun
这个命令的基本格式为
grun xxx.g4 __garmmar_begin [参数] [资源文件]+
其中xxx.g4为语法文件
__garmmar_begin 为语法开始内容
首先列出一些比较重要的参数:
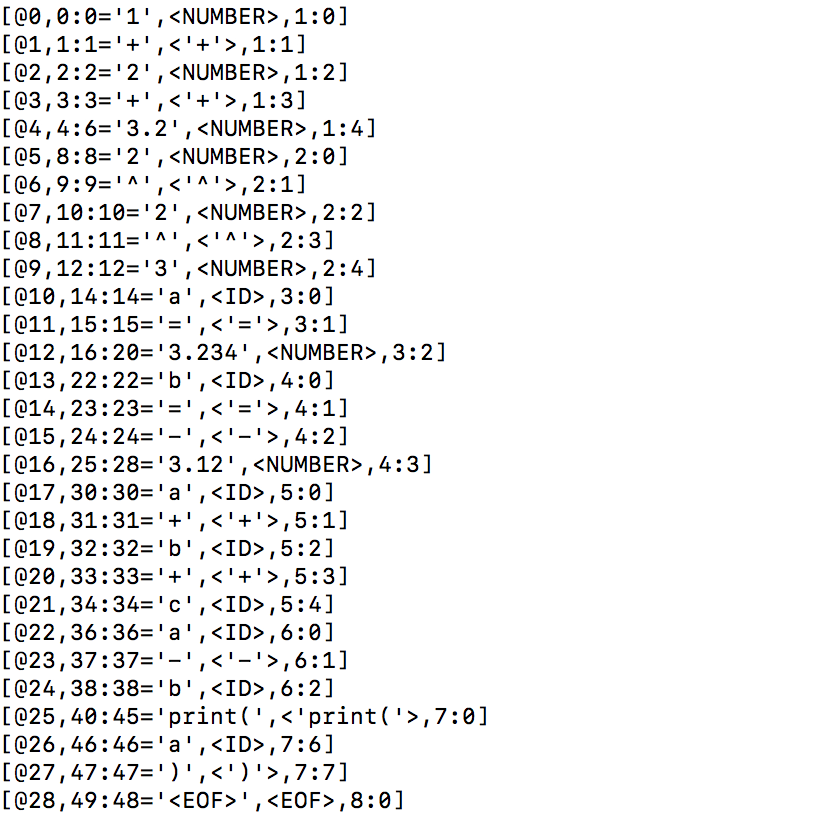
- -tokens 打印出记号流
- -tree 以LISP风格的文本形式打印出语法分析树
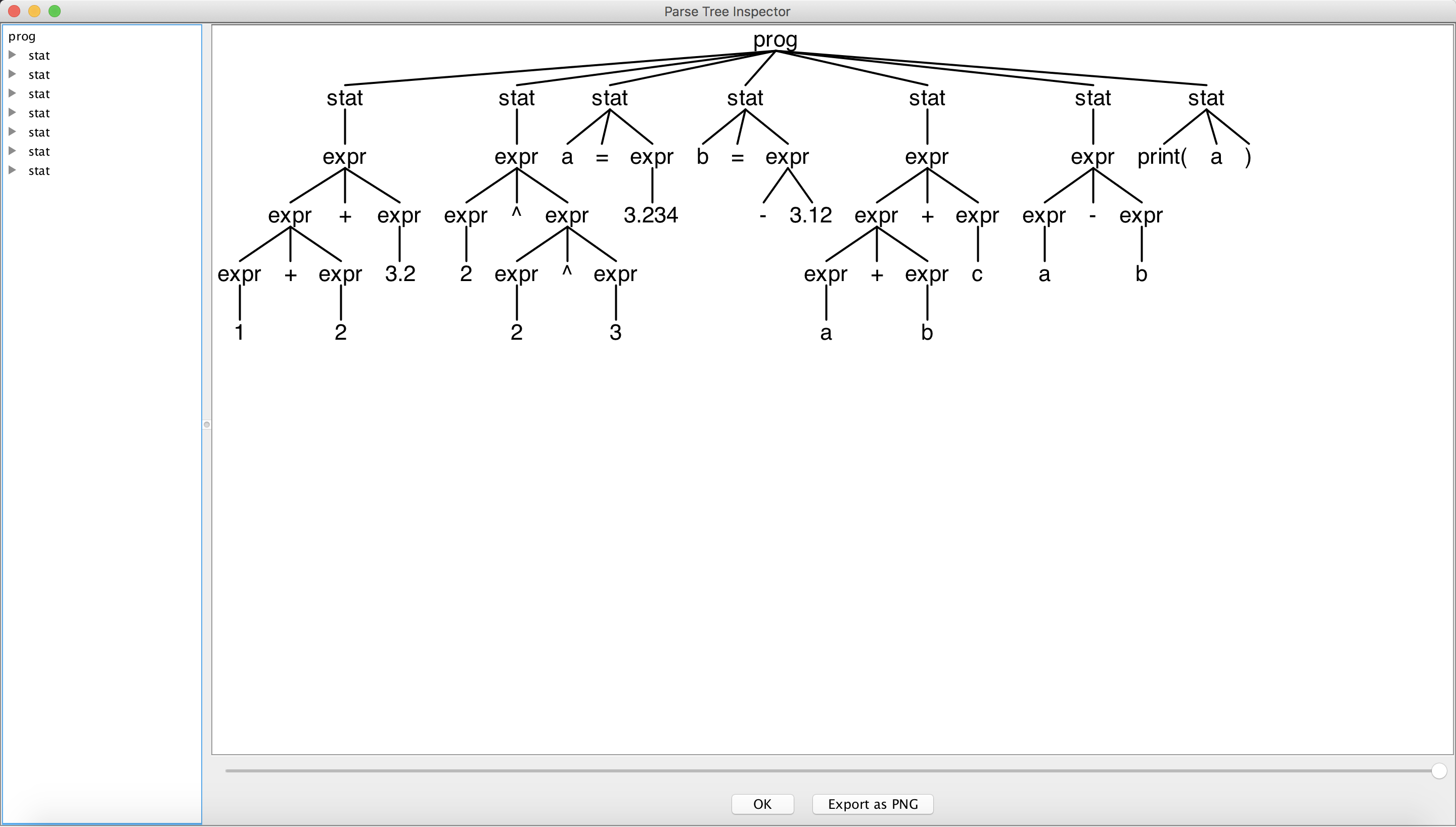
- -gui 在对话框中可视化地显示出语法分析树。
- -ps file.ps 在PostScript中生成一个可视化的语法分析树表示,并把它存储在file.ps文件中
- -encoding _name 指定输入文件编码
- -trace 在进入/退出规则前打印规则名称和当前记号
- -diagnostics分析时打开诊断信息。此生成消息仅用于异常情况,如二义性
- -SLL使用更快但稍弱的分析策略
-tokens
-tree

-gui
-ps
这个功能就我发现双击这个ps文件后会出一个pdf文件。
其他参数由于暂时涉及不到,就暂时没有尝试。
二义性
在处理二义性方面的问题时。ANTLR通过选择涉及决定的第一个选项来解决二义性。
并且在面对下面的问题时,会“智能地选择合理结果”
BEGIN : 'begin';
ID : [a-zA-Z]+;
在遇到begin时,会用第一个规则进行匹配,如果遇到了类似beging、abegin这样的都会用第二个规则进行匹配。
Visitor和Listener
ANTLR在它的运行库中为两种树遍历机制提供支持。默认下ANTLR生成语法分析树和Listener接口,并在其中定义了回调方法,用于响应被内建的树遍历器的触发。
在Listener和Visitor机制之间最大的不同是:Listener方法被ANTLR提供的遍历器对象调用; 而Visitor方法必须显式的调用visit方法遍历它们的子节点,在一个节点的子节点上如果忘记调 用visit方法就意味着那些子树没有得到访问。
在这次学习中,是用Visitor实现了一个计算器。首先上计算器的语法:
grammar Calc;
prog : stat+;
stat : expr # printExpr
| ID '=' expr # assign
| 'print(' ID ')' # print
;
expr : <assoc=right> expr '^' expr # power
| expr op=(MUL|DIV) expr # MulDiv
| expr op=(ADD|SUB) expr # AddSub
| sign=(ADD|SUB)?NUMBER # number
| ID # id
| '(' expr ')' # parens
;
ID : [a-zA-Z]+;
NUMBER : [0-9]+('.'([0-9]+)?)?
| [0-9]+;
COMMENT : '/*' .*? '*/' -> skip;
LINE_COMMENT : '//' .*? '
'? '
' -> skip;
WS : [
]+ -> skip;
MUL : '*';
DIV : '/';
ADD : '+';
SUB : '-';
我觉得在这个文法中有一些细节值得强调,一个是运算符的优先级,第二个是 #号后面的东西有什么用,最后就是<assoc=right>这个东西。
运算符优先级类如加减乘除这些基本法则在Antlr中已经自动帮你处理,就参考我上面写的expr,有时候并不意味着你这样写
....
| expr op=(MUL|DIV) expr
| expr op=(ADD|SUB) expr
....
就可以让乘除先于加减,它与怎样排列无关。
但是,Antlr会把我们的目标脚本,解析生一棵抽象语法树,越是靠近叶子节点的地方,结合优先级越高,越是靠近根节点的地方,结合优先级越低。
在就上面的expr来谈,
...
| ID
| '(' expr ')'
...
他们的优先级要高于加减乘除运算
#号有什么用呢?
在Visitor模式中,它会给你生成一些visit方法,方便你的编程。
<assoc=right>有什么用呢?
在默认情况下,Antlr是默认从左向右结合运算符,然而像指数群这样的运算符则是要从右向左,因此我们必须使用assoc手动指定运算符,这样就能把2^3^4解释成2^(3^4)。
下面上一下自己写的EvalVisitor类。
import java.text.DecimalFormat;
import java.util.HashMap;
import java.util.Map;
public class EvalVisitor extends CalcBaseVisitor<Double> {
Map<String, Double> memory = new HashMap<String, Double>();
//id = expr
@Override
public Double visitAssign(CalcParser.AssignContext ctx){
String id = ctx.ID().getText();
Double value = visit(ctx.expr());
memory.put(id, value);
return value;
}
// expr
@Override
public Double visitPrintExpr(CalcParser.PrintExprContext ctx) {
Double value = visit(ctx.expr());
//保留两位有数字的方法
DecimalFormat df = new DecimalFormat("#.##");
String s_value = df.format(value);
System.out.println(s_value);
return 0.0;
}
//print
@Override
public Double visitPrint(CalcParser.PrintContext ctx){
String id = ctx.ID().getText();
Double value=0.0;
if(memory.containsKey(id)) value = memory.get(id);
DecimalFormat df = new DecimalFormat("#.##");
String s_value = df.format(value);
System.out.println(s_value);
return value;
}
//Number
@Override
public Double visitNumber(CalcParser.NumberContext ctx){
int size = ctx.getChildCount();
if(size == 2){
if(ctx.sign.getType() == CalcParser.SUB){
return -1 * Double.valueOf(ctx.getChild(1).getText());
}else{
return Double.valueOf(ctx.getChild(1).getText());
}
}else{
return Double.valueOf(ctx.getChild(0).getText());
}
}
//ID
@Override
public Double visitId(CalcParser.IdContext ctx){
String id = ctx.ID().getText();
if(memory.containsKey(id)) return memory.get(id);
return 0.0;
}
//expr op=('*'|'/') expr
@Override
public Double visitMulDiv(CalcParser.MulDivContext ctx) {
Double left = visit(ctx.expr(0));
Double right = visit(ctx.expr(1));
if(ctx.op.getType() == CalcParser.MUL){
return left * right;
}else{
if(right == 0 || right == 0.0){
System.out.println("Divisor can not be zero");
return 0.0;
}else{
return left / right;
}
}
}
//expr op=('+'|'-') expr
@Override
public Double visitAddSub(CalcParser.AddSubContext ctx){
Double left = visit(ctx.expr(0));
Double right = visit(ctx.expr(1));
if(ctx.op.getType() == CalcParser.ADD)
return left + right;
return left - right;
}
// '(' expr ')'
@Override
public Double visitParens(CalcParser.ParensContext ctx){
return visit(ctx.expr());
}
// '^'
@Override
public Double visitPower(CalcParser.PowerContext ctx){
Double base = visit(ctx.expr(0));
Double exponet = visit(ctx.expr(1));
return Math.pow(base, exponet);
}
}
还有Calc.java类,为开始类
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
import java.io.InputStream;
public class Calc {
public static void main(String[] args) throws Exception {
CharStream input;
if(args.length == 1) {
String fileName = String.valueOf(args[0]);
input = CharStreams.fromFileName(fileName);
}else if(args.length > 1 || args.length < 0){
throw new Exception("the number of arguments is false, Please only give the source file or nothing and then you input your text");
}else {
InputStream is = System.in;
input = CharStreams.fromStream(is);
}
CalcLexer lexer = new CalcLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CalcParser parser = new CalcParser(tokens);
ParseTree tree = parser.prog();
EvalVisitor eval = new EvalVisitor();
eval.visit(tree);
System.out.println(tree.toStringTree(parser));
}
}
最后通过下面的命令便可以运行
antlr4 -no-listener -visitor Calc.g4
javac *.java
java Calc 或 java Calc calc.txt
grun Calc prog -gui calc.txt #可看生成树
具体代码及相关学习书籍在这摸我