1.分析器 所有分析器最终继承的类都是Analyzer
1.1 默认标准分析器:StandardAnalyzer
在我们创建索引的时候,我们使用到了IndexWriterConfig对象,在我们创建索引的过程当中,会经历分析文档的步骤,就是分词的步骤,默认采用的标准分析器自动分词
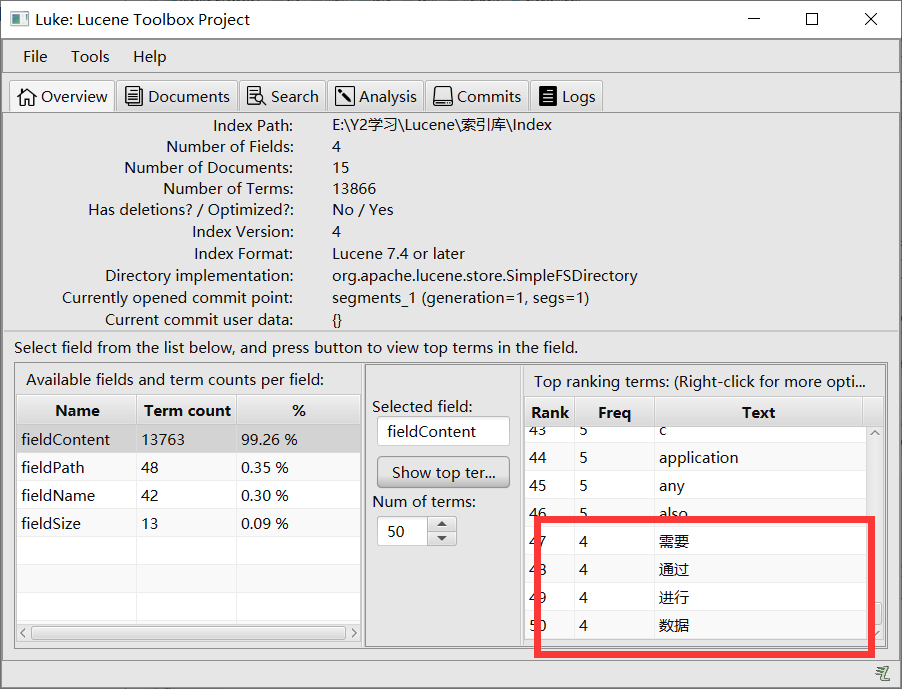
1.1.1 查看分析器的分析效果
public static void main(String[] args) throws IOException { //1.创建一个Analyzer对象 StandardAnalyzer analyzer = new StandardAnalyzer(); //2.调用Analyzer对象的tokenStream方法获取TokenStream对象,此对象包含了所有的分词结果 TokenStream tokenStream = analyzer.tokenStream("", "安装mysql-5.7.22-winx64后数据库服务启动报错:本地计算机上的mysql服务启动停止后,某些服务未由其他服务或程序使用时将自动停止而且mysql官网下载的压缩包解压出来没有网线上安装教... 博文 来自: 测试菜鸟在路上,呵呵"); //3.给tokenStream对象设置一个指针,指针在哪当前就在哪一个分词上 CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); //4.调用tokenStream对象的reset方法,重置指针,不调用会报错 tokenStream.reset(); //5.利用while循环,拿到分词列表的结果 incrementToken方法返回值如果为false代表读取完毕 true代表没有读取完毕 while (tokenStream.incrementToken()){ System.out.println(charTermAttribute.toString()); } //6.关闭 tokenStream.close(); }
分析会去掉停用词,忽略大小写,祛除标点
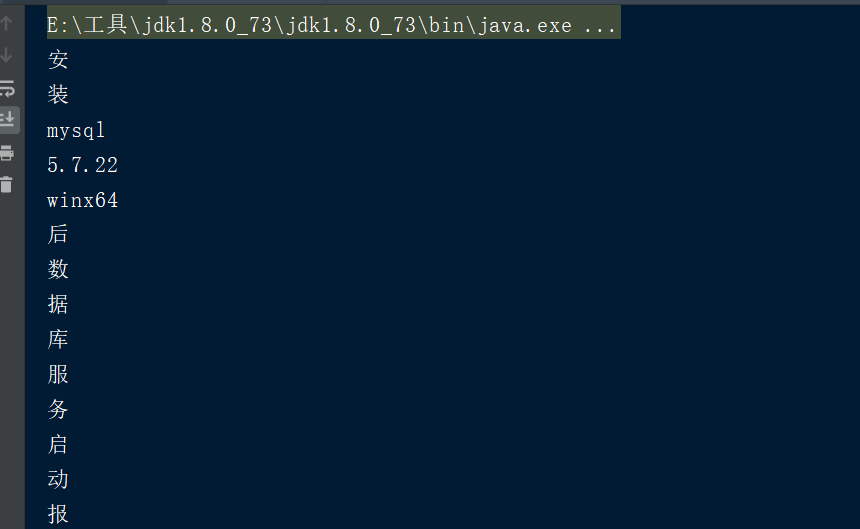
默认标准分析器分析英文没有问题,但是他分析中文时会拆分成单个汉字,这显然不符合实际需求
1.2 中文分析器
第三方中文分析器:IKAnalyzer
IKAnalyzer的使用步骤:
1.导入依赖
<!-- https://mvnrepository.com/artifact/com.jianggujin/IKAnalyzer-lucene --> <dependency> <groupId>com.jianggujin</groupId> <artifactId>IKAnalyzer-lucene</artifactId> <version>8.0.0</version> </dependency>
2.配置IKAnalyzer,导入配置文件
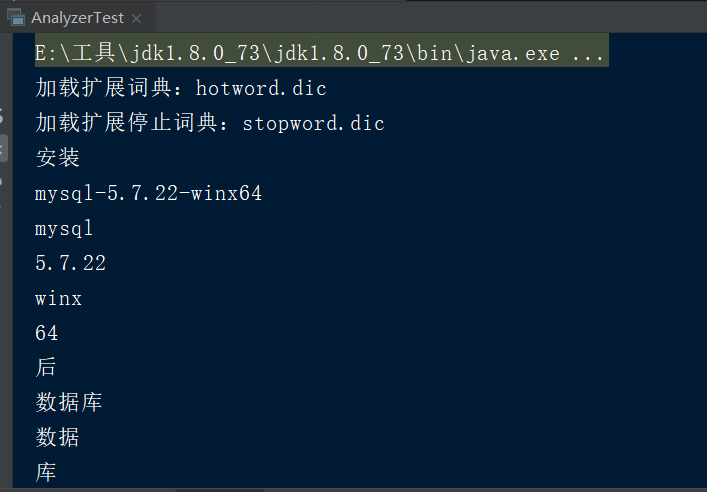
hotword.dic 扩展词典,可以将时尚的网络名词放入到该词典当中,这样就能根据扩展词典进行分词
stopword.dic 停用词词典,可以将无意义的词和敏感词汇放入到该词典当中,这样在分析的时候就会忽略这些内容
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">hotword.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典 词典可以有多个,每一个用;分割--> <entry key="ext_stopwords">stopword.dic;</entry> </properties>
在自定义扩展词典和停用词词典的过程当中,千万不要使用windows记事本编辑,因为windows记事本是UTF-8+BOM编码
3.使用IKAnalyzer进行分词
public static void main(String[] args) throws IOException { //1.创建一个Analyzer对象 Analyzer analyzer=new IKAnalyzer(); //2.调用Analyzer对象的tokenStream方法获取TokenStream对象,此对象包含了所有的分词结果 TokenStream tokenStream = analyzer.tokenStream("", "安装mysql-5.7.22-winx64后数据库服务启动报错:本地计算机上的mysql服务启动停止后,某些服务未由其他服务或程序使用时将自动停止而且mysql官网下载的压缩包解压出来没有网线上安装教... 博文 来自: 测试菜鸟在路上,呵呵"); //3.给tokenStream对象设置一个指针,指针在哪当前就在哪一个分词上 CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); //4.调用tokenStream对象的reset方法,重置指针,不调用会报错 tokenStream.reset(); //5.利用while循环,拿到分词列表的结果 incrementToken方法返回值如果为false代表读取完毕 true代表没有读取完毕 while (tokenStream.incrementToken()){ System.out.println(charTermAttribute.toString()); } //6.关闭 tokenStream.close(); }
得到的就是常用的单词了
4.程序当中使用IKAnalyzer
IndexWriter indexWriter=new IndexWriter(directory,new IndexWriterConfig(new IKAnalyzer()));